차세대 AI를 위한 웹 에이전트, 저비트 어텐션, 3D 장면 표현 및 생성 기술 발전
TL;DR
LLM 아키텍처 및 학습 효율성 분야에서 Qwen3는 '생각하는 모드'와 '생각하지 않는 모드'를 통합하고 '생각 예산'으로 LLM의 성능과 효율성을 극대화한다. Chain-of-Model (CoM/CoLM)은 LLM 학습에 체인 형태의 인과 관계를 도입해 효율성과 유연성을 높인다. 또한, 양자화 인식 학습(QAT) 연구는 4비트 양자화 효율성을 분석해 자원 효율적인 모델 배포 기반을 다진다.
멀티모달 LLM 및 추론 분야에서 BAGEL은 텍스트와 이미지, 비디오 등을 통합 학습해 복잡한 멀티모달 추론 및 생성에서 뛰어난 성능을 보여준다. MMaDA도 유사하게 다양한 멀티모달 작업에서 최고 수준의 성능을 자랑한다. 이들 모델의 성능 평가는 MMLongBench라는 벤치마크가 담당하며, GuardReasoner-VL은 강화 학습으로 VLM의 안전성을 높여 유해 콘텐츠 탐지 능력을 향상시킨다.
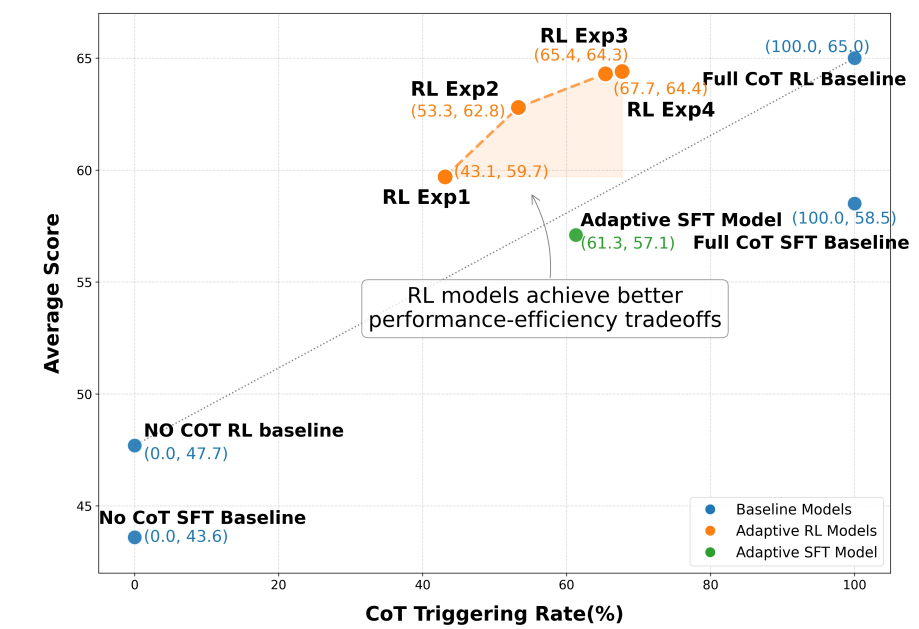
추론 최적화 및 적응형 제어 분야에서 LLM의 추론 비용 문제를 해결하기 위해 AdaptThink는 강화 학습으로 모델이 문제 난이도에 따라 최적의 '사고 모드'를 선택하게 해 효율성과 성능을 동시에 잡는다. AdaCoT 역시 강화 학습을 통해 복잡한 추론이 필요할 때만 '사고의 연쇄(CoT)'를 발동시켜 비용을 크게 절감하면서도 높은 성능을 유지한다. 이 두 연구는 LLM의 실용적인 활용도를 높이는 데 기여한다.
웹 에이전트 및 저비트 어텐션 분야에서 Web-Shepherd는 웹 내비게이션에 특화된 최초의 보상 모델로, 웹 에이전트의 효율적인 학습과 성능 향상을 돕는다. NovelSeek은 가설에서 검증까지 자율 과학 연구를 수행하는 멀티 에이전트 프레임워크로, 과학 연구 효율성을 가속화할 잠재력을 보여준다. 마지막으로 SageAttention3는 FP4 Tensor Cores와 8비트 저비트 어텐션 적용을 통해 대규모 모델의 추론 및 학습 효율성을 획기적으로 개선한다.
3D 장면 표현 및 생성 분야에서 3D-4DGS는 동적 3D 장면을 효율적으로 표현하기 위해 정적 영역과 동적 영역을 3D 및 4D 가우시안으로 구분하는 하이브리드 방식을 사용해 훈련 시간을 단축하고 효율성을 높인다. 또한, 3DTown은 단 한 장의 상단 이미지로 사실적이고 일관된 3D 도시 장면을 생성하는 훈련 없는 프레임워크를 제시하며, 고품질 3D 재구성의 새로운 가능성을 연다.
