생성형 AI는 다국어 음성·3D 에셋 창조를 넘어, 특정 언어 최적화 및 경량 모델로 기술 혁신과 접근성 확장
TL;DR
시각 정보와 언어 정보를 통합적으로 이해하고 상호작용하는 멀티모달 AI 분야는 (Seed1.5-VL, BLIP3-o, DeCLIP 등의 연구를 통해) 단순한 정보의 결합을 넘어, GUI 제어나 게임 플레이와 같은 복잡한 에이전트 작업을 수행하고 개방된 어휘 환경에서도 정교한 시각적 인식을 달성하는 등 인간과 유사한 방식으로 세상을 이해하고 소통하는 능력을 목표로 발전하고 있다. 이와 함께, 대규모 언어 모델의 핵심 지능인 추론 기능을 강화하려는 노력 또한 활발히 이루어져 (MiMo, Beyond 'Aha!' 같은 연구들을 통해) 수학 문제 해결, 프로그래밍, 일반 상식 추론 능력 향상은 물론, 자기 교정이나 논리적 검증과 같은 고차원적인 사고 과정을 모델에 내재화함으로써 더욱 신뢰할 수 있고 심도 있는 문제 해결 능력을 갖추도록 진화하고 있다. 한편, 텍스트를 넘어 다채로운 형태의 콘텐츠를 창조하는 생성형 AI 기술은 (MiniMax-Speech, Step1X-3D 등의 연구에서 나타나듯이) 고품질의 다국어 음성을 즉석에서 자연스럽게 합성하거나, 사용자의 의도에 맞춰 정교하고 제어 가능한 3D 에셋을 생성하는 수준에 도달하며 예술, 디자인, 엔터테인먼트 등 다양한 창의적 분야에서 혁신적인 도구로 자리매김하고 있다. 마지막으로, 폴란드어와 같이 특정 언어 처리에 최적화되거나 (Bielik v3 연구처럼) 모델의 크기를 줄여 자원 효율성을 극대화하는 경량화 모델 연구 역시 중요한 흐름으로, AI 기술의 보편적인 접근성을 높이고 제한된 환경에서도 고성능 AI를 활용할 수 있는 길을 열어주며 기술 민주화에 기여하고 있다.
1.멀티모달 AI 분야
Seed1.5-VL Technical Report
https://arxiv.org/abs/2505.07062
이 논문은 Seed1.5-VL이라는 새로운 비전-언어 파운데이션 모델을 소개한다. 이 모델은 일반적인 멀티모달(시각 정보와 언어 정보를 함께 이해하는 능력) 이해 및 추론 능력을 향상시키기 위해 설계되었다. Seed1.5-VL은 5억 3200만 개의 파라미터를 가진 비전 인코더와 200억 개의 활성 파라미터를 가진 전문가 혼합(MoE) 대규모 언어 모델(LLM)로 구성되어 있다. 상대적으로 작은 구조임에도 불구하고, 60개의 공개 비전-언어 모델 벤치마크 중 38개에서 최고 수준의 성능(SOTA)을 달성했다. 특히, 그래픽 사용자 인터페이스(GUI) 제어나 게임 플레이와 같은 에이전트 중심 작업에서는 OpenAI의 CUA나 Claude 3.7과 같은 주요 멀티모달 시스템보다 뛰어난 성능을 보인다. 또한, 시각적 퍼즐과 같은 멀티모달 추론 문제 해결에도 강점을 보여 다양한 분야에서의 응용 가능성을 제시한다.
