다중 에이전트 시스템, 메모리 조직 검색, 그리고 3D 객체 재구성의 혁신적 발전
Intern-S1: A Scientific Multimodal Foundation Model
https://arxiv.org/abs/2508.15763
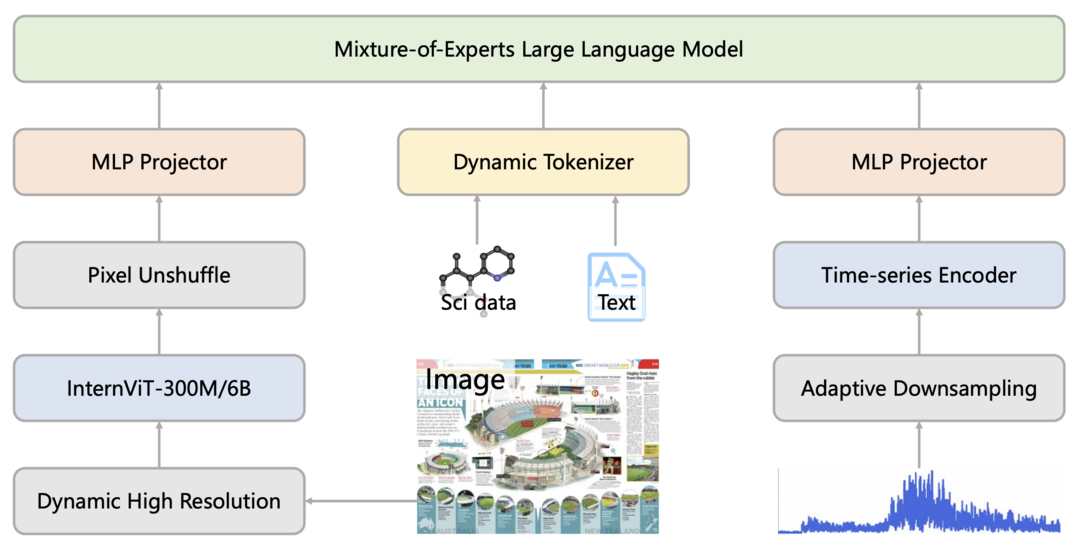
Intern-S1은 과학 분야에 특화된 다중 모달 기초 모델로, 28B 활성화 매개변수와 241B 총 매개변수를 가진 MoE 구조를 채택했다. 5T 토큰(2.5T 과학 도메인 토큰 포함)으로 사전 학습한 후 1000개 이상의 작업에 대한 강화학습을 진행했으며, Mixture-of-Rewards 기법을 통해 다양한 작업에 대한 훈련 시너지 효과를 창출했다. 이 모델은 일반 추론 작업에서 오픈소스 모델 중 경쟁력 있는 성능을 보이며, 특히 분자 합성 계획, 반응 조건 예측 등 과학 도메인에서 클로즈드 소스 SOTA 모델을 능가하는 성능을 달성했다.
DINOv3
https://arxiv.org/abs/2508.10104
DINOv3는 자기지도학습 기반 비전 파운데이션 모델로, 데이터 및 모델 크기 확장의 이점을 활용한 세심한 데이터 준비 및 최적화를 특징으로 한다. 이 모델은 "Gram anchoring" 기법을 도입하여 긴 훈련 일정 동안 밀집 특징 맵 품질 저하 문제를 해결했으며, 해상도, 모델 크기, 텍스트 정렬 관련 사후 전략을 적용해 모델 유연성을 향상시켰다. 다양한 비전 작업에서 기존 자기지도 및 약지도 파운데이션 모델보다 우수한 성능을 보이며, 다양한 리소스 제약 및 배포 시나리오에 맞는 확장 가능한 솔루션을 제공한다.