1.대규모 언어 모델 (LLM) 아키텍처 및 학습 효율성 분야
Qwen3 Technical Report
https://arxiv.org/abs/2505.09388
Qwen3는 최신 대규모 언어 모델(LLM) 시리즈로, 성능, 효율성, 그리고 다국어 능력을 한 단계 더 발전시킨다. 이 모델은 밀집(dense) 및 혼합 전문가(MoE) 아키텍처를 모두 사용하며, 0.6억 개부터 2,350억 개에 이르는 다양한 규모의 모델들을 포함한다. 특히, 복잡한 추론을 위한 '사고 모드'와 빠른 응답을 위한 '비사고 모드'를 하나의 프레임워크로 통합하여 사용자가 질의에 따라 이 모드를 동적으로 전환할 수 있게 했다. 또한, '사고 예산' 메커니즘을 통해 사용자가 계산 리소스를 유연하게 할당하여 지연 시간과 성능의 균형을 맞출 수 있도록 돕는다. Qwen2.5에 비해 다국어 지원이 29개에서 119개 언어로 크게 확장되었으며, 코드 생성, 수학적 추론 등 다양한 벤치마크에서 최고 수준의 성능을 보여준다. 모든 Qwen3 모델은 연구 및 개발을 위해 Apache 2.0 라이선스로 공개된다.

Chain-of-Model Learning for Language Model
https://arxiv.org/abs/2505.11820
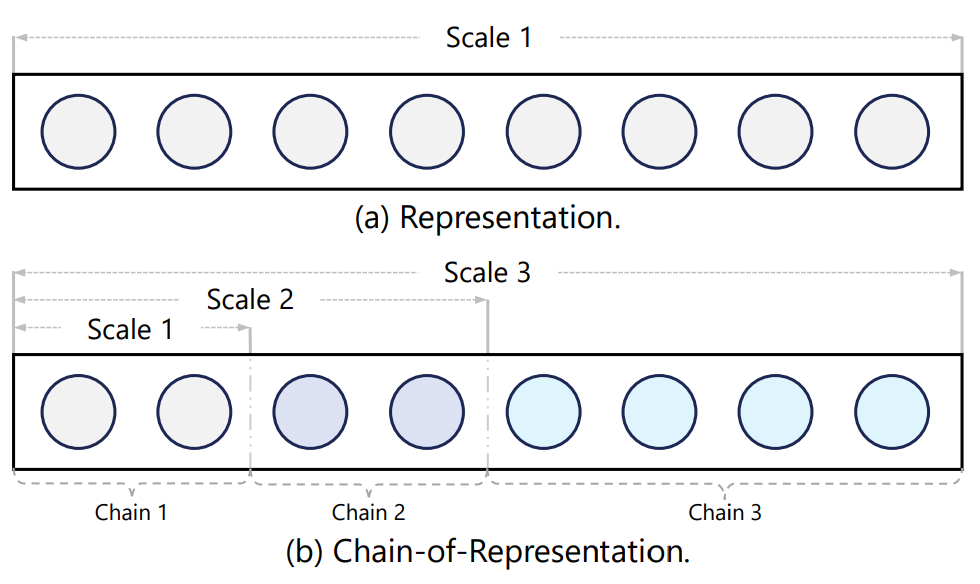
이 논문은 각 레이어의 은닉 상태에 인과 관계를 체인 형태로 통합하는 새로운 학습 패러다임인 Chain-of-Model (CoM)을 제안한다. 이는 모델 학습에서 뛰어난 확장 효율성을 제공하고 배포 시 추론 유연성을 높인다. CoM은 각 레이어의 은닉 상태를 여러 하위 표현(체인)의 조합으로 구성하는 Chain-of-Representation (CoR) 개념을 도입한다. 이 원리를 통해 CoM 기반 모델은 이전 모델을 기반으로 체인을 늘려 모델 크기를 점진적으로 확장할 수 있으며, 다양한 크기의 여러 하위 모델을 제공하여 유연한 추론을 가능하게 한다. CoM 아이디어를 트랜스포머 아키텍처에 통합한 Chain-of-Language-Model (CoLM)을 개발했으며, 여기에 KV 공유 메커니즘을 더한 CoLM-Air는 LM 전환의 원활함, 사전 채우기 가속화와 같은 추가 확장성을 보여준다. 실험 결과, CoLM 계열은 표준 트랜스포머와 유사한 성능을 달성하면서도 뛰어난 유연성을 제공한다.
