환각, 데이터 불일치 등 근본적 한계를 해결하며 멀티모달 환경으로 확장 가속
Sharing is Caring: Efficient LM Post-Training with Collective RL Experience Sharing
https://arxiv.org/abs/2509.08721
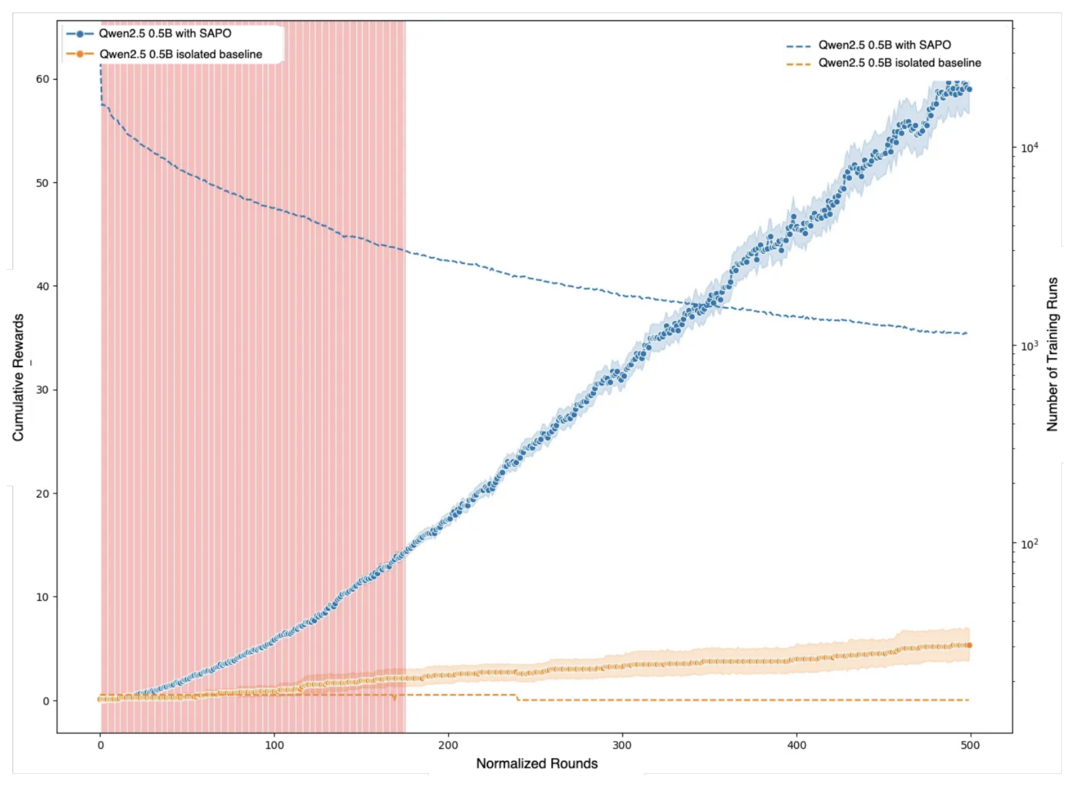
이 논문은 대규모 언어 모델에 강화 학습을 적용하는 과정에서 발생하는 병렬화의 어려움을 해결하는 새로운 접근법을 제시한다. 기존 방식이 대규모 컴퓨팅 자원에 의존하는 것과 달리, 이 논문은 SAPO(Swarm sAmpling Policy Optimization)라는 완전히 분산되고 비동기적인 알고리즘을 제안한다. SAPO는 네트워크의 각 노드가 독립적으로 모델을 운영하며 훈련 경험(롤아웃)을 다른 노드와 공유함으로써, 하드웨어 종류나 지연 시간에 관계없이 유연하게 작동한다. 이러한 경험 공유를 통해 모델은 '아하 모먼트'를 빠르게 확산시키며 학습을 가속화하며, 통제된 실험에서 누적 보상을 최대 94%까지 향상시키는 성과를 보였다.