Chain-of-Agents: End-to-End Agent Foundation Models via Multi-Agent Distillation and Agentic RL
https://arxiv.org/abs/2508.13167
Chain-of-Agents는 단일 모델 내에서 다중 에이전트 시스템처럼 작동하는 새로운 LLM 추론 패러다임으로, 모델이 다양한 도구 에이전트와 역할 에이전트를 동적으로 활성화하여 복잡한 문제를 해결한다. 다중 에이전트 증류 프레임워크를 통해 최첨단 다중 에이전트 시스템을 Chain-of-Agents 궤적으로 증류하고, 검증 가능한 에이전트 작업에 대한 에이전트 강화학습으로 모델 능력을 향상시켰다. 이 접근법은 웹 에이전트와 코드 에이전트 설정 모두에서 SOTA 성능을 달성했으며, 모델 가중치, 훈련 및 평가 코드, 훈련 데이터를 모두 오픈소스로 공개했다.
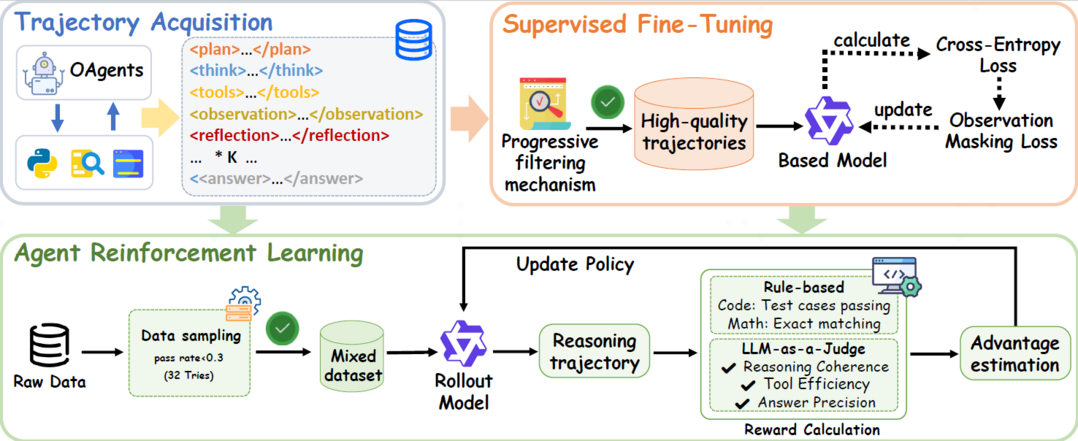
Ovis2.5 Technical Report
https://arxiv.org/abs/2508.11737
Ovis2.5는 원본 해상도 시각 인식 및 강력한 다중 모달 추론을 위한 모델로, 원본 가변 해상도로 이미지를 처리하는 비전 트랜스포머를 통합하여 복잡한 차트와 같은 시각적 밀집 콘텐츠의 품질을 유지한다. 자기 검사 및 수정을 포함한 "reflection" 기능을 구현해 선형 사고 연쇄를 넘어선 추론을 강화했으며, 5단계 커리큘럼 훈련과 DPO 및 GRPO를 통한 정렬 및 추론 향상 과정을 거쳤다. Ovis2.5-9B와 Ovis2.5-2B 두 가지 오픈소스 모델을 출시했으며, OpenCompass 다중 모달 리더보드에서 각각 78.3점과 73.9점으로 SOTA 성능을 달성했다.
SSRL: Self-Search Reinforcement Learning
https://arxiv.org/abs/2508.10874
SSRL은 LLM의 내재적 검색 능력을 활용하여 외부 검색 엔진 의존도를 줄이는 강화학습 접근법이다. 구조화된 프롬프팅과 반복 샘플링을 통한 "Self-Search" 방식으로 LLM의 내재적 검색 능력을 정량화하고, 형식 기반 및 규칙 기반 보상을 통해 LLM의 Self-Search 능력을 향상시켰다. 이 방법은 외부 도구 없이 내부적으로 지식 활용을 반복적으로 개선할 수 있는 능력을 제공하며, 실험 결과 LLM은 효과적으로 이끌어낼 수 있는 세계 지식을 보유하고 있으며, 내부 지식 활용으로 환각을 감소시키고, 외부 검색 엔진과 원활하게 통합됨을 보여주었다.

