멀티모달 통합과 인간적 상호작용, 만능 AI(AGI)를 향한 도약
TL;DR
AI 자율 학습 및 추론 능력 강화 분야에서는 'Absolute Zero'가 외부 데이터 없이 모델 스스로 추론 과제를 생성하고 코드 실행기로 검증하며 코딩 및 수학 추론 능력을 SOTA 수준으로 향상시키는 패러다임을 제시한다. 유사하게 'Grokking in the Wild'는 합성 데이터 증강을 통해 트랜스포머가 희소한 실제 데이터 환경에서도 다단계 사실 추론 패턴(그로킹)을 학습하도록 유도한다. 'ZeroSearch'는 실제 검색 엔진 없이 LLM 자체를 검색 모듈로 변환하고 강화학습으로 검색 능력을 강화하여 비용과 불안정성 문제를 해결한다.
멀티모달 AI와 인간-AI 상호작용 분야에서는 'Voila'가 낮은 지연 시간과 풍부한 감정 표현으로 실시간 자율 상호작용 및 음성 역할극이 가능한 음성-언어 파운데이션 모델을 제안하며 오픈소스로 공개된다. 한편, 'Unified Multimodal Understanding and Generation Models' 서베이 논문은 이미지 이해(자기회귀)와 생성(확산) 모델의 아키텍처 차이를 극복하고 통합하려는 다양한 시도와 과제를 분석한다. 'On Path to Multimodal Generalist' 프로젝트는 MLLM의 일반성을 평가하는 'General-Level' 프레임워크와 'General-Bench' 벤치마크를 통해 진정한 멀티모달 만능 AI 및 AGI로의 진척도를 측정한다.
연쇄적 사고(CoT) 및 강화학습(RL)을 통한 모델 성능 최적화 분야에서는 'UnifiedReward-Think'가 멀티모달 RM에 명시적인 연쇄적 사고(CoT)를 통합하고 강화 미세조정을 통해 보상 추론의 깊이를 더한다. 'RM-R1'은 보상 모델링 자체를 추론 작업으로 정의하여 CoT 기반 생성적 RM이 스스로 평가 기준을 만들고 응답을 평가하도록 한다. 'Flow-GRPO'는 플로우 매칭 이미지 생성 모델에 온라인 강화학습을 최초로 통합하여, ODE-SDE 변환과 노이즈 제거 감소 전략으로 복잡한 이미지 생성 품질을 크게 향상시키면서도 보상 해킹 문제를 최소화하는 성과를 보였다.
1.AI 자율 학습 및 추론 능력 강화 분야
Absolute Zero: Reinforced Self-play Reasoning with Zero Data
https://arxiv.org/abs/2505.03335
기존의 검증 가능한 보상 기반 강화학습(RLVR) 연구들이 추론 과정에 대한 인간의 직접적인 감독은 피하면서도, 훈련을 위해서는 여전히 수동으로 선별된 질문과 답변 모음에 의존했던 한계를 지적하며, '앱솔루트 제로'는 어떠한 외부 데이터의 도움 없이 단일 모델 스스로가 자신의 학습 진행을 극대화할 수 있는 작업을 제안하고 이를 해결함으로써 추론 능력을 향상시키는 새로운 패러다임을 제시한다. 이 패러다임 하에 제안된 '앱솔루트 제로 리즈너(AZR)' 시스템은 코드 실행기를 활용하여, 모델이 제안한 코드 추론 작업의 유효성을 검증하고 생성된 답변을 확인함으로써, 개방적이면서도 근거 있는 학습을 안내하는 통합된 검증 가능한 보상의 원천으로 삼아 자체적으로 훈련 커리큘럼과 추론 능력을 진화시킨다. 놀랍게도 AZR은 전적으로 외부 데이터 없이 훈련되었음에도 불구하고 코딩 및 수학 추론 작업에서 전반적인 최고 성능(SOTA)을 달성하며, 수만 개의 관련 분야 인간 데이터를 사용한 기존 제로 세팅 모델들을 능가하는 성과를 보이고, 다양한 모델 규모와 종류에 효과적으로 적용될 수 있음을 입증한다.

