2024년 W48에 공개된 주목할만한 인공지능(AI) 분야의 논문들을 소개합니다. 각 논문별 간단한 요약을 원하시는 분들은 아래의 TL;DR을 참고해주세요.
TL;DR
Style-Friendly SNR과 OminiControl은 각각 효율적인 스타일 전이와 최소한의 파라미터로 이미지 조건을 제어하는 기법을 제안했고, Material Anything과 CAT4D는 3D 객체의 재질 생성과 4D 장면 생성이라는 도전적인 과제에 대한 해결책을 제시했습니다. 언어 모델 분야에서는 TÜLU 3가 완전히 공개된 모델로 GPT-4o-mini와 Claude 3.5-Haiku를 능가하는 성능을 보여주었으며, Star Attention은 긴 시퀀스 처리의 효율성을 크게 개선했습니다. 특히 실용적인 측면에서는 GUI 환경에 특화된 ShowUI와 정교한 instance 제어를 위한 ROICtrl이 제안되었으며, LLM-as-a-judge 연구를 통해 AI 모델의 평가자 역할에 대한 새로운 관점이 제시되었습니다.
Style-Friendly SNR Sampler for Style-Driven Generation

최근의 대규모 diffusion model들은 고품질 이미지를 생성할 수 있지만, 새롭고 개인화된 예술적 스타일을 학습하는 데 어려움을 겪고 있습니다. 이 논문은 Style-friendly SNR sampler를 제안하는데, 이는 fine-tuning 과정에서 signal-to-noise ratio (SNR) 분포를 더 높은 noise level 쪽으로 적극적으로 이동시켜 스타일적 특징이 나타나는 noise level에 집중합니다. 이를 통해 개인의 수채화, 미니멀 플랫 카툰, 3D 렌더링, 멀티패널 이미지, 텍스트가 있는 밈 등 다양한 스타일을 생성할 수 있게 되었습니다.
OminiControl: Minimal and Universal Control for Diffusion Transformer

OminiControl은 사전 훈련된 Diffusion Transformer (DiT) 모델에 이미지 조건을 통합하는 매우 다목적이고 파라미터 효율적인 프레임워크입니다. 약 0.1%의 추가 파라미터만으로 이미지 조건을 효과적으로 통합하며, subject-driven generation과 edges, depth 등의 spatially-aligned conditions를 포함한 다양한 이미지 조건 작업을 통합된 방식으로 처리합니다. 논문은 또한 Subjects200K라는 200,000개 이상의 identity-consistent 이미지 데이터셋을 공개했습니다.
Material Anything: Generating Materials for Any 3D Object via Diffusion
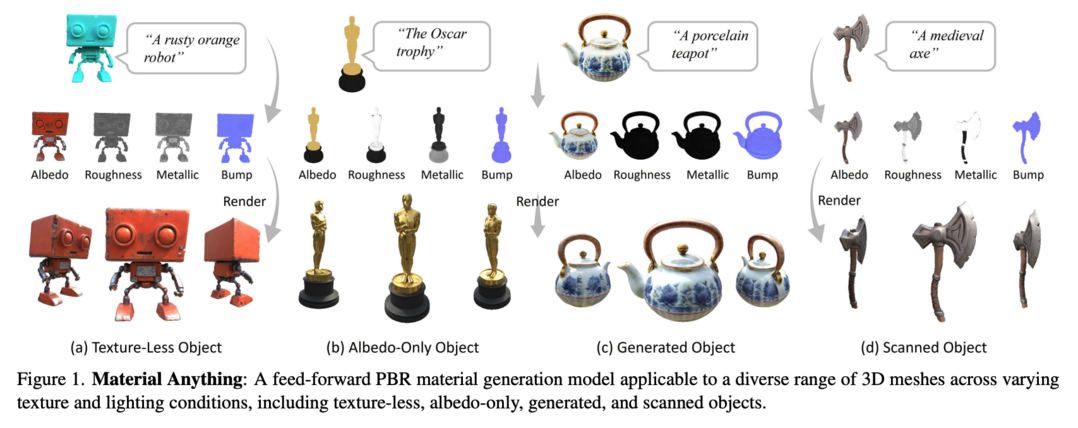
Material Anything은 3D 객체를 위한 physically-based 재질을 생성하는 자동화된 통합 diffusion 프레임워크입니다. 기존의 복잡한 파이프라인이나 케이스별 최적화에 의존하는 방식과 달리, 다양한 조명 조건에서도 적용 가능한 end-to-end 솔루션을 제공합니다. 사전 훈련된 image diffusion model을 활용하며, triple-head 아키텍처와 rendering loss를 통해 안정성과 재질 품질을 향상시켰습니다.