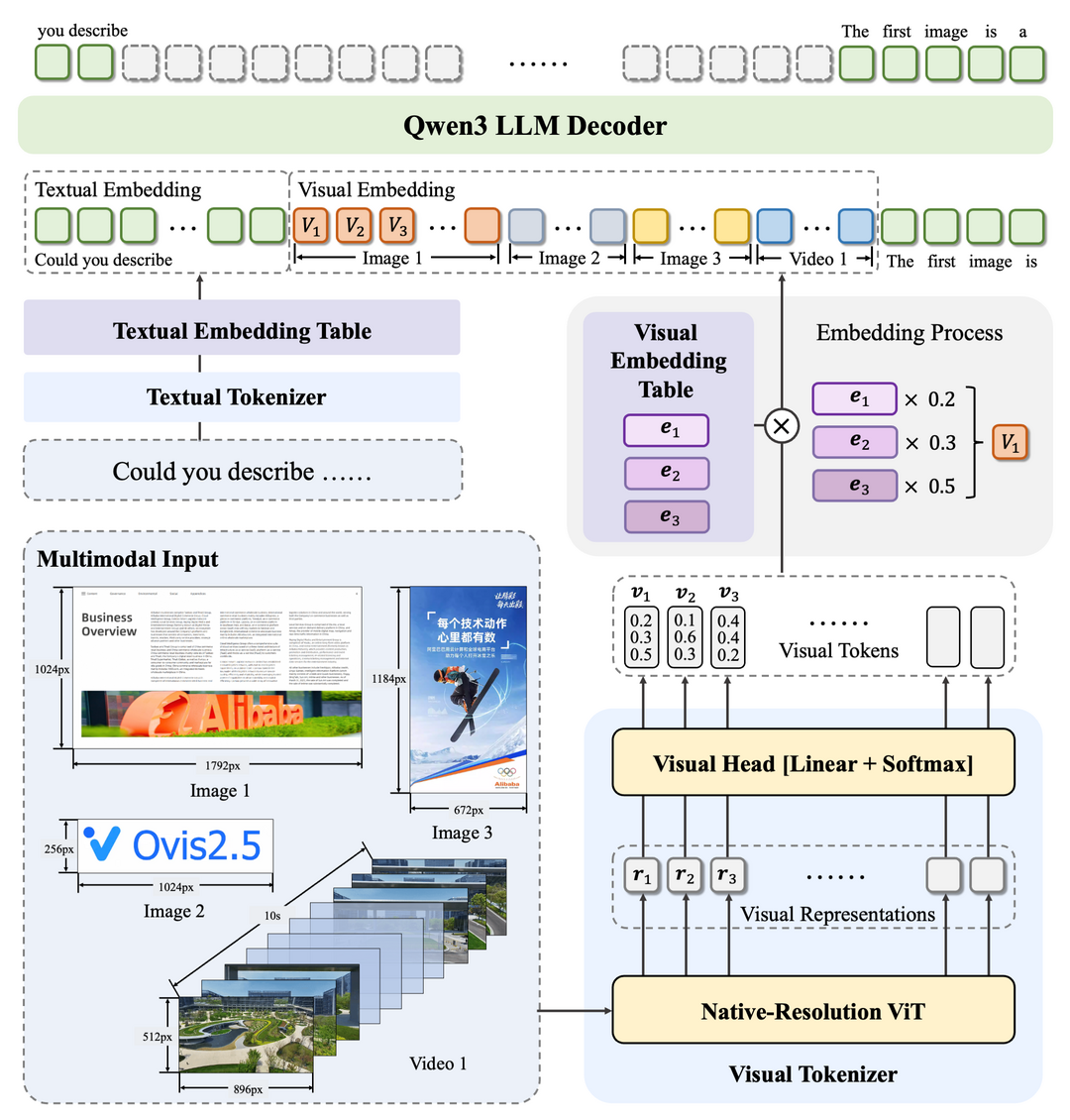
Thyme: Think Beyond Images
https://arxiv.org/abs/2508.11630
Thyme는 이미지를 넘어선 사고 능력을 갖춘 다중 모달 언어 모델로, 실행 가능한 코드를 통해 다양한 이미지 처리 및 계산 작업을 자율적으로 생성하고 실행한다. 이미지 조작(자르기, 회전, 대비 향상 등)과 수학적 계산을 동시에 수행할 수 있으며, 코드 생성을 위한 500K 샘플의 SFT 훈련 후 의사 결정 개선을 위한 RL 단계로 구성된 2단계 훈련 전략을 사용했다. GRPO-ATS 알고리즘을 제안하여 텍스트와 코드 생성에 서로 다른 온도를 적용함으로써 추론 탐색과 코드 실행 정밀도 사이의 균형을 유지했으며, 20개 가까운 벤치마크에서 일관된 성능 향상을 보였다.