Grokking in the Wild: Data Augmentation for Real-World Multi-Hop Reasoning with Transformers
https://arxiv.org/abs/2504.20752
트랜스포머가 수많은 자연어 처리 작업에서 큰 성공을 거두었음에도 불구하고, 실제 세계의 지식이 희소할 경우 여러 단계를 거쳐야 하는 사실적 추론(multi-step factual reasoning)에는 여전히 눈에 띄는 한계를 보인다는 문제점에서 출발하여, 이 연구는 최근 신경망이 기저의 논리적 패턴을 감지하면 단순 암기에서 완벽한 일반화로 전환될 수 있음을 보여준 '그로킹(grokking)' 현상을 실제 사실 데이터로 확장한다. 특히 데이터셋의 희소성 문제를 해결하기 위해 기존 지식 그래프에 의도적으로 설계된 합성 데이터를 증강하여, 추론된 사실 대 원자적(atomic) 사실의 비율(phi_r)을 그로킹 발생에 필요한 임계값 이상으로 높이는 전략을 사용하며, 놀랍게도 사실적으로는 틀린 합성 데이터조차 모델이 단순 암기에 의존하기보다 관계 구조에 집중하도록 강제함으로써 정확도를 저해하기보다는 오히려 추론 회로를 강화할 수 있음을 발견한다. 이러한 접근법은 다단계 추론 벤치마크인 2WikiMultiHopQA에서 최대 95-100%의 정확도를 달성하여 강력한 기준 모델들을 크게 능가하고 현재 최고 수준의 결과를 맞추거나 초과하며, phi_r 비율 증가가 트랜스포머 내부에 일반화 회로 형성을 어떻게 촉진하는지에 대한 심층 분석을 제공하여 그로킹 기반 데이터 증강이 대규모 언어 모델의 암묵적인 다단계 추론 능력을 발현시켜 더 강건하고 해석 가능한 사실 추론의 문을 열 수 있음을 시사한다.
ZeroSearch: Incentivize the Search Capability of LLMs without Searching
https://arxiv.org/abs/2505.04588
대형 언어 모델(LLM)의 추론 및 생성 능력 향상에 필수적인 효과적인 정보 검색 능력을 강화하기 위해 최근 연구들이 실제 검색 엔진과 상호작용하며 강화학습(RL)을 사용하는 방식을 탐색해왔으나, 이러한 접근법들은 (1) 검색 엔진이 반환하는 문서 품질이 예측 불가능하여 훈련 과정에 노이즈와 불안정성을 야기하는 '제어 불가능한 문서 품질' 문제와 (2) RL 훈련 시 수십만 건의 검색 요청이 필요할 수 있어 막대한 API 비용을 발생시키고 확장성을 심각하게 제한하는 '엄청난 API 비용' 문제라는 두 가지 주요 난관에 직면한다. 이러한 문제를 해결하기 위해, 'ZeroSearch'는 실제 검색 엔진과의 상호작용 없이 LLM의 검색 능력을 강화하는 새로운 강화학습 프레임워크를 제안하는데, 이 접근법은 먼저 가벼운 지도 미세조정(SFT)을 통해 LLM 자체를 쿼리에 대해 관련성 높은 문서와 노이즈가 섞인 문서를 모두 생성할 수 있는 검색 모듈로 변환하고, RL 훈련 단계에서는 생성된 문서의 품질을 점진적으로 낮추는 커리큘럼 기반 롤아웃 전략을 사용하여 모델을 점점 더 어려운 검색 시나리오에 노출시킴으로써 추론 능력을 점진적으로 끌어낸다. 광범위한 실험을 통해 ZeroSearch는 3B 크기의 LLM을 검색 모듈로 사용했을 때 효과적으로 LLM의 검색 능력을 강화함을 보여주었고, 특히 7B 검색 모듈은 실제 검색 엔진과 유사한 성능을, 14B 검색 모듈은 이를 능가하는 성능을 달성했으며, 다양한 매개변수 크기의 기본 모델 및 명령어 튜닝 모델 전반에 걸쳐 잘 일반화되고 광범위한 RL 알고리즘과 호환됨을 입증한다.