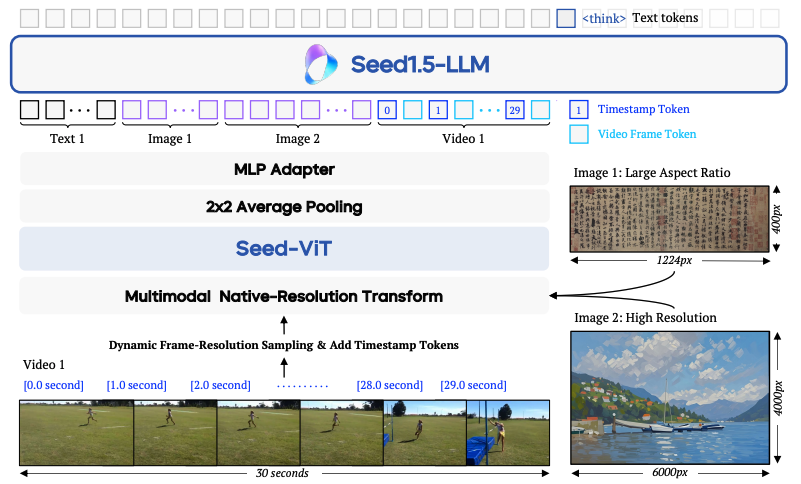
BLIP3-o: A Family of Fully Open Unified Multimodal Models-Architecture, Training and Dataset
https://arxiv.org/abs/2505.09568
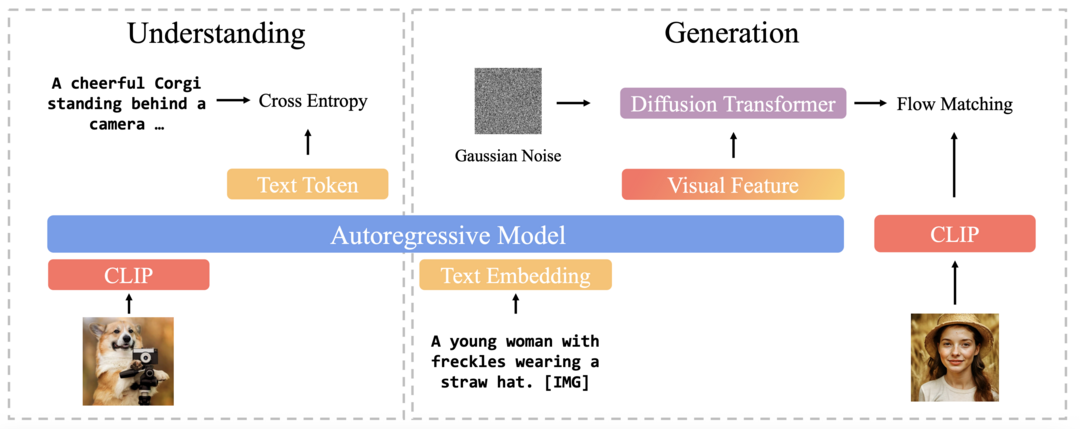
최근 멀티모달 모델 연구에서 이미지 이해와 생성을 통합하려는 시도가 주목받고 있다. 이미지 이해를 위한 설계는 많이 연구되었지만, 이미지 생성까지 포함하는 통합 프레임워크를 위한 최적의 모델 아키텍처와 훈련 방식은 아직 충분히 탐구되지 않았다. 이 연구는 고품질 생성 및 확장성 측면에서 자동 회귀 모델과 확산 모델의 강력한 잠재력에 주목하여, 이미지 표현, 모델링 목표, 훈련 전략을 중심으로 통합 멀티모달 환경에서의 활용 방안을 포괄적으로 연구한다. 이를 바탕으로, 기존의 VAE(Variational Autoencoder) 기반 표현 방식과 달리, 의미적으로 풍부한 CLIP 이미지 특징을 생성하기 위해 확산 트랜스포머를 사용하는 새로운 접근 방식을 제안한다. 이 설계는 훈련 효율성과 생성 품질 모두를 향상시킨다. 또한, 통합 모델을 위한 순차적 사전 훈련 전략(이미지 이해 능력 우선 학습 후 이미지 생성 능력 학습)이 이미지 이해 능력은 유지하면서 강력한 이미지 생성 능력을 개발하는 데 실용적인 이점을 제공함을 보여준다. 마지막으로, 다양한 장면, 객체, 인간 제스처 등을 포괄하는 다양한 캡션을 GPT-4o에 입력하여 이미지 생성을 위한 고품질 명령어 튜닝 데이터셋인 BLIP3o-60k를 신중하게 구축했다. 이러한 혁신적인 모델 설계, 훈련 방식, 데이터셋을 기반으로 최첨단 통합 멀티모달 모델 제품군인 BLIP3-o를 개발했다. BLIP3-o는 이미지 이해 및 생성 작업을 아우르는 대부분의 주요 벤치마크에서 뛰어난 성능을 달성했다.