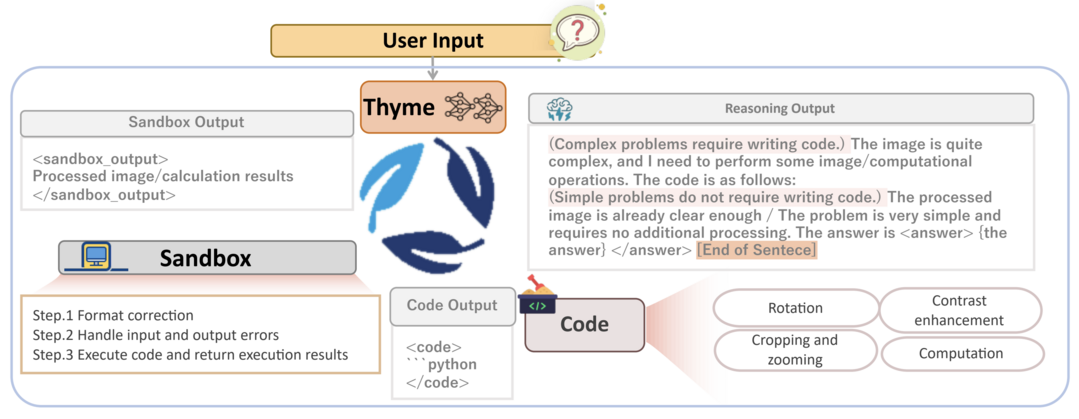
DuPO: Enabling Reliable LLM Self-Verification via Dual Preference Optimization
https://arxiv.org/abs/2508.14460
DuPO는 일반화된 이중성을 통해 주석 없는 피드백을 생성하는 이중 학습 기반 선호도 최적화 프레임워크이다. 기본 작업의 입력을 알려진 부분과 알려지지 않은 부분으로 분해하고, 이중 작업을 구성하여 알려지지 않은 부분을 재구성하는 방식으로 비가역적 작업에도 적용 가능성을 확장했다. 이 재구성의 품질이 기본 작업을 최적화하는 자기지도 보상으로 작용하며, 756개 방향에서 평균 번역 품질 2.13 COMET 향상, 세 가지 수학적 추론 벤치마크에서 평균 6.4포인트 정확도 향상, 추론 시간 재순위 지정기로 사용 시 9.3포인트 성능 향상을 달성했다.
