AI 기술 발전의 사회적 영향 분석 및 일자리 변화 등 주요 쟁점 부상
주요 모델 및 제품 출시
Anthropic은 새로운 소형 모델인 Claude Haiku 4.5를 공개했다. 이 모델은 Claude Sonnet 4의 성능을 3분의 1 비용으로 제공하며 처리 속도는 2배 빠르다. Haiku 4.5는 Sonnet 4.5가 병렬로 작동하는 Haiku 모델 팀을 조정하는 새로운 다중 에이전트 워크플로우를 가능하게 한다. Google 역시 영상 생성 모델을 업데이트하여 Veo 3.1을 도입했다. 이는 향상된 오디오 출력, 더 나은 프롬프트 준수, 그리고 더 현실적인 비디오 생성을 특징으로 한다. Veo 3.1의 첫 실제 샘플은 이전 버전에서 나타났던 객체 비율의 이상함 같은 문제를 개선하고, 뉘앙스에 대한 더 나은 이해를 통해 프롬프트 의도에 밀접하게 일치하는 비디오를 생성하는 진전을 보였다.
Anthropic은 지침, 스크립트 및 리소스를 포함하는 모듈식의 작업별 패키지인 Claude Skills를 공개했다. 이는 필요할 때만 관련 컨텍스트를 로드하여 Claude를 전문화된 작업에 더 효과적으로 만든다. 이 새로운 스킬 기능은 토큰 효율성이 매우 뛰어나, 필요할 때까지 스킬당 수십 개의 토큰만 소비한다. 이는 수만 개의 토큰을 미리 소모할 수 있는 MCP(Multi-Context Prompting) 방식과 비교된다. 이러한 효율적인 설계는 Claude Code를 일반 자동화 에이전트로 변화시켜 '캄브리아기 대폭발(Cambrian explosion)'을 촉발할 잠재력이 있다. 또한, Anthropic은 개발 워크플로우를 위한 유연한 사용자 지정을 가능하게 하는 Claude Code 플러그인 지원을 도입하여, 사용자가 단일 명령으로 사용자 지정 슬래시 명령, 에이전트 등을 설치할 수 있게 했다.
OpenAI는 쇼핑객들이 ChatGPT를 통해 직접 물품을 구매할 수 있도록 Walmart와 계약을 체결했다. 이 OpenAI의 Instant Checkout 기능은 ChatGPT를 통해 완료된 거래에 대해 회사에 수수료를 부과하는 새로운 수익원이 되고 있다. 또한, OpenAI는 팀 작업 공간 내에 공유 ChatGPT 프롬프트 기능을 개발하여 조직을 대상으로 한다. 이는 팀 구성원이 프롬프트 템플릿을 만들고 복잡한 다단계 작업을 단일 프롬프트로 묶을 수 있도록 지원한다. Claude 역시 Microsoft 365와 통합되어 SharePoint, Outlook 및 Teams에서 검색 기능을 수행하여 기업 워크플로우 내에서 의사 결정을 간소화할 수 있다.
AI 인프라, 하드웨어 및 금융
Nvidia, Microsoft, BlackRock, 그리고 xAI는 Aligned Data Centers를 400억 달러에 인수할 예정이며, 이는 세계 최대 규모의 데이터 센터 거래로 기록될 것이다. 하드웨어 파트너십에서는 AMD가 Oracle과 협력하여 200메가와트의 컴퓨팅 파워에 해당하는 대규모 데이터 센터 클러스터를 구축할 계획이다. AMD는 Oracle이 운영하는 데이터 센터 내에 MI450 칩 50,000개를 배치할 예정이며, 양사는 2027년 이후에도 파트너십을 확장할 계획이다.
Nvidia는 기가와트 규모의 'AI 팩토리' 비전을 공개했으며, 이는 100% 액체 냉각 설계 기반의 Vera Rubin NVL144 아키텍처를 활용한다. Nvidia는 이 Vera Rubin 아키텍처를 Open Compute Project에 기증하여 개방형 표준으로 만들 계획이다. 이에 맞서 AMD는 더 쉬운 서비스 용이성과 Nvidia의 Vera Rubin보다 50% 더 많은 메모리를 제공할 것을 약속하는 Helios 랙 규모 AI 하드웨어 플랫폼을 선보였다. 또한, Meta는 에너지 효율적인 클라우드 AI 배포를 목표로 자사의 AI 시스템을 Arm의 Neoverse 플랫폼으로 이전하고 있다.