Scaling Law for Quantization-Aware Training
https://arxiv.org/abs/2505.14302
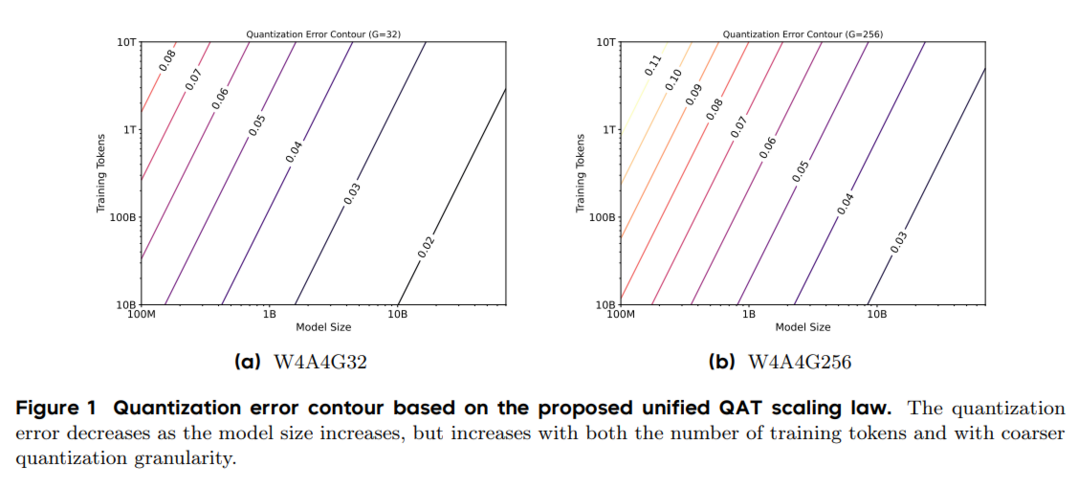
이 논문은 대규모 언어 모델(LLM)의 배포 어려움을 해결하기 위해 모델 정밀도를 줄이면서 성능을 유지하는 양자화 인식 학습(QAT)의 스케일링 법칙을 연구한다. 특히 4비트 정밀도(W4A4) QAT의 스케일링 동작을 이해하기 위해, 모델 크기, 훈련 데이터 양, 양자화 그룹 크기의 함수로 양자화 오류를 모델링하는 통합 스케일링 법칙을 제안한다. 268개 실험을 통해 양자화 오류가 모델 크기가 증가함에 따라 감소하지만, 훈련 토큰 수가 많아지고 양자화 입도가 거칠어질수록 증가한다는 것을 밝힌다. W4A4 양자화 오류를 가중치 및 활성화 구성 요소로 분해한 결과, FC2 레이어의 활성화 양자화 오류(이상치로 인해 발생)가 주요 병목 현상임을 발견하며, 혼합 정밀도 양자화를 통해 이를 해결할 수 있음을 보여준다.
2.멀티모달 LLM 및 추론 분야
Emerging Properties in Unified Multimodal Pretraining
https://arxiv.org/abs/2505.14683
이 논문은 멀티모달 이해와 생성을 통합한 오픈소스 기반 모델 BAGEL을 소개한다. BAGEL은 텍스트, 이미지, 비디오, 웹 데이터가 혼합된 수조 개의 토큰으로 사전 학습된 통합 디코더 전용 모델이다. 이처럼 다양한 멀티모달 데이터로 확장되면서 BAGEL은 복잡한 멀티모달 추론에서 뛰어난 능력을 보여주며, 기존 오픈소스 통합 모델들을 멀티모달 생성 및 이해 측면에서 크게 능가한다. 특히, 자유 형식 이미지 조작, 미래 프레임 예측, 3D 조작, 월드 내비게이션과 같은 고급 멀티모달 추론 능력까지 갖추고 있다.

MMaDA: Multimodal Large Diffusion Language Models
https://arxiv.org/abs/2505.15809
이 논문은 텍스트 추론, 멀티모달 이해, 텍스트-이미지 생성 등 다양한 영역에서 뛰어난 성능을 달성하도록 설계된 새로운 멀티모달 확산 기반 모델인 MMaDA를 소개한다. MMaDA는 통합 확산 아키텍처를 채택하여 양식별 구성 요소 없이 다양한 데이터 유형을 원활하게 통합하고 처리한다. 또한, 텍스트 및 시각 도메인 간의 추론 과정을 정렬하는 혼합된 긴 사고의 연쇄(CoT) 미세 조정 전략을 통해 강화 학습 단계의 콜드 스타트 학습을 용이하게 한다. 마지막으로, 확산 기반 모델에 특화된 UniGRPO라는 통합 정책 기울기 기반 강화 학습 알고리즘을 제안하여 추론 및 생성 작업 전반에 걸쳐 일관된 성능 향상을 보장한다. MMaDA-8B는 텍스트 추론에서 LLaMA-3-7B 및 Qwen2-7B를, 멀티모달 이해에서 Show-o 및 SEED-X를, 텍스트-이미지 생성에서 SDXL 및 Janus를 능가하는 강력한 성능을 보여준다.