CAT4D: Create Anything in 4D with Multi-View Video Diffusion Models

CAT4D는 단안 비디오에서 4D 장면을 생성하는 방법을 제시합니다. 다양한 데이터셋 조합으로 훈련된 multi-view video diffusion 모델을 활용하여 지정된 카메라 포즈와 타임스탬프에서 novel view synthesis를 가능하게 합니다. (https://cat-4d.github.io/)
TÜLU 3: Pushing Frontiers in Open Language Model Post-Training
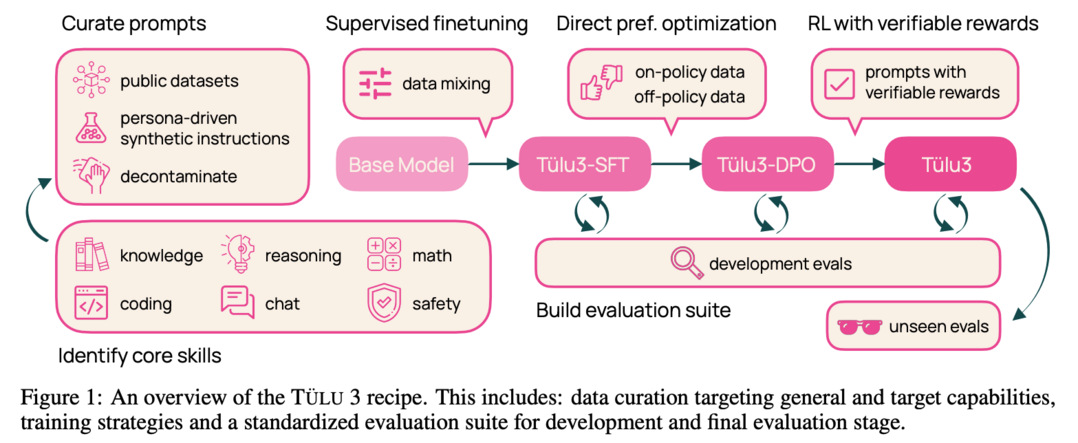
이 논문은 완전히 공개된 최신 post-trained model인 TÜLU 3를 소개합니다. Llama 3.1 base model을 기반으로 하며, Llama 3.1의 instruct 버전, Qwen 2.5, Mistral, 심지어 GPT-4o-mini와 Claude 3.5-Haiku와 같은 비공개 모델들보다 우수한 성능을 보여줍니다. supervised finetuning (SFT), Direct Preference Optimization (DPO), 그리고 새로운 방법인 Reinforcement Learning with Verifiable Rewards (RLVR)를 포함한 훈련 알고리즘을 사용합니다. 전체 레시피와 데이터셋, 평가 도구, 훈련 코드 등을 공개했습니다.
Star Attention: Efficient LLM Inference over Long Sequences
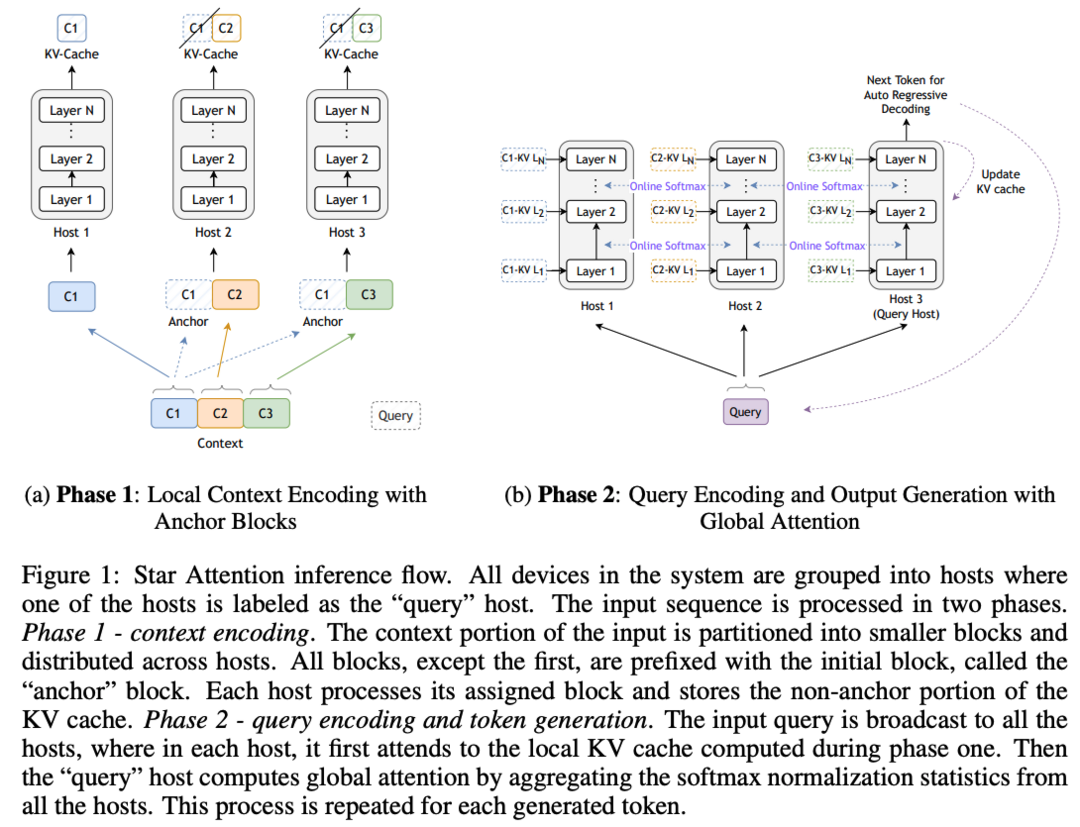