Why Language Models Hallucinate
https://arxiv.org/abs/2509.04664
이 논문은 대규모 언어 모델이 '환각'을 일으키는 근본적인 이유를 파헤친다. 저자들은 환각이 단순히 모델의 오류가 아니라, 불확실성을 인정하는 대신 그럴듯한 추측을 하는 것을 보상하는 현재의 훈련 및 평가 체계 때문에 발생한다고 주장한다. 모델은 벤치마크에서 높은 점수를 얻기 위해 불확실한 상황에서도 정답처럼 보이는 답변을 생성하도록 학습되며, 이는 본질적으로 이진 분류 오류에 해당한다. 따라서 환각 문제를 해결하기 위해서는 새로운 평가 벤치마크를 추가하기보다, 불확실한 답변에 페널티를 부여하는 기존 평가 방식 자체를 수정해야 한다고 제안한다.

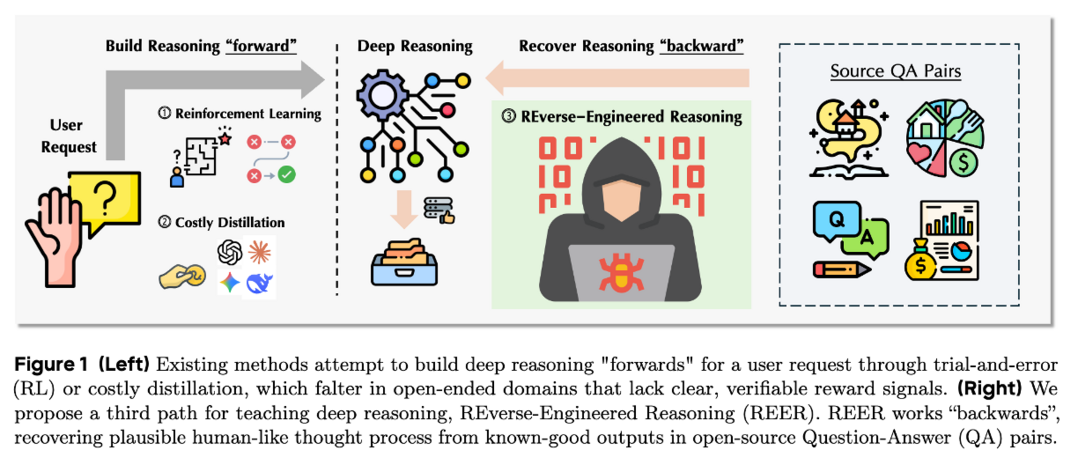
Reverse-Engineered Reasoning for Open-Ended Generation
https://arxiv.org/abs/2509.06160
이 논문은 개방형 창작 작업에서 언어 모델의 추론 능력을 강화하는 REER(REverse-Engineered Reasoning)이라는 새로운 패러다임을 제안한다. 기존의 강화 학습이나 지식 증류 방식이 안고 있는 명확한 보상 신호 부재와 비용 문제를 극복하기 위해, REER은 '역공학' 접근법을 사용한다. 이는 이미 잘 알려진 좋은 결과물로부터 거꾸로 추론 과정을 발견하고 이를 학습 데이터로 활용하는 방식이다. 이러한 접근법을 통해 DeepWriting-20K라는 2만 개의 추론 궤적 데이터셋을 구축했으며, 이 데이터를 학습한 DeepWriter-8B 모델은 GPT-4o나 Claude 3.5와 같은 최첨단 모델과 비견되는 성능을 달성했다.