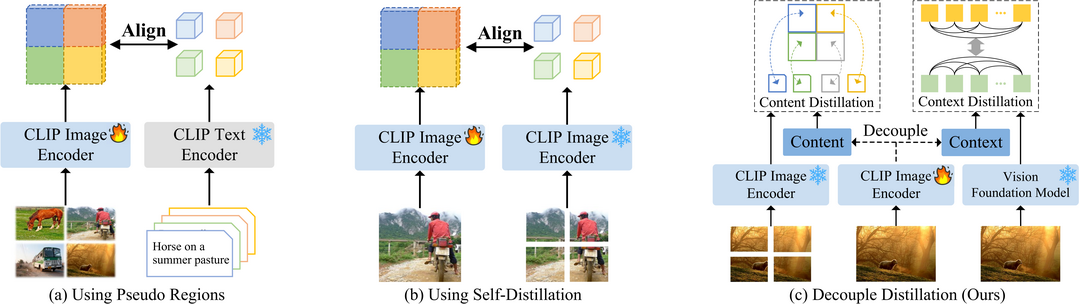
DeCLIP: Decoupled Learning for Open-Vocabulary Dense Perception
https://arxiv.org/abs/2505.04410
밀도 높은 시각 예측 작업은 미리 정의된 범주에 의존하는 한계 때문에 시각적 개념이 무한한 실제 환경에서의 적용 가능성이 제한되어 왔다. CLIP과 같은 비전-언어 모델(VLM)은 개방형 어휘 작업에서 가능성을 보여주었지만, 지역적 특징 표현의 한계로 인해 밀도 예측 작업에 직접 적용하면 최적의 성능을 내지 못하는 경우가 많다. 이 연구에서는 CLIP의 이미지 토큰이 공간적으로나 의미적으로 관련된 영역의 정보를 효과적으로 종합하는 데 어려움을 겪어, 결과적으로 지역적 구별성과 공간적 일관성이 부족한 특징을 생성한다는 관찰 결과를 제시한다. 이러한 문제를 해결하기 위해, 본 연구는 DeCLIP이라는 새로운 프레임워크를 제안한다. DeCLIP은 자기 주의(self-attention) 모듈을 분리하여 "내용(content)" 특징과 "맥락(context)" 특징을 각각 얻는 방식으로 CLIP을 향상시킨다. "내용" 특징은 이미지의 잘라낸 부분(crop) 표현과 정렬되어 지역적 구별성을 높이는 반면, "맥락" 특징은 DINO와 같은 비전 파운데이션 모델의 지도를 받아 공간적 상관관계를 유지하도록 학습한다. 광범위한 실험을 통해 DeCLIP은 객체 감지 및 의미론적 분할을 포함한 여러 개방형 어휘 밀도 예측 작업에서 기존 방법들을 훨씬 능가하는 성능을 보여준다.