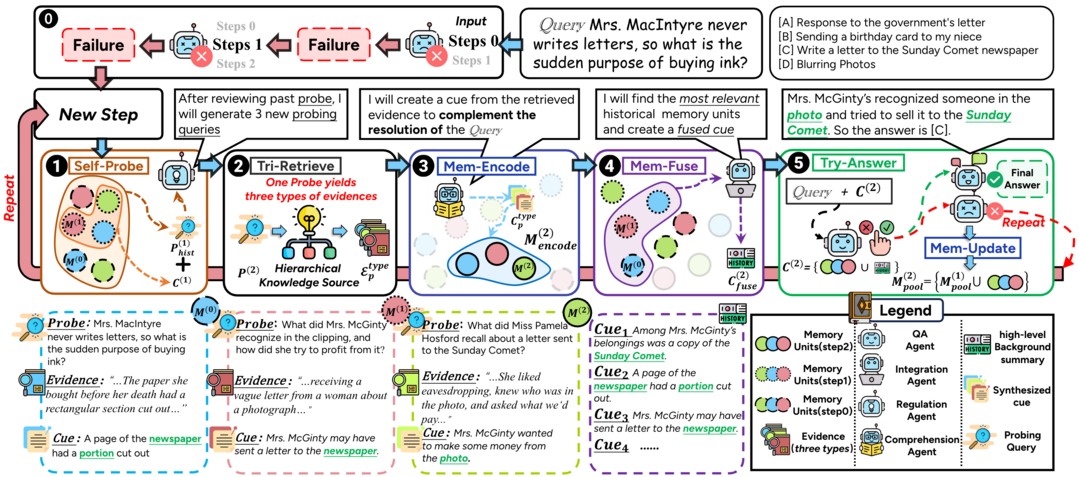
ComoRAG: A Cognitive-Inspired Memory-Organized RAG for Stateful Long Narrative Reasoning
https://arxiv.org/abs/2508.10419
ComoRAG는 장문 내러티브 추론을 위한 인지 영감 메모리 조직 RAG 시스템으로, 전통적인 RAG 방법의 한계를 극복하는 접근법이다. 추론 난관에 부딪혔을 때 동적 메모리 작업공간과 상호작용하는 반복적 추론 사이클을 수행하며, 각 사이클에서 새로운 탐색 경로를 고안하기 위한 탐색 쿼리를 생성하고 새로운 측면의 검색된 증거를 전역 메모리 풀에 통합한다. 4개의 장문 맥락 내러티브 벤치마크에서 강력한 RAG 기준선보다 최대 11% 상대적 성능 향상을 보였으며, 특히 글로벌 이해가 필요한 복잡한 쿼리에 유리한 접근법임을 입증했다.
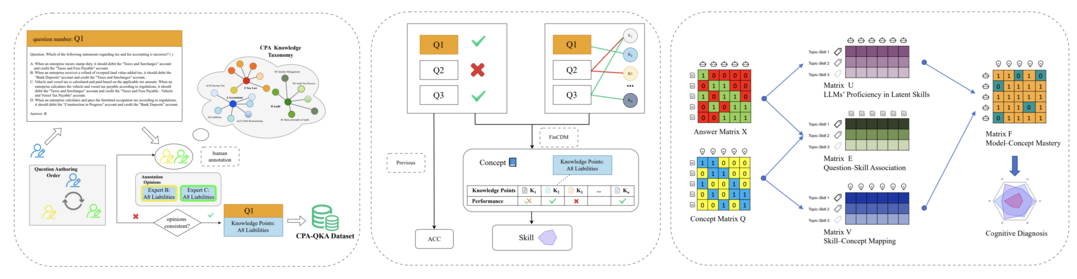
From Scores to Skills: A Cognitive Diagnosis Framework for Evaluating Financial Large Language Models
https://arxiv.org/abs/2508.13491
FinCDM은 금융 LLM을 위한 첫 인지 진단 평가 프레임워크로, 단일 점수가 아닌 지식-기술 수준에서 LLM을 평가하여 금융 기술 및 지식을 파악한다. CPA 시험에서 파생된 인지적으로 정보가 풍부한 금융 평가 데이터셋 CPA-QKA를 구축했으며, 도메인 전문가가 작성, 검증 및 주석을 달아 높은 주석자 간 일치도와 세분화된 지식 라벨을 제공했다. 30개 LLM에 대한 실험 결과, 숨겨진 지식 격차를 발견하고 기존 벤치마크에서 간과된 세금 및 규제 추론과 같은 테스트가 부족한 영역을 식별하는 데 효과적임을 보여주었다.