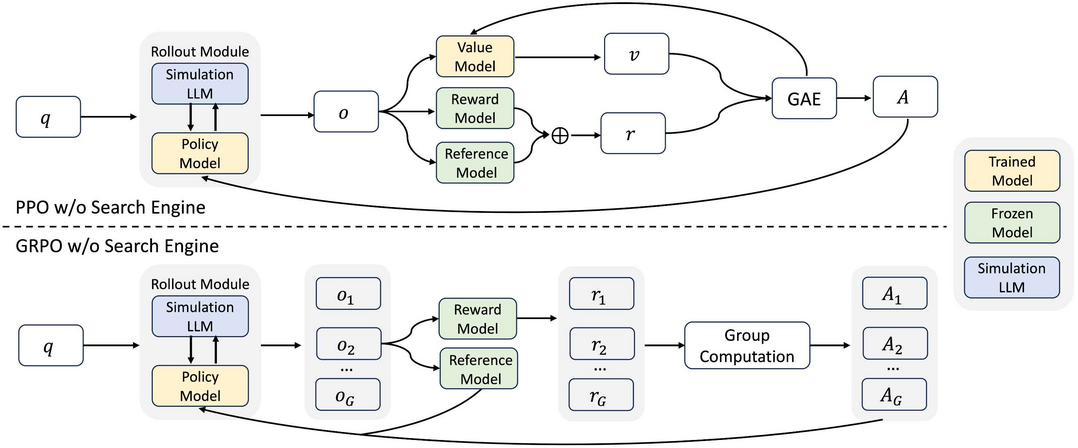
2.멀티모달 AI와 인간-AI 상호작용 분야
Voila: Voice-Language Foundation Models for Real-Time Autonomous Interaction and Voice Role-Play
https://arxiv.org/abs/2505.02707
단순한 명령어에 반응하는 것을 넘어, 마치 인간처럼 일상생활에 자연스럽게 녹아들어 지속적으로 듣고, 추론하고, 선제적으로 반응하며, 감정을 풍부하게 표현하는 자율적이고 실시간 상호작용이 가능한 음성 AI 에이전트의 비전을 제시하며, 'Voila'는 이러한 목표를 향해 나아가는 대규모 음성-언어 파운데이션 모델군이다. Voila는 전통적인 파이프라인 시스템의 한계를 극복하기 위해, 양방향(full-duplex) 대화를 지원하고 평균 인간 반응 시간보다 빠른 195밀리초의 낮은 응답 지연 시간을 달성하면서도 말투, 리듬, 감정 같은 풍부한 음성 뉘앙스를 보존하는 새로운 종단간(end-to-end) 아키텍처를 채택한다. 이 아키텍처의 핵심인 계층적 다중 스케일 트랜스포머는 대형 언어 모델(LLM)의 추론 능력과 강력한 음향 모델링을 통합하여, 사용자가 텍스트 지침만으로 화자의 정체성, 톤, 기타 특성을 정의할 수 있는 자연스럽고 페르소나를 인식하는 음성 생성을 가능하게 한다. 더불어 Voila는 100만 개 이상의 사전 구축된 음성을 지원하고 10초 정도의 짧은 오디오 샘플만으로도 새로운 음성을 효율적으로 맞춤 설정할 수 있으며, 음성 대화뿐만 아니라 자동 음성 인식(ASR), 텍스트 음성 변환(TTS), 그리고 최소한의 조정을 통해 다국어 음성 번역까지 포괄하는 광범위한 음성 기반 애플리케이션을 위한 통합 모델로 설계되어, 개방형 연구 지원과 차세대 인간-기계 상호작용 발전을 가속화하기 위해 완전 오픈소스로 공개된다.