2.추론 기능 강화 분야
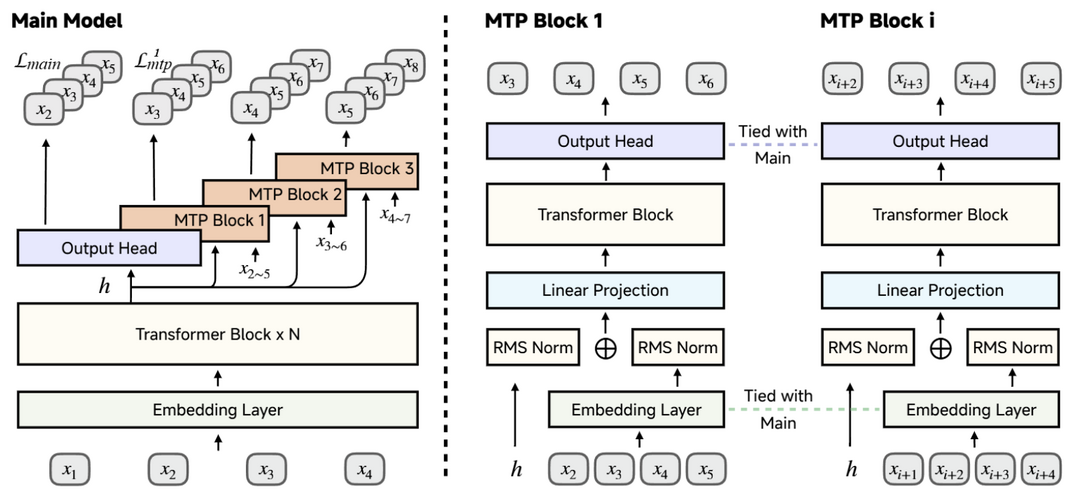
MiMo: Unlocking the Reasoning Potential of Language Model -- From Pretraining to Posttraining
https://arxiv.org/abs/2505.07608
이 논문은 추론 작업에 특화된 대규모 언어 모델 MiMo-7B를 소개하며, 사전 학습과 사후 학습 단계 모두에서 최적화를 거쳤다. 사전 학습 단계에서는 데이터 전처리 과정을 개선하고 3단계 데이터 혼합 전략을 사용하여 기본 모델의 추론 잠재력을 강화했다. MiMo-7B-Base는 25조 개의 토큰으로 사전 학습되었으며, 성능 향상과 추론 속도 가속화를 위해 다중 토큰 예측 목표를 추가로 사용했다. 사후 학습 단계에서는 강화 학습을 위해 검증 가능한 수학 및 프로그래밍 문제 13만 개로 구성된 데이터셋을 구축하고, 희소 보상 문제를 완화하기 위해 테스트 난이도 기반 코드 보상 체계를 통합했으며, 학습 안정화를 위해 전략적 데이터 리샘플링을 사용했다. 광범위한 평가 결과, MiMo-7B-Base는 훨씬 큰 32B 모델보다도 뛰어난 추론 잠재력을 보여주었다. 최종적으로 강화 학습으로 미세 조정한 MiMo-7B-RL 모델은 수학, 코드, 일반 추론 작업에서 OpenAI의 o1-mini 모델을 능가하는 우수한 성능을 달성했다.