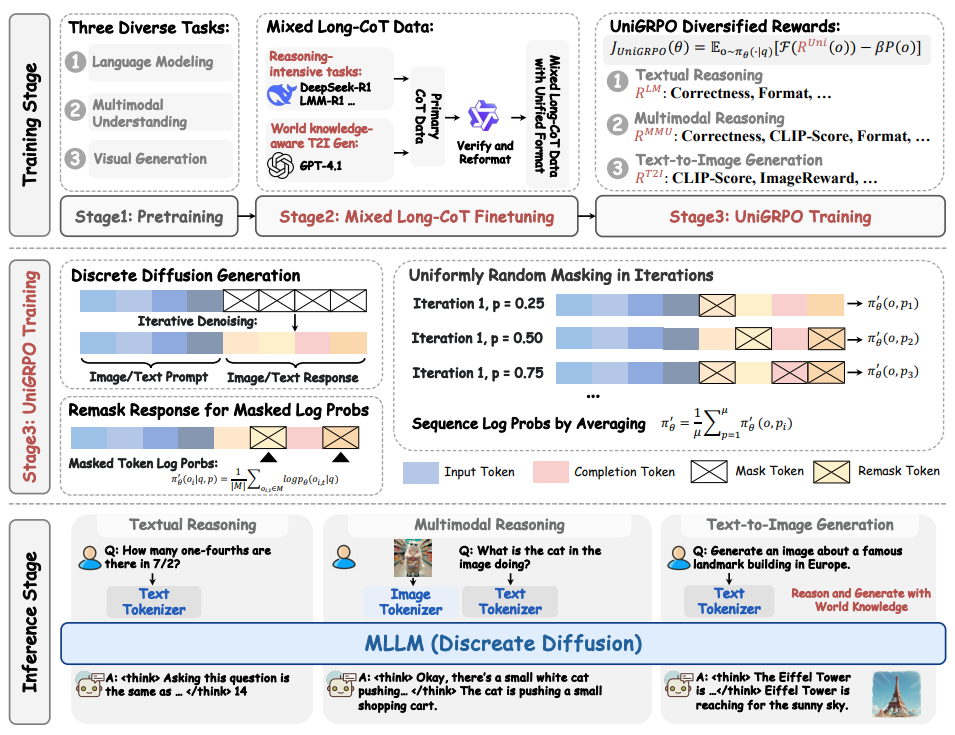
MMLongBench: Benchmarking Long-Context Vision-Language Models Effectively and Thoroughly
https://arxiv.org/abs/2505.10610
이 논문은 장문 맥락 시각-언어 모델(LCVLM)의 효과적이고 철저한 평가를 위해 다양한 장문 맥락 시각-언어 작업을 다루는 최초의 벤치마크인 MMLongBench를 소개한다. MMLongBench는 시각적 RAG 및 Many-Shot ICL과 같은 다섯 가지 범주의 하위 작업을 포괄하는 13,331개의 예시로 구성되며, 다양한 자연 및 합성 이미지 유형을 포함한다. 모델의 입력 길이 견고성을 평가하기 위해 모든 예시는 시각 패치와 텍스트 토큰을 결합하는 교차 모달 토큰화 방식을 통해 다섯 가지 표준화된 입력 길이(8K-128K 토큰)로 제공된다. 46개 LCVLM에 대한 철저한 벤치마킹을 통해, 단일 작업 성능이 전반적인 장문 맥락 능력을 나타내는 약한 지표임을 밝히고, 폐쇄형 및 오픈소스 모델 모두 장문 맥락 시각-언어 작업에서 여전히 개선의 여지가 크다는 점, 그리고 추론 능력이 강한 모델이 더 나은 장문 맥락 성능을 보이는 경향이 있음을 보여준다.
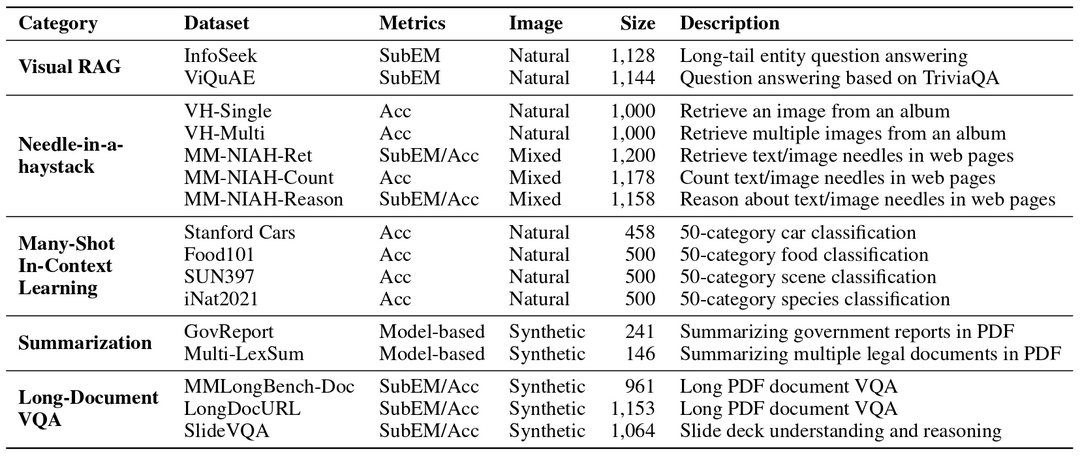
GuardReasoner-VL: Safeguarding VLMs via Reinforced Reasoning
https://arxiv.org/abs/2505.11049
이 논문은 VLM(시각-언어 모델)의 안전성을 향상시키기 위해, 추론 기반 VLM 가드 모델인 GuardReasoner-VL을 소개한다. 핵심 아이디어는 온라인 강화 학습(RL)을 통해 가드 모델이 중재 결정을 내리기 전에 신중하게 추론하도록 유도하는 것이다. 이를 위해 텍스트, 이미지, 텍스트-이미지 입력을 아우르는 대규모 추론 코퍼스인 GuardReasoner-VLTrain을 구축하고, 이를 기반으로 모델의 추론 능력을 강화 학습한다. 특히, 샘플의 다양성과 난이도를 높이기 위한 안전 인식 데이터 연결을 통한 데이터 증강과 성능-효율성 균형을 위한 길이 인식 안전 보상을 설계한다. 광범위한 실험을 통해 GuardReasoner-VL은 다른 모델들을 압도하는 뛰어난 성능을 보여주며, VLM 안전성 연구의 발전에 기여한다.