Unified Multimodal Understanding and Generation Models: Advances, Challenges, and Opportunities
https://arxiv.org/abs/2505.02567
최근 몇 년간 멀티모달 '이해' 모델(예: 이미지를 보고 설명하는 모델)과 이미지 '생성' 모델(예: 텍스트를 기반으로 이미지를 만드는 모델) 양쪽 모두 놀라운 발전을 이루었지만, 이 두 영역은 각자의 성공에도 불구하고 독립적으로 발전하여 서로 다른 아키텍처 패러다임을 형성해왔는데, 멀티모달 이해는 주로 자기회귀(autoregressive) 기반 아키텍처가, 이미지 생성은 확산(diffusion) 기반 모델이 주류를 이루었다. GPT-4o의 새로운 기능 등장에서 알 수 있듯 최근 이러한 작업들을 통합하려는 관심이 증가하고 있으나 두 영역 간의 아키텍처 차이로 인해 상당한 어려움이 존재하며, 이에 본 서베이 논문은 통합을 향한 현재의 노력에 대한 명확한 개요를 제공하여 미래 연구를 안내하고자 한다. 먼저, 멀티모달 이해 및 텍스트-이미지 생성 모델의 기초 개념과 최근 발전 사항을 소개한 후, 기존 통합 모델들을 확산 기반, 자기회귀 기반, 그리고 이 둘을 융합한 하이브리드 접근법이라는 세 가지 주요 아키텍처 패러다임으로 분류하여 각 범주별 관련 연구들의 구조적 설계와 혁신을 분석한다. 추가적으로, 통합 모델에 특화된 데이터셋과 벤치마크를 정리하여 향후 탐색을 위한 자원을 제공하고, 마지막으로 토큰화 전략, 교차 모달 어텐션, 데이터 등 이 초기 단계 분야가 직면한 주요 과제들을 논의하며, 이 분야의 빠른 발전을 예상하여 본 서베이를 정기적으로 업데이트함으로써 커뮤니티에 귀중한 참고 자료를 제공하고 추가 연구를 장려하는 것을 목표로 한다.
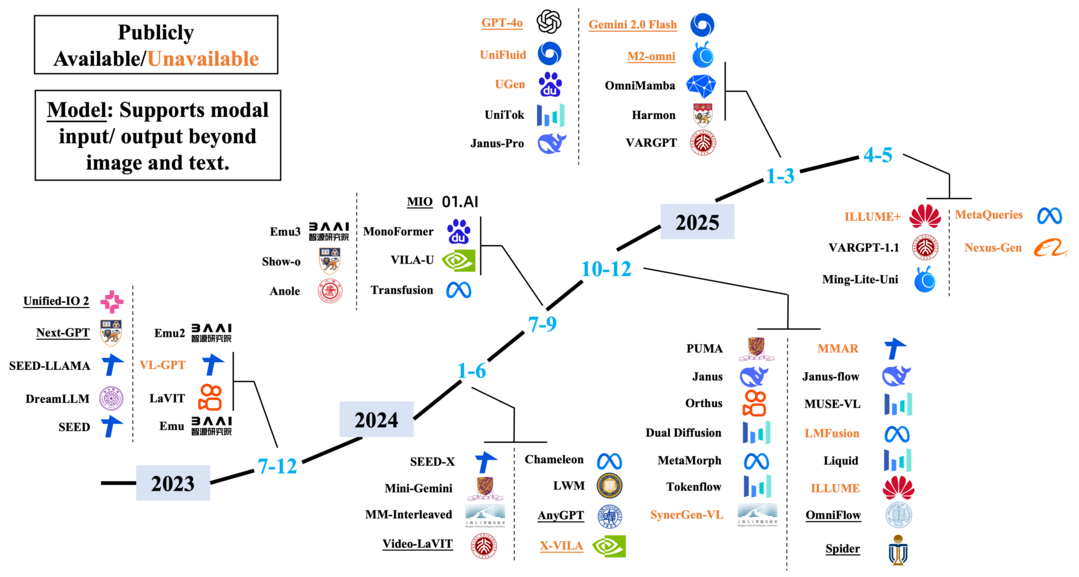
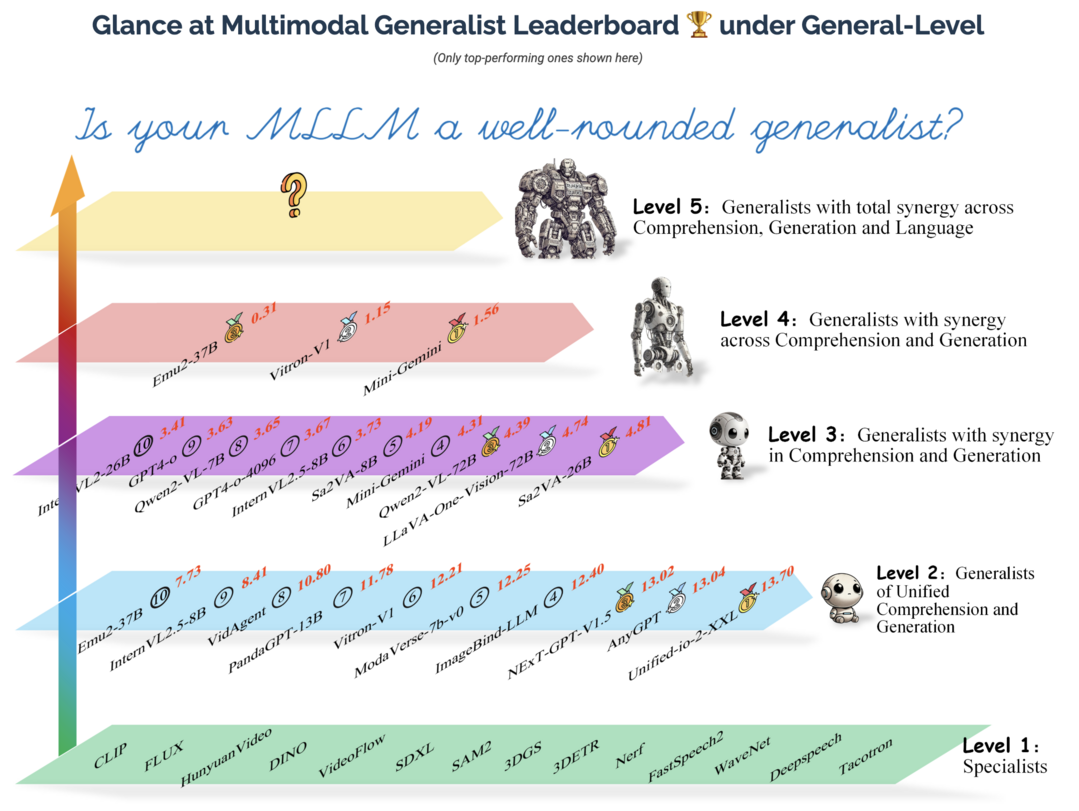
On Path to Multimodal Generalist: General-Level and General-Bench