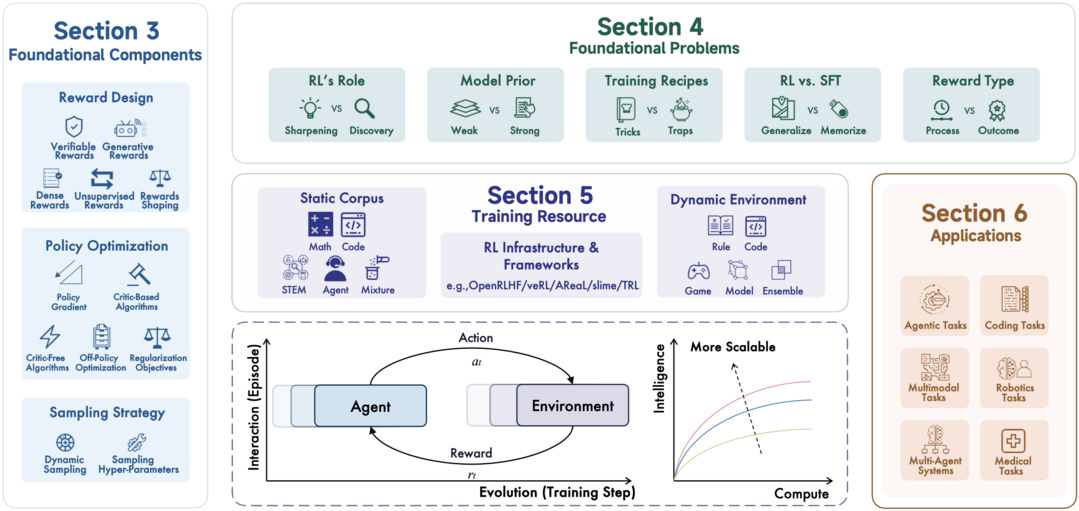
A Survey of Reinforcement Learning for Large Reasoning Models
https://arxiv.org/abs/2509.08827
이 논문은 대규모 추론 모델(LRM)의 발전에 필수적인 강화 학습(RL)의 최신 동향을 총체적으로 조사한다. 수학이나 코딩과 같은 복잡한 논리적 과제에서 RL이 LLM의 능력을 혁신적으로 향상시켰음을 강조하며, LLM을 LRM으로 변화시키는 핵심 방법론으로 RL을 제시한다. 논문은 RL의 기초 구성 요소부터 주요 도전 과제, 훈련 자원, 그리고 실제 응용 사례들을 심도 있게 분석한다. 이 분야의 빠른 발전 속도 속에서, 논문은 향후 연구 방향과 인공 초지능(ASI)으로 나아가기 위한 확장성 문제를 재조명하며 미래를 위한 전략을 탐색한다.
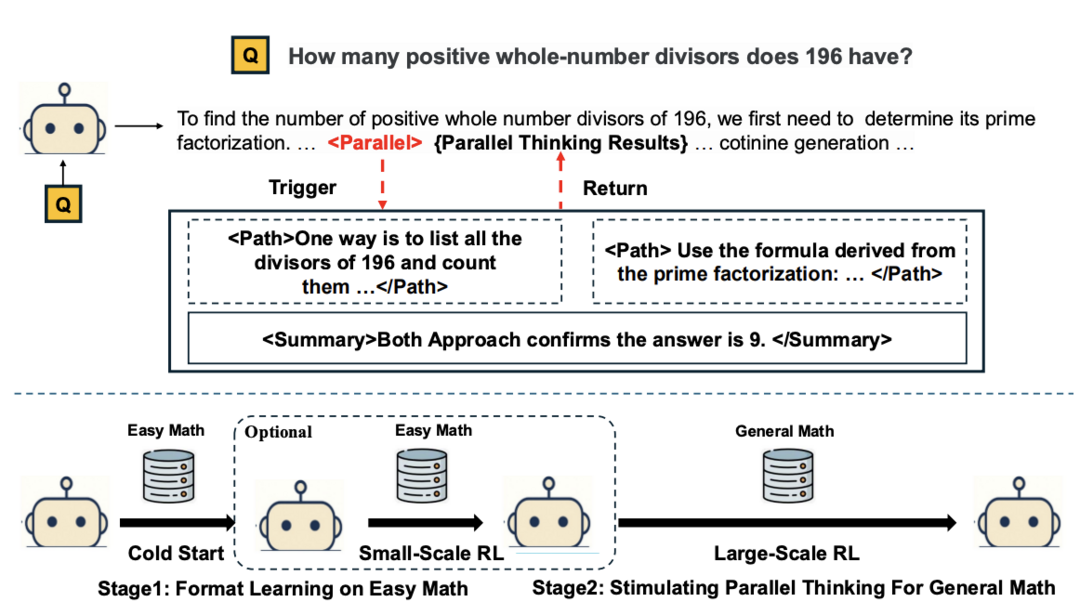
Parallel-R1: Towards Parallel Thinking via Reinforcement Learning
https://arxiv.org/abs/2509.07980
이 논문은 복잡한 추론 문제 해결을 위해 언어 모델에 병렬적 사고 능력을 부여하는 최초의 강화 학습 프레임워크인 Parallel-R1을 소개한다. 