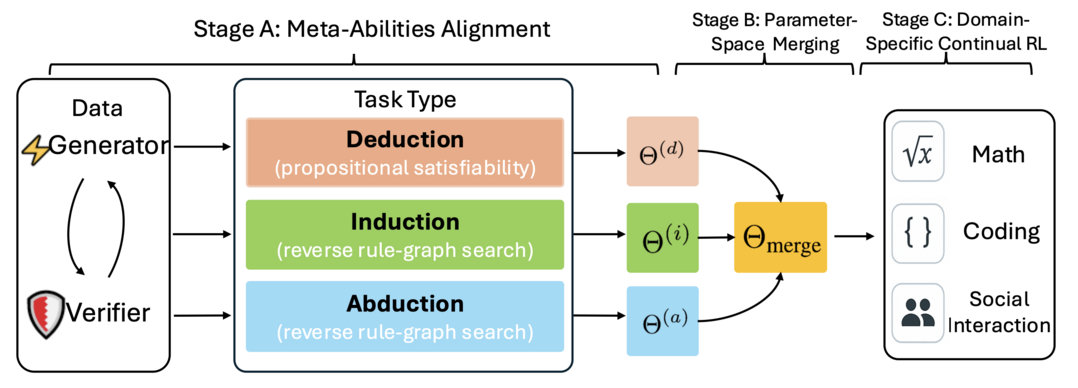
Beyond 'Aha!': Toward Systematic Meta-Abilities Alignment in Large Reasoning Models
https://arxiv.org/abs/2505.10554
대규모 추론 모델(LRM)은 이미 긴 연쇄 사고 추론을 위한 잠재적인 능력을 가지고 있다. 이전 연구들은 결과 기반 강화 학습(RL)이 자기 교정, 백트래킹, 검증과 같은 고급 추론 행동(종종 모델의 "아하 모멘트"라고 불림)을 우연히 이끌어낼 수 있음을 보여주었다. 그러나 이러한 행동의 발생 시점과 일관성은 예측하고 제어하기 어려워 LRM의 추론 능력 확장성과 신뢰성을 제한한다. 이러한 한계를 해결하기 위해, 이 연구는 프롬프트나 우연한 "아하 모멘트"에 의존하는 것을 넘어, 자동으로 생성되고 자체 검증 가능한 작업을 사용하여 연역, 귀납, 귀추라는 세 가지 메타 능력에 모델을 명시적으로 정렬한다. 연구팀의 3단계 파이프라인(개별 정렬, 매개변수 공간 병합, 도메인별 강화 학습)은 명령어 기반으로 미세 조정한 모델보다 성능을 10% 이상 향상시켰다. 나아가, 정렬된 체크포인트에서 특정 분야(수학, 코딩, 과학)에 대한 강화 학습을 적용하면 벤치마크에서 평균 2%의 추가적인 성능 향상을 보였다. 이는 명시적인 메타 능력 정렬이 추론 능력을 위한 확장 가능하고 신뢰할 수 있는 기반을 제공한다는 것을 보여준다.
3. 생성형 AI 기술 분야
MiniMax-Speech: Intrinsic Zero-Shot Text-to-Speech with a Learnable Speaker Encoder
https://arxiv.org/abs/2505.07916
이 논문은 고품질 음성을 생성하는 자동 회귀 트랜스포머 기반의 텍스트 음성 변환(TTS) 모델인 MiniMax-Speech를 소개한다. 핵심 혁신은 참조 오디오의 텍스트 내용 없이도 음색 특징을 추출할 수 있는 학습 가능한 스피커 인코더다. 이를 통해 MiniMax-Speech는 참조 음성과 음색이 일치하는 매우 표현력 풍부한 음성을 제로샷(사전 학습 없이 바로 적용)으로 생성할 수 있으며, 원샷(단 하나의 샘플만으로 학습) 음성 복제 시에도 참조 음성과 매우 높은 유사도를 보인다. 또한, 제안된 Flow-VAE 기술을 통해 합성된 오디오의 전체적인 품질을 향상시켰다. 이 모델은 32개 언어를 지원하며, 다양한 객관적 및 주관적 평가 지표에서 뛰어난 성능을 보여준다. 특히, 객관적인 음성 복제 지표(단어 오류율 및 화자 유사도)에서 최고 수준의 결과를 달성했으며, 공개 TTS Arena 리더보드에서 1위를 차지했다. 스피커 인코더의 강력하고 분리된 표현력 덕분에 기본 모델 수정 없이도 LoRA를 통한 임의의 음성 감정 제어, 텍스트 설명에서 직접 음색 특징을 합성하는 텍스트 음성 변환(T2V), 추가 데이터로 음색 특징을 미세 조정하는 전문가 음성 복제(PVC) 등 다양한 응용이 가능하다.