https://arxiv.org/abs/2505.04620
대형 언어 모델(LLM)의 발전된 능력에 힘입어 현재 빠르게 성장하고 있는 멀티모달 대형 언어 모델(MLLM)이 초기 특정 작업 전문가 형태를 넘어 '멀티모달 제너럴리스트(다양한 종류의 데이터를 이해하고 생성하는 만능 AI)' 패러다임으로 진화하고 있으며, 이들 모델은 단순히 여러 종류의 데이터를 이해하는 것에서 나아가 여러 종류의 데이터를 이해하고 생성하는 수준으로 발전했고, 그 능력 또한 거시적(coarse-grained) 이해에서 미시적(fine-grained) 이해로, 제한된 종류의 데이터 지원에서 임의의 데이터 지원으로 확장되고 있다. 하지만 수많은 MLLM 평가 벤치마크가 존재함에도 불구하고, "여러 작업에서 단순히 높은 성능을 보인다고 해서 MLLM의 능력이 더 강하고, 이것이 우리를 인간 수준 AI(AGI)에 더 가깝게 만드는가?"라는 중요한 질문에 대한 답은 간단하지 않다는 문제의식에서 출발하여, 이 프로젝트는 MLLM의 성능과 일반성(generality)을 5단계로 정의하는 평가 프레임워크 '제너럴-레벨(General-Level)'을 소개하고, 이를 통해 MLLM들을 비교하며 기존 시스템들이 더 강건한 멀티모달 제너럴리스트, 궁극적으로는 AGI로 나아가는 진척도를 측정하는 방법론을 제공한다. 이 프레임워크의 핵심에는 모델이 이해와 생성, 그리고 여러 종류의 데이터에 걸쳐 일관된 능력을 유지하는지를 측정하는 '시너지(Synergy)' 개념이 있으며, 이러한 평가를 지원하기 위해 700개 이상의 작업과 325,800개의 인스턴스를 포함하여 더 넓은 스펙트럼의 기술, 데이터 종류, 형식, 능력을 포괄하는 '제너럴-벤치(General-Bench)'를 함께 제시하여, 100개 이상의 최신 MLLM 평가를 통해 제너럴리스트들의 능력 순위를 밝히고 진정한 AI 도달의 어려움을 조명함으로써 차세대 멀티모달 파운데이션 모델 연구의 길을 열고 AGI 실현을 가속화할 견고한 기반 시설을 제공할 것으로 기대한다.