기존의 지도 학습 방식이 교사의 답변을 단순히 모방하는 데 그치는 한계를 지적하며, Parallel-R1은 점진적 커리큘럼을 활용해 모델이 여러 추론 경로를 동시에 탐색하도록 훈련한다. 먼저 지도 학습으로 병렬적 사고의 기초를 다진 후, 강화 학습을 통해 어려운 문제에 대한 탐색 및 일반화 능력을 키운다. 이 방식은 순차적 사고 모델 대비 8.4%의 정확도 향상을 가져왔으며, 특히 중간 훈련 단계에서 병렬적 사고를 '탐색 도구'로 활용함으로써 최종 성능을 42.9%까지 끌어올리는 효과를 보였다.
HuMo: Human-Centric Video Generation via Collaborative Multi-Modal Conditioning
https://arxiv.org/abs/2509.08519
이 논문은 텍스트, 이미지, 오디오 등 여러 입력값을 활용해 사람 중심의 비디오를 생성하는 HuMo라는 통합 프레임워크를 제안한다. 기존 방식이 훈련 데이터 부족과 이질적인 모달리티 간의 조율 문제로 어려움을 겪는다는 점에 주목한다. HuMo는 고품질의 다중 모달 데이터셋을 구축하고, 두 단계로 진행되는 훈련 패러다임을 통해 문제를 해결한다. 특히 피사체 보존을 위한 '최소 침습 이미지 주입' 전략과 오디오-비주얼 동기화를 위한 '예측을 통한 집중' 전략을 도입하여 다중 모달 입력 간의 유기적인 조화를 가능하게 한다. 그 결과, HuMo는 기존의 전문화된 모델을 능가하며 다중 모달 조건부 비디오 생성의 새로운 기준을 제시한다.