3.추론 최적화 및 적응형 제어 분야
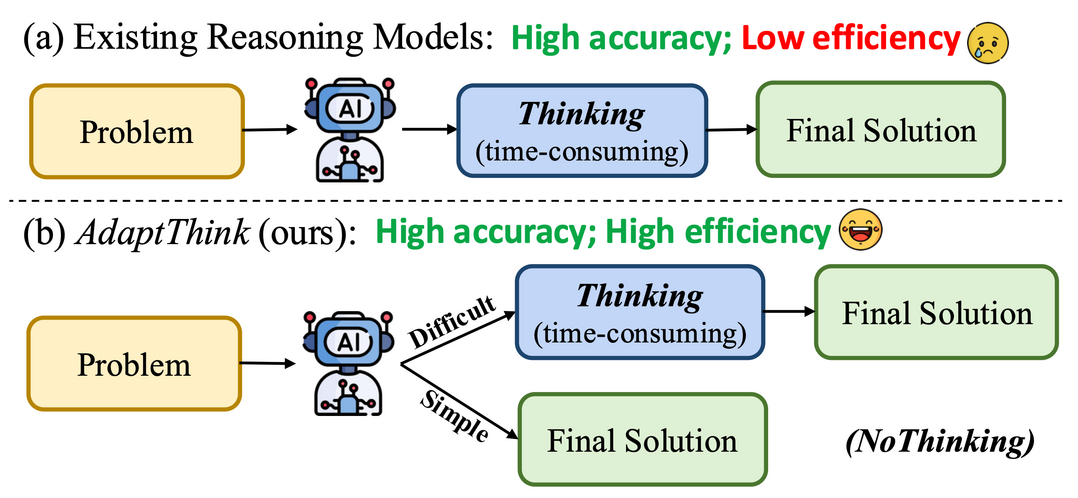
AdaptThink: Reasoning Models Can Learn When to Think
https://arxiv.org/abs/2505.13417
이 연구는 대규모 추론 모델이 복잡한 사고 과정을 통해 좋은 성능을 내지만, 이로 인해 발생하는 높은 추론 비용 문제를 해결하기 위해 AdaptThink라는 새로운 강화 학습(RL) 알고리즘을 제안한다. AdaptThink는 추론 모델이 문제 난이도에 따라 '사고 모드'와 '비사고 모드' 중 최적의 모드를 적응적으로 선택하도록 가르친다. 특히, 간단한 작업에서는 사고 과정을 생략하고 직접 답을 내는 'NoThinking' 방식이 성능과 효율성 면에서 더 나은 선택임을 밝히고, 이를 바탕으로 모델이 전체 성능을 유지하면서 'NoThinking'을 선택하도록 유도하는 제약 조건부 최적화 목표와 학습 중 두 가지 사고 모드 샘플의 균형을 맞추는 중요도 샘플링 전략을 핵심 구성 요소로 사용한다. 실험 결과, AdaptThink는 추론 비용을 크게 줄이면서도 성능을 향상시키는 효과적인 방법을 제시한다.
AdaCoT: Pareto-Optimal Adaptive Chain-of-Thought Triggering via Reinforcement Learning
https://arxiv.org/abs/2505.11896
이 논문은 대규모 언어 모델(LLM)이 정교한 추론 작업에서 뛰어난 성능을 보이지만, 사고의 연쇄(CoT) 프롬프트가 모든 질의에 대해 불필요하게 긴 추론 단계를 생성하여 비효율성을 야기하는 문제에 주목한다. 이를 해결하기 위해, LLM이 언제 CoT를 호출할지 적응적으로 결정하도록 하는 새로운 프레임워크인 AdaCoT (Adaptive Chain-of-Thought)를 제안한다. AdaCoT는 적응형 추론을 모델 성능과 CoT 호출 비용 간의 균형을 찾는 파레토 최적화 문제로 구성하며, 강화 학습(RL) 기반 방법을 사용하여 CoT 트리거링 결정 경계를 동적으로 제어한다. 특히, 다단계 RL 훈련 중 결정 경계 붕괴를 방지하는 선택적 손실 마스킹(SLM)이 핵심 기술이다. 실험 결과, AdaCoT는 복잡한 추론이 필요 없는 질의에 대한 CoT 사용량을 크게 줄이면서도 높은 성능을 유지함을 입증한다.