3.연쇄적 사고(CoT) 및 강화학습(RL)을 통한 모델 성능 최적화 분야
Unified Multimodal Chain-of-Thought Reward Model through Reinforcement Fine-Tuning
https://arxiv.org/abs/2505.03318
현재 멀티모달 보상 모델(RM)들이 주로 직접적인 응답을 제공하거나 깊이가 얕은 추론 과정에 머물러 부정확한 보상 신호를 산출하는 경우가 많다는 문제의식에서 출발하여, 'UnifiedReward-Think'는 보상 추론 과정에 명시적인 긴 연쇄적 사고(Chain-of-Thought, CoT)를 통합함으로써 보상 모델의 신뢰성과 강건성을 크게 강화하고, 나아가 일단 RM이 CoT 추론을 내재화하면 암묵적 추론 능력을 통해 직접 응답 정확도 역시 향상될 수 있다는 가설을 검증한다. 이를 위해 제안된 모델은 탐색 중심의 강화 미세조정 접근법을 채택하는데, 구체적으로 (1) 소량의 이미지 생성 선호도 데이터를 사용하여 GPT-4o의 추론 과정을 증류(distill)함으로써 모델이 CoT 추론의 형식과 구조를 학습하는 콜드 스타트 단계를 거치고, (2) 이후 모델의 사전 지식과 일반화 능력을 활용해 대규모 통합 멀티모달 선호도 데이터를 준비하여 다양한 비전 작업에 걸쳐 모델의 추론 과정을 유도하며 이때 올바른 추론 결과는 모델 정제를 위한 거부 샘플링(rejection sampling)에 활용하고, (3) 마지막으로 부정확하게 예측된 샘플들은 GRPO(Group Relative Policy Optimization) 기반 강화 미세조정에 사용하여 모델이 다양한 추론 경로를 탐색하고 정확하며 강건한 해결책을 찾도록 최적화함으로써 다양한 비전 보상 작업에서 우수성을 보인다.