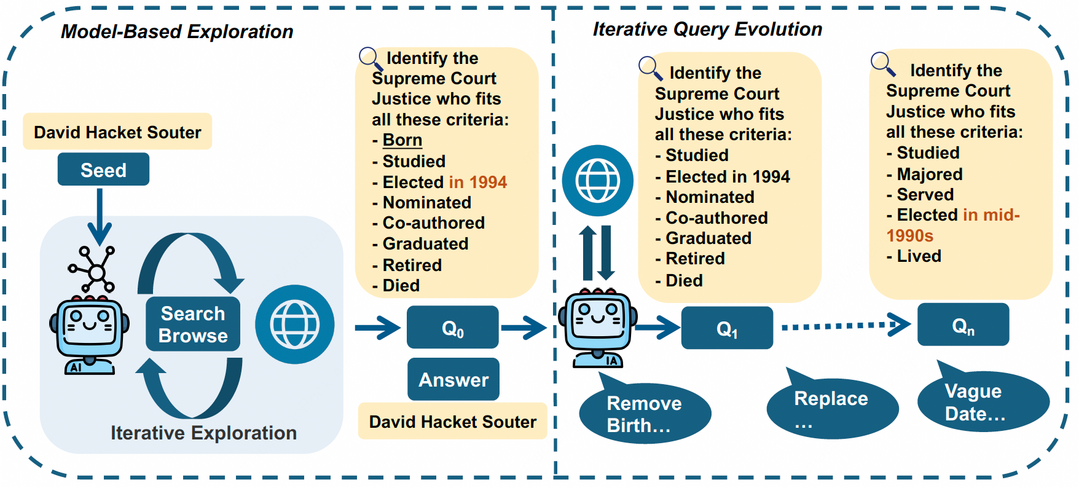
WebExplorer: Explore and Evolve for Training Long-Horizon Web Agents
https://arxiv.org/abs/2509.06501
이 논문은 복잡한 웹 탐색 작업을 수행하는 장기적 웹 에이전트 WebExplorer를 개발한다. 기존의 오픈소스 웹 에이전트들이 도전적인 데이터 부족으로 인해 복잡한 정보 탐색 능력에 한계가 있다는 점을 해결하기 위해, 논문은 새로운 데이터 생성 접근법을 제안한다. WebExplorer는 '모델 기반 탐색'과 '장기-단기 질의 진화' 방식을 통해 다단계 추론과 복잡한 웹 탐색이 필요한 고품질의 쿼리-응답 쌍을 체계적으로 생성한다. 이 데이터로 훈련된 WebExplorer-8B 모델은 128K의 컨텍스트 길이를 지원하며, 동급 모델 중 가장 뛰어난 성능을 보였다. 특히 8B 규모임에도 불구하고 72B 규모 모델을 능가하는 등 높은 효율성과 강력한 성능을 입증했다.
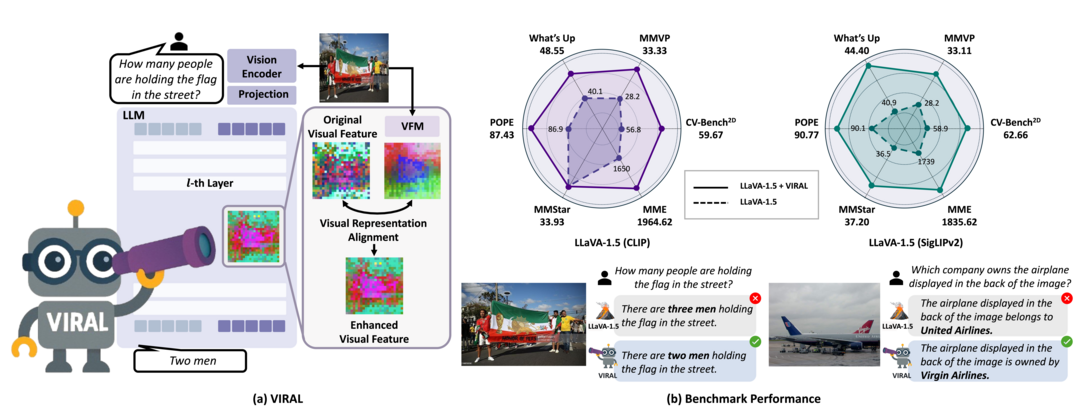
Visual Representation Alignment for Multimodal Large Language Models
https://arxiv.org/abs/2509.07979
이 논문은 멀티모달 대규모 언어 모델(MLLM)이 시각 관련 작업에서 성능이 떨어지는 문제를 해결하기 위해 VIRAL(VIsual Representation ALignment)이라는 간단하지만 효과적인 정규화 전략을 제안한다. 기존의 텍스트 중심 훈련 방식이 미세한 시각적 정보를 무시하게 만드는 경향이 있다는 점에 주목하며, VIRAL은 MLLM의 내부 시각 표현을 사전 훈련된 시각 파운데이션 모델(VFM)의 표현과 일치시키도록 명시적으로 강제한다. 이를 통해 모델은 입력 시각 정보의 중요한 세부 사항을 보존할 뿐만 아니라, VFM의 추가적인 시각 지식까지 보완하게 된다. 결과적으로 VIRAL은 광범위한 멀티모달 벤치마크에서 모든 작업에 걸쳐 일관된 성능 향상을 가져왔다.