Step1X-3D: Towards High-Fidelity and Controllable Generation of Textured 3D Assets
https://arxiv.org/abs/2505.07747
생성형 인공지능(AI)은 텍스트, 이미지, 오디오, 비디오 분야에서 크게 발전했지만, 3D 생성은 데이터 부족, 알고리즘의 한계, 생태계 파편화와 같은 근본적인 문제로 인해 상대적으로 발전이 더디다. 이를 해결하기 위해 이 논문은 Step1X-3D라는 개방형 프레임워크를 제시한다. 이 프레임워크는 다음 세 가지를 통해 이러한 문제들을 해결하고자 한다: (1) 5백만 개 이상의 에셋을 처리하여 표준화된 기하학적 및 질감(텍스처) 속성을 가진 2백만 개의 고품질 데이터셋을 만드는 엄격한 데이터 정제 파이프라인; (2) 하이브리드 VAE-DiT(Variational Autoencoder - Diffusion Transformer) 형상 생성기와 확산 기반 텍스처 합성 모듈을 결합한 2단계 3D 네이티브 아키텍처; (3) 모델, 훈련 코드, 적응 모듈의 완전한 오픈 소스 공개다. 형상 생성을 위해 하이브리드 VAE-DiT 구성 요소는 세밀한 부분 보존을 위해 날카로운 가장자리 샘플링과 함께 퍼시버(perceiver) 기반 잠재 공간 인코딩을 사용하여 TSDF(Truncated Signed Distance Function) 표현을 생성한다. 이후 확산 기반 텍스처 합성 모듈은 기하학적 조건화와 잠재 공간 동기화를 통해 여러 시점에서 일관된 텍스처를 보장한다. 벤치마크 결과는 기존 오픈 소스 방법들을 능가하며 독점적인 솔루션들과도 경쟁력 있는 품질을 달성함을 보여준다. 특히 이 프레임워크는 LoRA와 같은 2D 제어 기술을 3D 합성에 직접 적용할 수 있도록 지원하여 2D와 3D 생성 패러다임을 연결하는 독특한 기능을 제공한다. 데이터 품질, 알고리즘의 정확성, 재현성을 동시에 향상시킴으로써 Step1X-3D는 제어 가능한 3D 에셋 생성을 위한 개방형 연구의 새로운 표준을 정립하는 것을 목표로 한다.

4.경량화 모델 연구
Bielik v3 Small: Technical Report
https://arxiv.org/abs/2505.02550
이 논문은 폴란드어 처리에 최적화된, 파라미터 효율성이 높은 생성형 텍스트 모델 시리즈인 Bielik v3 (1.5B 및 4.5B 파라미터)를 소개한다. 이 모델들은 더 작고 잘 최적화된 아키텍처로도 훨씬 적은 계산 자원을 사용하면서 대규모 모델과 유사한 성능을 달성할 수 있음을 보여준다. 주요 혁신 사항은 다음과 같다: 토큰 효율성을 크게 향상시키는 맞춤형 폴란드어 토크나이저(APT4), 다양한 명령어 유형에 걸쳐 학습 균형을 맞추는 가중 명령어 교차 엔트로피 손실, 그리고 훈련 진행 상황에 따라 학습률을 동적으로 조절하는 적응형 학습률이다. 3억 3백만 개의 문서에 걸친 2920억 개의 토큰으로 구성된 세심하게 선별된 말뭉치로 훈련된 이 모델들은 여러 벤치마크에서 뛰어난 성능을 보인다. 45억 파라미터 모델은 2~3배 큰 모델과 경쟁할 만한 결과를 보여주며, 15억 파라미터 모델은 매우 작은 크기에도 불구하고 강력한 성능을 제공한다. 이러한 발전은 상대적으로 적게 연구된 언어에서 파라미터 효율적인 언어 모델링의 새로운 기준을 제시하며, 자원이 제한된 환경에서도 고품질 폴란드어 AI 기술에 더 쉽게 접근할 수 있도록 한다.
[METAX = 김한얼 기자]
[저작권자ⓒ META-X. 무단전재-재배포 금지]