4.웹 에이전트 및 저비트 어텐션 분야
Web-Shepherd: Advancing PRMs for Reinforcing Web Agents
https://arxiv.org/abs/2505.15277
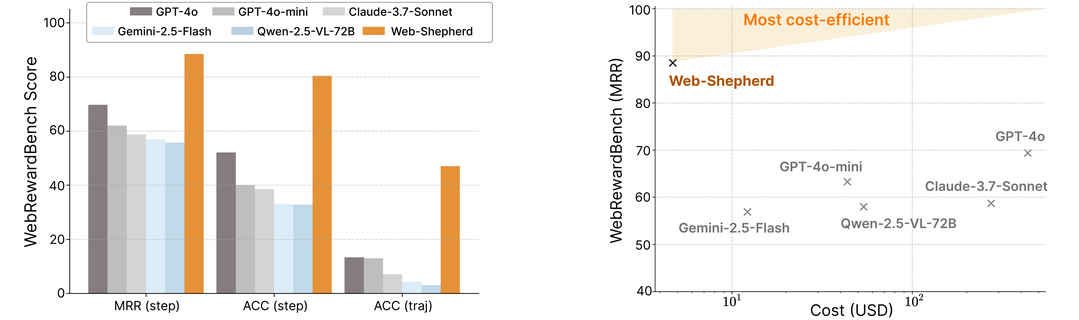
이 연구는 웹 내비게이션에 특화된 최초의 프로세스 보상 모델(PRM)인 Web-Shepherd를 제안한다. 웹 내비게이션은 복잡한 다단계 의사 결정이 필요한 도전적인 영역이며, Web-Shepherd는 단계별로 웹 내비게이션 경로를 평가할 수 있다. 이 모델을 위해 4만 개의 단계별 선호도 쌍으로 구성된 대규모 데이터셋인 WebPRM Collection을 구축했으며, PRM 평가를 위한 최초의 메타 평가 벤치마크인 WebRewardBench도 도입했다. 실험 결과, Web-Shepherd는 WebRewardBench에서 GPT-4o보다 약 30% 더 나은 정확도를 달성했으며, GPT-4o-mini를 정책으로 사용하고 Web-Shepherd를 검증자로 사용했을 때 더 적은 비용으로도 더 나은 성능을 보여주며 웹 에이전트의 실제 배포 가능성을 높인다.
NovelSeek: When Agent Becomes the Scientist -- Building Closed-Loop System from Hypothesis to Verification
https://arxiv.org/abs/2505.16938
이 논문은 인공지능(AI)이 과학 연구 패러다임을 가속화하고 있음을 강조하며, 가설 설정부터 검증까지 자율적인 과학 연구(ASR)를 수행하는 통합 폐쇄 루프 멀티 에이전트 프레임워크 NovelSeek을 소개한다. NovelSeek은 확장성, 상호작용성, 효율성이라는 세 가지 핵심 장점을 갖는다. 12가지 과학 연구 작업에서 혁신적인 아이디어를 생성하고, 인간 전문가 피드백과 멀티 에이전트 상호작용을 통해 도메인 전문가 지식 통합을 가능하게 한다. 또한, 인간의 노력에 비해 훨씬 적은 시간으로 여러 과학 분야에서 유망한 성능 향상을 달성하여 AI가 과학 연구 효율성을 크게 높일 수 있음을 입증한다.