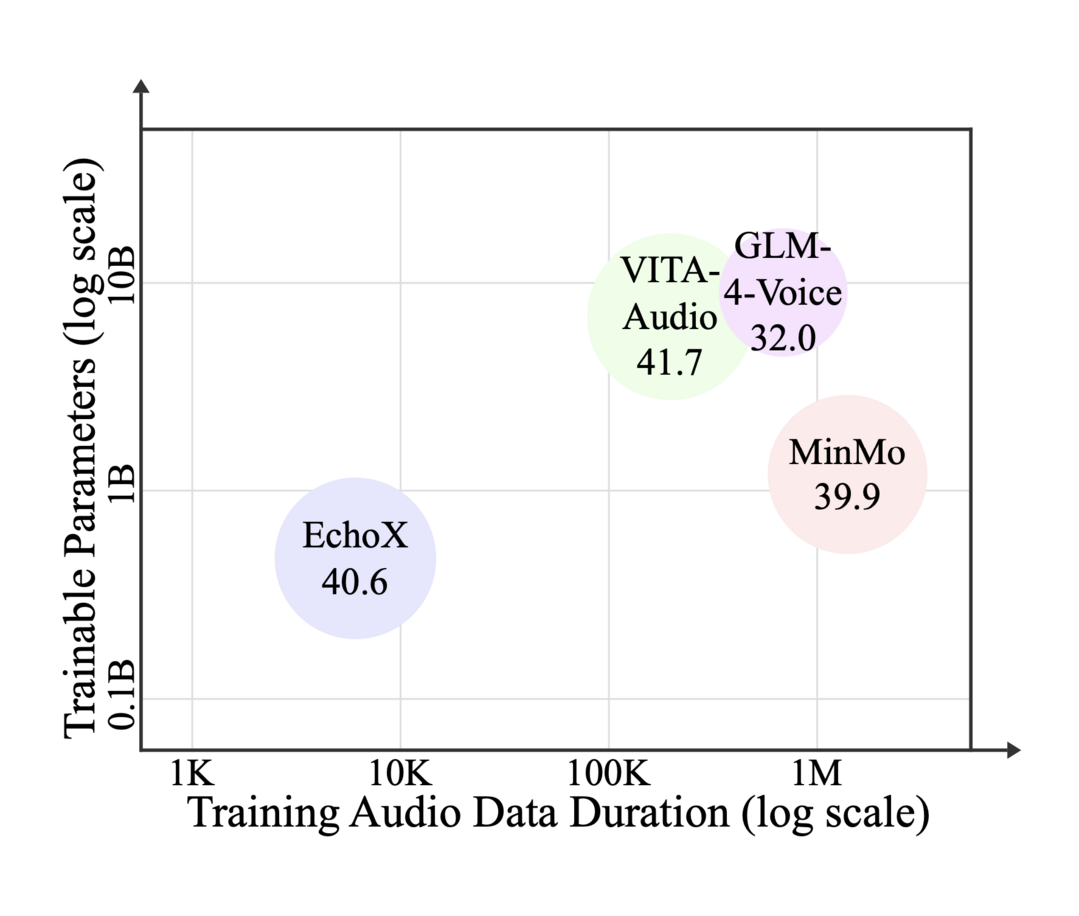
EchoX: Towards Mitigating Acoustic-Semantic Gap via Echo Training for Speech-to-Speech LLMs
https://arxiv.org/abs/2509.09174
이 논문은 음성-대-음성 대규모 언어 모델(SLLM)의 지식 및 추론 능력 저하 문제를 해결하는 EchoX를 제안한다. 기존 SLLM 훈련 패러다임이 음향 정보와 의미론적 정보 사이의 간극을 좁히지 못해 발생하는 한계를 극복하고자 한다. EchoX는 의미론적 표현을 활용하고 음성 훈련 목표를 동적으로 생성함으로써 음향 및 의미론적 학습을 통합하는 독특한 방식을 사용한다. 이 접근법 덕분에 EchoX는 강력한 추론 능력을 유지하는 동시에, 약 6천 시간의 훈련 데이터만으로도 여러 지식 기반 질의응답 벤치마크에서 뛰어난 성능을 달성했다.