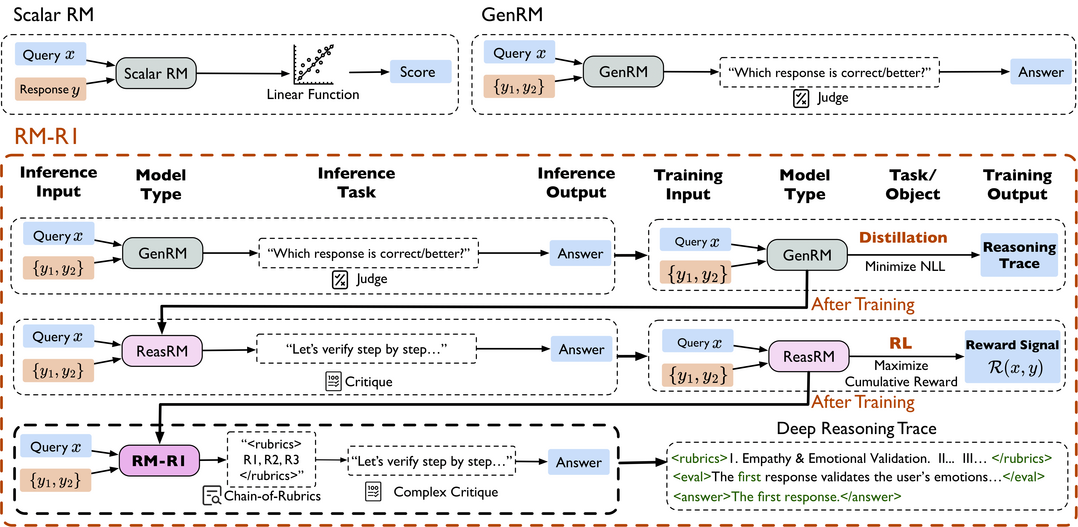
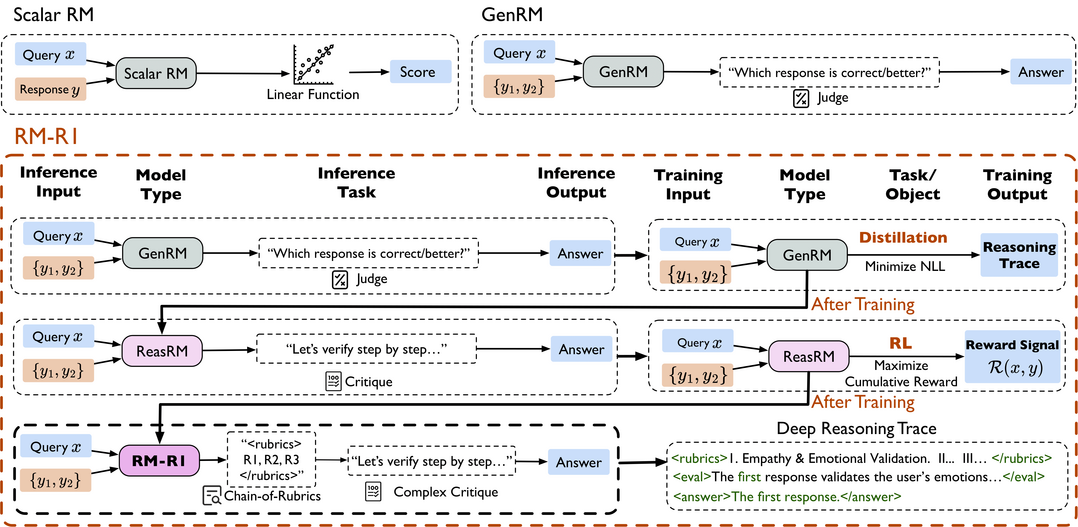
RM-R1: Reward Modeling as Reasoning
https://arxiv.org/abs/2505.02387
대형 언어 모델(LLM)을 인간의 선호도에 맞게 조정하는, 특히 인간 피드백 기반 강화학습(RLHF)의 핵심 요소인 보상 모델링(Reward Modeling)이 정확한 보상 신호를 제공하기 위해서는 단순한 점수나 판단을 내리기 전에 깊이 있는 사고와 해석 가능한 추론 과정을 거쳐야 한다는 전제에서 출발한다. 기존 보상 모델(RM)들이 불투명한 단일 점수를 생성하거나 선호 답변을 직접 예측함으로써 자연어 형태의 비평을 통합하기 어렵고 해석 가능성이 부족했던 문제를 해결하기 위해, 이 연구는 긴 연쇄적 사고(CoT)가 추론 집약적 작업에서 보여준 최근의 발전에 영감을 받아 보상 모델링에 추론 능력을 통합하는 것이 RM의 해석 가능성과 성능을 크게 향상시킨다는 가설을 검증하며, 보상 모델링 자체를 하나의 '추론 작업'으로 공식화하는 새로운 종류의 생성적 보상 모델인 '추론 보상 모델(ReasRMs)'과 그 모델군 'RM-R1'을 제안한다. RM-R1의 훈련은 (1) 고품질 추론 연쇄를 증류하는 단계와 (2) 검증 가능한 보상을 통한 강화학습 단계로 구성되며, LLM의 결과물에 대해 스스로 추론 과정이나 대화별 평가 기준(rubric)을 생성하고 이를 바탕으로 후보 응답들을 평가함으로써, 여러 종합적인 보상 모델 벤치마크에서 기존 최고 수준(SOTA) 또는 이에 준하는 성능을 달성하고 훨씬 큰 공개 가중치 모델이나 상용 모델보다도 우수한 결과를 보인다.