SageAttention3: Microscaling FP4 Attention for Inference and An Exploration of 8-Bit Training
https://arxiv.org/abs/2505.11594
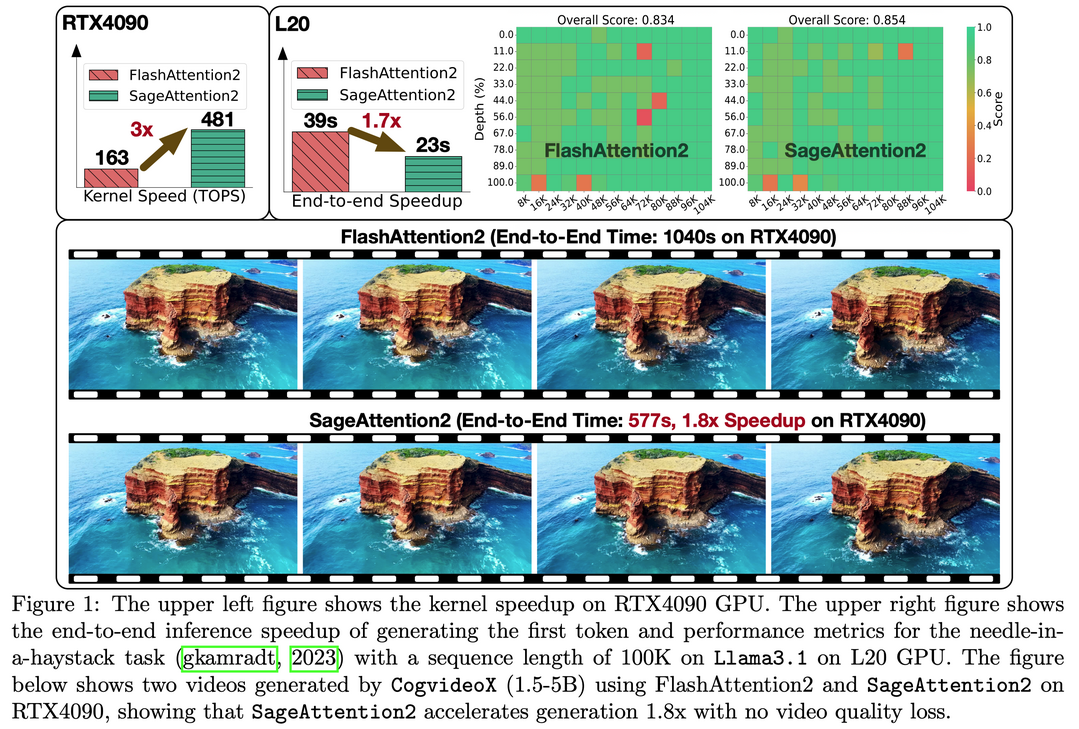
이 연구는 어텐션의 효율성을 높이기 위한 두 가지 핵심 기여를 제시한다. 첫째, Blackwell GPU의 새로운 FP4 Tensor Cores를 활용하여 어텐션 계산을 가속화하며, 이는 RTX5090에서 가장 빠른 FlashAttention보다 5배 빠른 속도를 보여준다. 이 FP4 어텐션은 다양한 모델의 추론에 플러그 앤 플레이 방식으로 적용될 수 있다. 둘째, 저비트 어텐션(low-bit attention)을 학습 작업에 적용하는 선구적인 시도를 한다. 기존 연구들이 추론에만 초점을 맞췄던 것과 달리, 순방향 및 역방향 전파 모두를 위한 정확하고 효율적인 8비트 어텐션을 설계했다. 실험 결과, 8비트 어텐션은 미세 조정 작업에서 무손실 성능을 달성했지만, 사전 학습 작업에서는 수렴 속도가 느려지는 경향을 보였다.
5.3D 장면 표현 및 생성 분야
Hybrid 3D-4D Gaussian Splatting for Fast Dynamic Scene Representation
https://arxiv.org/abs/2505.13215
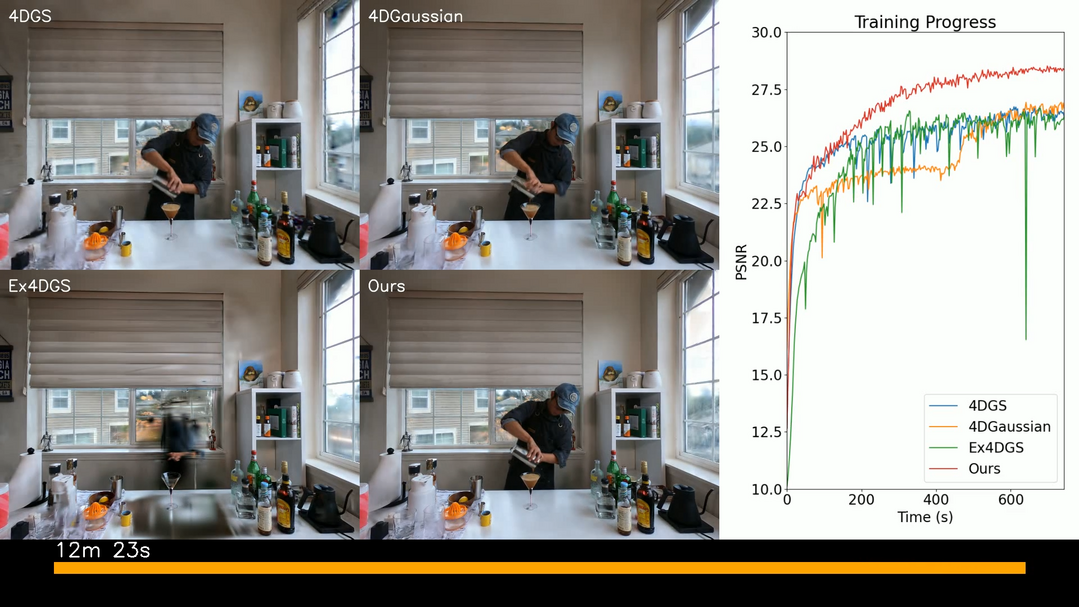
이 연구는 동적 3D 장면 재구성을 위한 새로운 프레임워크인 하이브리드 3D-4D 가우시안 스플래팅(3D-4DGS)을 소개한다. 기존 4D 가우시안 스플래팅(4DGS) 방법은 정적 영역에 4D 가우시안을 중복 할당하여 계산 및 메모리 오버헤드를 초래하는 문제를 해결한다. 3D-4DGS는 정적 영역을 3D 가우시안으로 적응적으로 표현하고 동적 요소에만 4D 가우시안을 할당함으로써, 매개변수 수를 크게 줄이고 계산 효율성을 향상시킨다. 이 방법은 전체 4D 가우시안 표현으로 시작하여 시간적으로 불변하는 가우시안을 3D로 점진적으로 변환한다. 이를 통해 복잡한 움직임을 고화질로 캡처하면서도 기존 4DGS 방법에 비해 훈련 시간을 크게 단축하고 시각적 품질을 유지하거나 향상시키는 결과를 보여준다.