Star Attention은 긴 시퀀스에서 LLM 추론을 효율적으로 수행하기 위한 two-phase block-sparse approximation을 도입합니다. 첫 번째 단계에서는 blockwise-local attention을 사용하여 병렬로 컨텍스트를 처리하고, 두 번째 단계에서는 query와 response 토큰이 sequence-global attention을 통해 이전의 캐시된 토큰들에 접근합니다. 이를 통해 95-100%의 정확도를 유지하면서 메모리 요구사항과 추론 시간을 최대 11배까지 줄일 수 있습니다.
Large-Scale Text-to-Image Model with Inpainting is a Zero-Shot Subject-Driven Image Generator
이 논문은 Diptych Prompting이라는 새로운 zero-shot 접근 방식을 소개합니다. 이는 large-scale text-to-image 모델에서 나타나는 diptych generation의 특성을 활용하여 정확한 subject alignment를 가진 inpainting 작업으로 재해석합니다. 실험 결과는 이 접근 방식이 기존의 zero-shot image prompting 방법들을 크게 능가하며, 사용자들이 시각적으로 더 선호하는 이미지를 생성한다는 것을 보여줍니다. (https://diptychprompting.github.io/)
ShowUI: One Vision-Language-Action Model for GUI Visual Agent
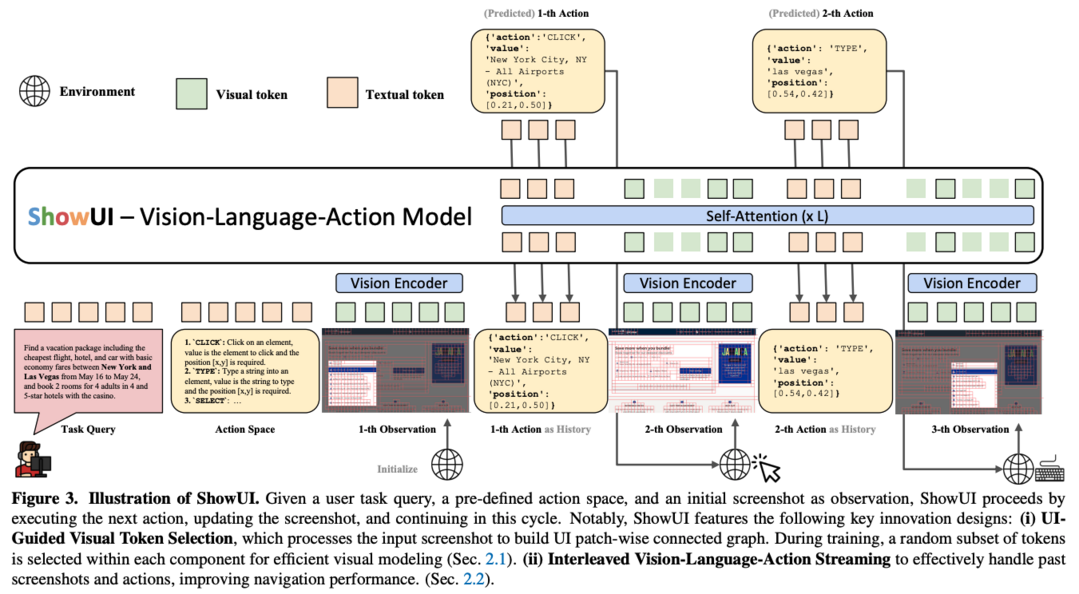
ShowUI는 디지털 세계에서의 vision-language-action 모델로, GUI 시각 에이전트를 위한 혁신적인 기능들을 제공합니다. UI-Guided Visual Token Selection과 Interleaved Vision-Language-Action Streaming을 특징으로 하며, 256K 데이터를 사용하는 2B 규모의 경량 모델로 zero-shot screenshot grounding에서 75.1%의 높은 정확도를 달성했습니다. (https://github.com/showlab/ShowUI)