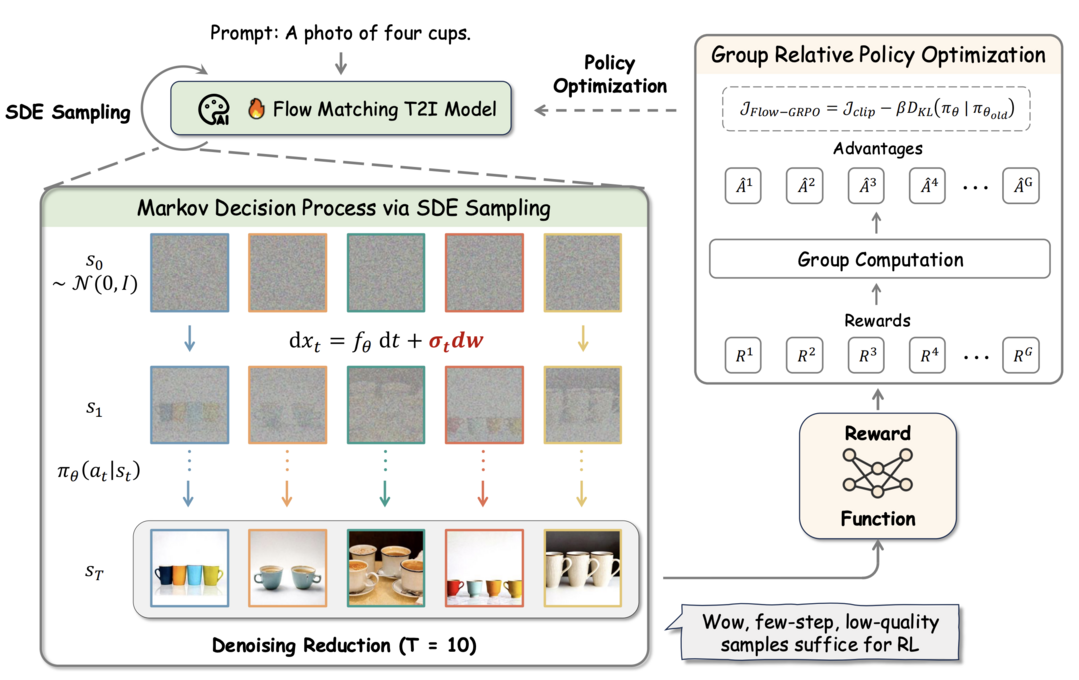
Flow-GRPO: Training Flow Matching Models via Online RL
https://arxiv.org/abs/2505.05470
이미지 생성 등에 활용되는 플로우 매칭 모델(Flow Matching Models)에 온라인 강화학습(RL)을 최초로 통합하는 방법론인 'Flow-GRPO'를 제안하며, 이 접근법은 두 가지 핵심 전략을 사용한다: (1) 결정론적인 상미분방정식(ODE)을, 모든 시간 단계에서 원본 모델의 주변 분포와 일치하는 등가의 확률미분방정식(SDE)으로 변환하는 'ODE-SDE 변환' 전략을 통해 RL 탐색을 위한 통계적 샘플링을 가능하게 하고, (2) 추론 시 사용되는 시간 단계 수는 그대로 유지하면서 훈련 과정에서의 노이즈 제거 단계를 줄이는 '노이즈 제거 감소(Denoising Reduction)' 전략을 통해 성능 저하 없이 샘플링 효율을 크게 향상시킨다. 실험 결과, Flow-GRPO는 여러 텍스트-이미지 변환 작업에서 효과적이었으며, 특히 복잡한 구성의 이미지 생성에서 강화학습으로 튜닝된 SD3.5 모델은 물체 개수, 공간 관계, 세부 속성 등을 거의 완벽하게 생성하여 GenEval 정확도를 63%에서 95%로 대폭 향상시켰고, 시각적 텍스트 렌더링 정확도 역시 59%에서 92%로 개선되어 텍스트 생성을 크게 향상시켰다. 또한 Flow-GRPO는 인간 선호도 정렬에서도 상당한 개선을 달성했으며, 주목할 점은 실험 과정에서 이미지 품질이나 다양성을 희생시키면서 보상 점수만 높아지는 '보상 해킹(reward hacking)' 현상이 거의 발생하지 않고 두 요소 모두 안정적으로 유지되었다는 점이다.
[METAX = 김한얼 기자]
[저작권자ⓒ META-X. 무단전재-재배포 금지]