LongSplat: Robust Unposed 3D Gaussian Splatting for Casual Long Videos
https://arxiv.org/abs/2508.14041
LongSplat은 불규칙한 카메라 움직임, 알려지지 않은 카메라 포즈, 광범위한 장면이 특징인 캐주얼 장편 비디오에서 새로운 뷰 합성 문제를 해결하는 견고한 Unposed 3D Gaussian Splatting 프레임워크이다. 카메라 포즈와 3D 가우시안을 동시에 최적화하는 점진적 공동 최적화, 학습된 3D 사전 지식을 활용하는 강력한 포즈 추정 모듈, 공간 밀도에 기반하여 밀집 포인트 클라우드를 앵커로 변환하는 효율적인 옥트리 앵커 형성 메커니즘을 특징으로 한다. 다양한 벤치마크에서 렌더링 품질, 포즈 정확도, 계산 효율성 측면에서 기존 접근법 대비 상당한 개선을 보였다.

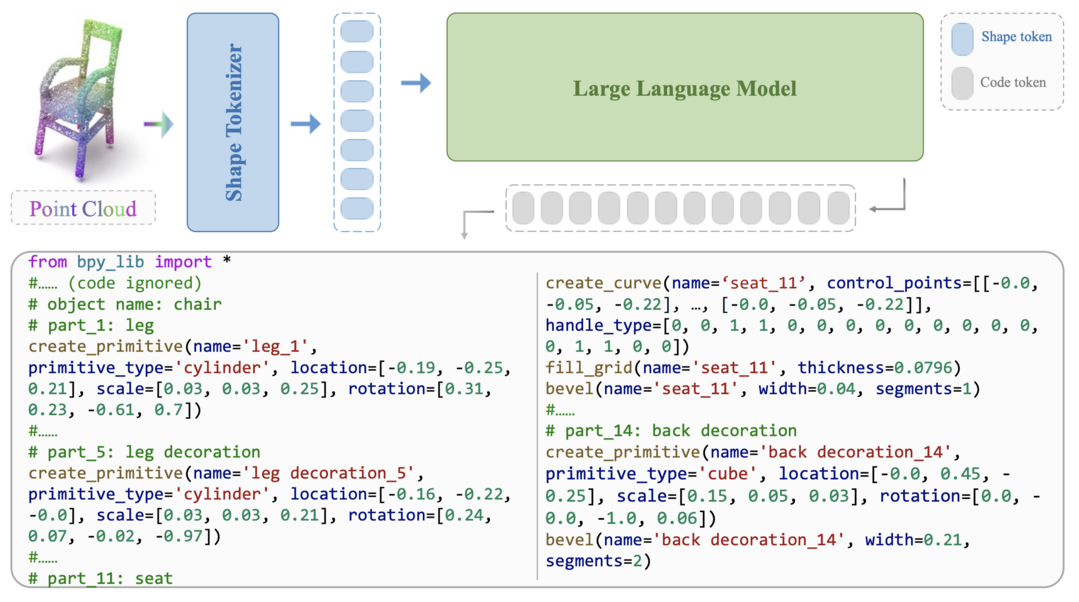
MeshCoder: LLM-Powered Structured Mesh Code Generation from Point Clouds
https://arxiv.org/abs/2508.14879
MeshCoder는 포인트 클라우드에서 복잡한 3D 객체를 편집 가능한 Blender Python 스크립트로 재구성하는 프레임워크이다. 복잡한 기하학을 합성할 수 있는 포괄적인 Blender Python API 세트를 개발하고, 각 객체의 코드가 고유한 의미 부분으로 분해된 대규모 객체-코드 쌍 데이터셋을 구축했다. 3D 포인트 클라우드를 실행 가능한 Blender Python 스크립트로 변환하는 다중 모달 대형 언어 모델을 훈련시켰으며, 형상-코드 재구성 작업에서 우수한 성능을 달성하고 편리한 코드 수정을 통한 직관적인 기하학적, 위상학적 편집을 가능하게 했다.
[METAX = 김한얼 기자]
[저작권자ⓒ META-X. 무단전재-재배포 금지]