GenAI 시장은 현재 수요 주도적이고 자본 집약적인 호황으로, 매출이 매년 두 배로 증가하여 2026년까지 1,000억 달러에 이를 것으로 예상된다. 그러나 자본 지출 대비 매출 비율이 역사적 고점(철도 2배, 통신 4배)을 초과하는 6배에 달하는 등 과열의 징후가 있어 AI 버블에 대한 우려가 제기되고 있다. 특히, Broadcom의 OpenAI에 대한 투자는 OpenAI가 수십억 달러 규모의 데이터 센터 계약을 체결했음에도 불구하고 OpenAI의 예상 매출(130억 달러)이 지출 수준을 정당화하기에 충분하지 않다는 점에서 큰 위험으로 간주된다.

AI 모델 연구 및 엔지니어링 기법
재귀적 언어 모델(RLMs)은 입력 컨텍스트를 변수처럼 분해하고 재귀적으로 상호 작용할 수 있는 능력을 통해 모델의 효율성과 추론 능력을 획기적으로 향상시키는 새로운 아키텍처이다. GPT-5-mini를 사용하는 RLM은 OOLONG 벤치마크에서 GPT-5보다 2배 이상 많은 정답을 능가하면서도 쿼리당 평균 비용이 더 저렴한 결과를 보였다. 재귀적으로 추론하도록 명시적으로 훈련된 RLMs는 일반 목적 추론 시간 확장(inference time scaling)의 다음 이정표가 될 가능성이 높다.
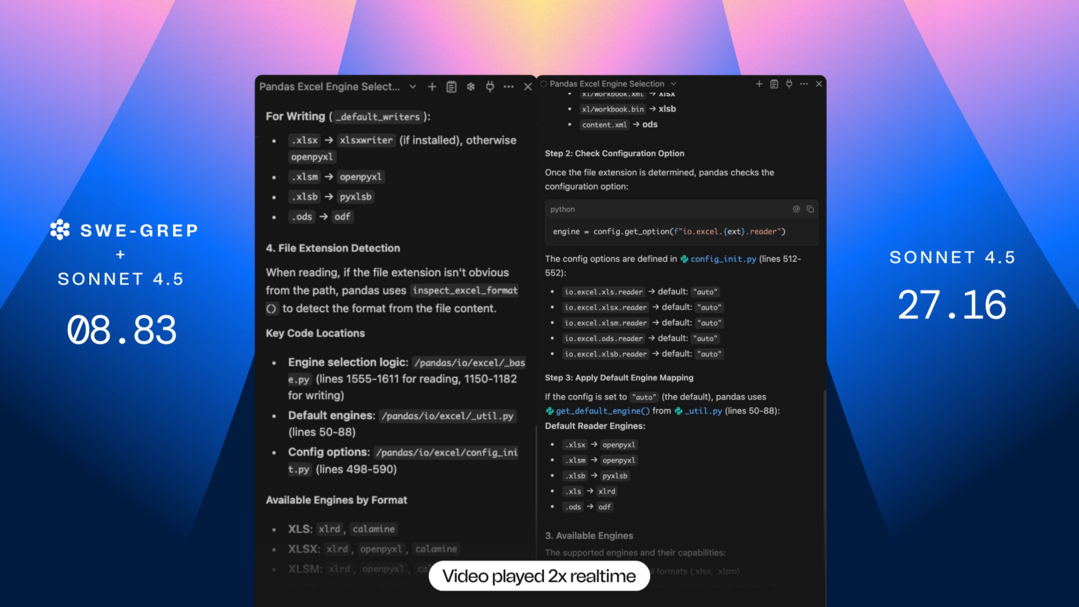
ReasoningBank는 에이전트가 스스로 판단한 성공 및 실패 경험에서 일반화 가능한 추론 전략을 추출하는 새로운 메모리 프레임워크로, 에이전트가 새로운 학습 내용을 통합하여 시간이 지남에 따라 더 유능해지도록 돕는다. Cognition은 일반적인 에이전트가 사용하는 순차적 검색 대신 강화 학습(RL)을 사용하여 턴당 최대 8개의 병렬 도구 호출을 실행하는 전문 모델인 SWE-grep 및 SWE-grep-mini를 훈련했다. 이 모델들은 프론티어 모델보다 코드 컨텍스트를 10배 빠르게 검색한다. Meta는 외부 보상 없이 에이전트 자신의 상호 작용 데이터를 사용하는 훈련 접근 방식인 "초기 경험(early experience)"을 도입하여 정책 학습을 개선했다.