ROICtrl: Boosting Instance Control for Visual Generation

ROICtrl은 사전 훈련된 diffusion 모델을 위한 어댑터로, 정확한 regional instance 제어를 가능하게 합니다. ROI-Align과 ROI-Unpool 작업을 통해 고해상도 feature map에서 명시적이고 효율적이며 정확한 ROI 조작을 가능하게 합니다. ControlNet, T2I-Adapter와 같은 spatial-based add-on과 IP-Adapter, ED-LoRA와 같은 embedding-based add-on과도 호환되어 multi-instance generation으로 응용 범위를 확장합니다.
From Generation to Judgment: Opportunities and Challenges of LLM-as-a-judge
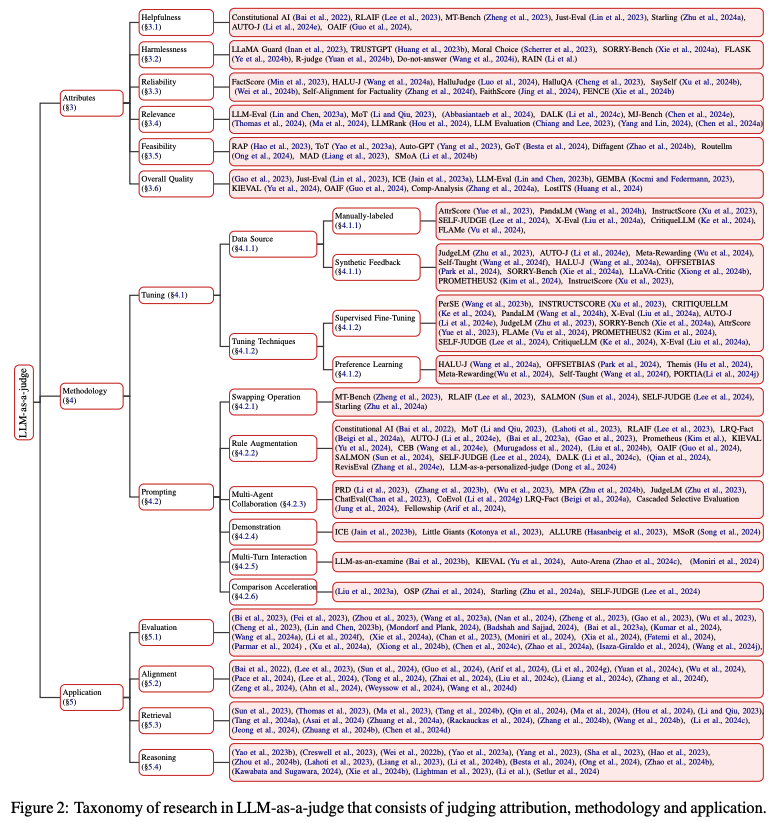
이 연구는 Diptych Prompting이라는 새로운 zero-shot 접근 방식을 제안합니다. Large-scale text-to-image 모델의 diptych generation 특성을 활용하여 정확한 subject alignment를 가진 inpainting 작업으로 재해석하는 방식을 제시합니다. 실험을 통해 기존의 zero-shot image prompting 방법들을 크게 능가하는 성능을 입증했습니다. (https://llm-as-a-judge.github.io)
[저작권자ⓒ META-X. 무단전재-재배포 금지]