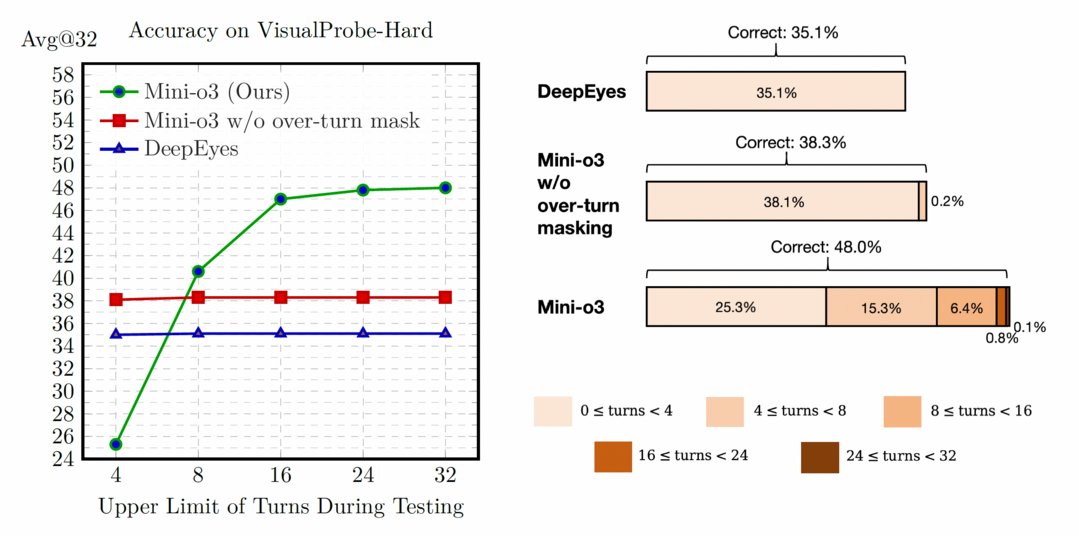
Mini-o3: Scaling Up Reasoning Patterns and Interaction Turns for Visual Search
https://arxiv.org/abs/2509.07969
이 논문은 시각적 탐색 작업에서 모델의 깊은 다단계 추론 능력을 확장하는 Mini-o3 시스템을 소개한다. 기존 오픈소스 방법론이 단조로운 추론 패턴과 제한된 상호작용 횟수로 인해 어려운 문제를 해결하는 데 부적합하다는 점을 지적한다. Mini-o3는 'Visual Probe Dataset'이라는 도전적인 시각 탐색 데이터셋을 구축하고, 다양한 추론 패턴을 담은 궤적을 수집한다. 특히 '오버 턴 마스킹' 전략을 도입하여 최대 상호작용 횟수를 초과하는 응답에 대한 불이익을 없애 훈련 효율성을 높인다. 이 결과, 6회 상호작용으로 훈련된 모델임에도 불구하고 추론 시 수십 단계로 자연스럽게 확장되며, 정확도가 개선되는 것을 보여주었다.
[METAX = 김한얼 기자]
[저작권자ⓒ META-X. 무단전재-재배포 금지]