LLM의 탈옥(Jailbreaks) 및 프롬프트 인젝션 문제는 여전히 해결되지 않고 있다. OpenAI, Anthropic, Google DeepMind의 연구원들은 최근의 AI 안전 방어책 12개를 체계적으로 무너뜨리는 적응형 공격을 사용하여 90%가 넘는 성공률을 달성했다. 이러한 공격은 악성 요청을 합법적인 작업의 전제 조건으로 구성하거나('prerequisite' attacks), 고정된 공격 데이터셋에 의존하는 훈련 기반 방어를 우회하는 등 다양한 방식으로 이루어졌다. 한편, Petri는 연구원들이 맞춤형 평가를 몇 주에 걸쳐 구축하는 대신 몇 분 만에 새로운 가설을 테스트할 수 있도록 하는 정렬 감사 에이전트(alignment auditing agent) 역할을 한다.
AI의 광범위한 영향 및 산업 분석
GPT-5 수준 모델은 이제 경제적으로 가치 있는 작업의 약 절반에서 인간 전문가와 능력이 일치하며, 인간에게 몇 시간이 걸릴 작업을 몇 분 만에 완료한다. OpenAI는 AI가 이미 초급 근로자를 대체하고 있다는 증거를 인정하며 2030년까지 미국인 1천만 명을 목표로 하는 재교육 프로그램을 제안했다. 그러나 OpenAI는 재교육 이니셔티브를 제안했음에도 불구하고 AI를 "대체자라기보다는 조력자"로 규정한다. 역사적으로 기술 변화로 인한 일자리 대체(job displacement)를 막는 데 재교육이 실패했다는 점을 고려할 때 이는 논란의 여지가 있다. Anthropic은 AI로 인한 일자리 손실에 대비하기 위한 정책 아이디어로 연간 10,000달러의 고용주 훈련 보조금, AI 생성 콘텐츠에 대한 "토큰세", 시민에게 AI 수익의 지분을 제공하는 국부 펀드를 포함하는 구체적인 제안을 수집했다.
65,000개의 웹 기사 분석에 따르면 AI 생성 콘텐츠가 2024년 11월에 인간이 작성한 기사를 능가했으며, ChatGPT 출시 후 12개월 이내에 거의 0에서 39%로 급증했다. 저자들은 이후의 정체가 낮은 SEO 성능 때문일 수 있다고 추측한다. AI 오류에 대한 대중의 인식은 전통적인 소프트웨어 버그와 유사하다고 가정하지만, AI 실수는 85,000년이 걸릴 방대한 훈련 데이터에서 발생하므로 기존 소프트웨어처럼 문제를 정확히 찾아 영구적으로 수정할 수 없다는 점에서 다르다.
LLM은 소비자 조사 분야에서 새로운 잠재력을 보여주었다. AI는 "의미론적 유사성 평점" 방법을 사용하여 쇼핑객에 대해 많은 것을 알지 못하고도 57가지 개인 관리 제품 전반에 걸쳐 인간 소비자의 선택을 거의 비슷하게 복제할 수 있으며, 인간 재시험 신뢰도의 90%를 달성한다. 이 방법은 LLM이 응답을 작성하게 한 다음 임베딩 유사성을 사용하여 이를 평점 척도에 매핑하며, 이는 연간 수십억 달러에 달하는 소비자 조사 비용을 대체할 수 있다. 또한, ScaleRL은 LLM 강화 학습에서 컴퓨팅 확장을 분석하고 예측하기 위한 프레임워크로, 안정적인 훈련 레시피가 예측 가능한 성능 곡선을 생성하여 효율적인 자원 할당을 돕는다는 것을 보여준다.

[METAX = 김한얼 기자]
[저작권자ⓒ META-X. 무단전재-재배포 금지]