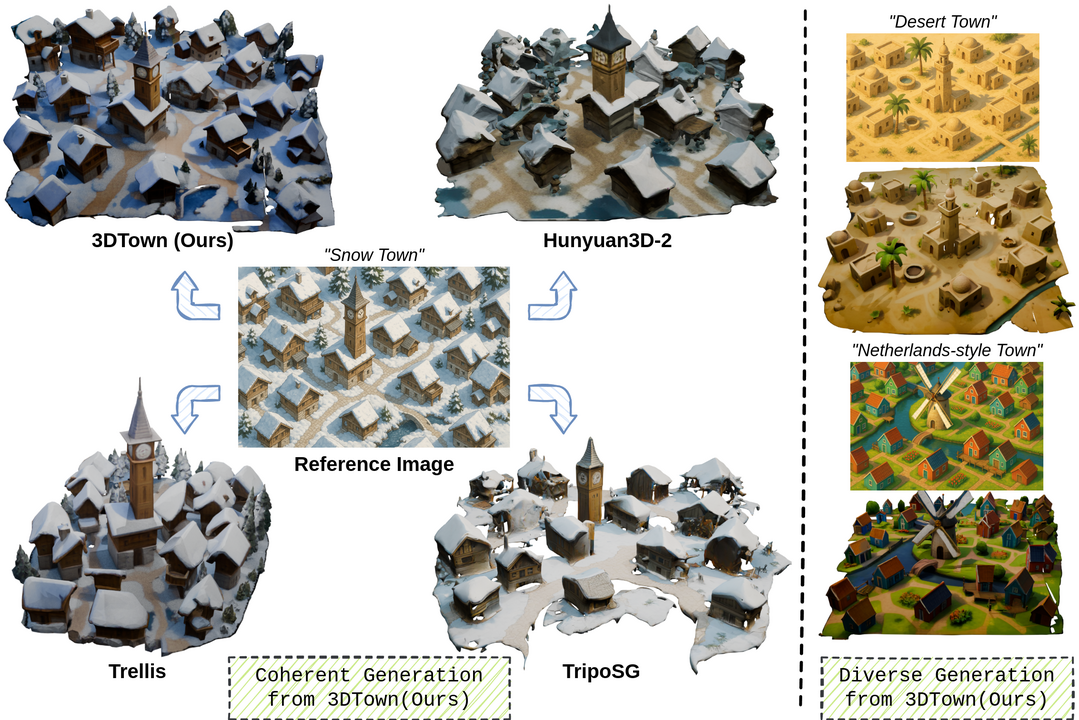
Constructing a 3D Town from a Single Image
https://arxiv.org/abs/2505.15765
이 연구는 단일 상단 이미지에서 사실적이고 일관된 3D 장면을 합성하는 훈련 없는(training-free) 프레임워크인 3DTown을 소개한다. 상세한 3D 장면 획득이 일반적으로 높은 비용과 복잡한 과정을 요구하는 문제를 해결하기 위해, 3DTown은 이미지-3D 정렬 및 해상도 개선을 위한 영역 기반 생성과 전역 장면 일관성 및 고품질 기하학 생성을 보장하는 공간 인식 3D 인페인팅이라는 두 가지 원칙에 기반한다. 이 방법은 입력 이미지를 중첩된 영역으로 분해하고 각 영역을 사전 학습된 3D 객체 생성기로 생성한 다음, 마스크된 정류 유동(rectified flow) 인페인팅 프로세스를 통해 누락된 기하학을 채운다. 이 모듈식 설계는 3D 감독이나 미세 조정 없이도 해상도 병목 현상을 극복하고 공간 구조를 보존할 수 있게 하며, 기존 최신 모델들을 능가하는 고품질 3D 도시 생성을 가능하게 한다.
[METAX = 김한얼 기자]
[저작권자ⓒ META-X. 무단전재-재배포 금지]