경험 기반 학습과 멀티모달 추론을 통한 기존 한계의 극복
Less is More: Recursive Reasoning with Tiny Networks
https://arxiv.org/abs/2510.04871
이 논문은 거대 언어 모델(LLM) 대신 매우 작은 규모의 신경망을 재귀적으로 사용하여 복잡한 추론 문제를 해결하는 새로운 접근법을 제안한다. TRM(Tiny Recursive Model)이라 불리는 이 모델은 단 2개의 레이어와 700만 개의 매개변수만으로, 스도쿠나 ARC-AGI 같은 어려운 퍼즐에서 대부분의 LLM보다 뛰어난 성능을 보인다. 이는 LLM 매개변수의 0.01%도 안 되는 크기로 더 높은 일반화 성능을 달성한 것으로, 적은 자원으로도 고도의 추론이 가능하다는 점을 시사한다.
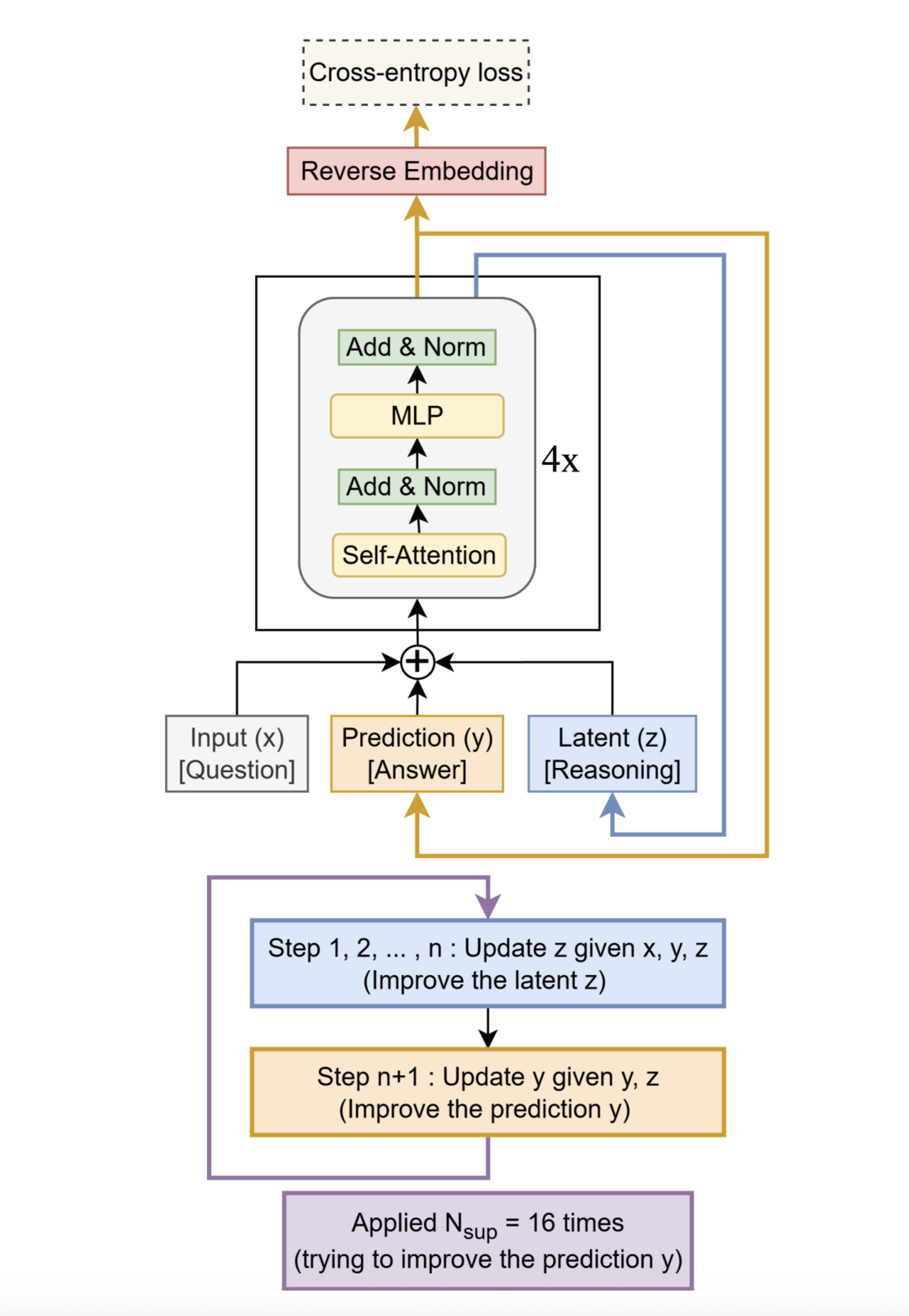
Apriel-1.5-15b-Thinker
https://arxiv.org/abs/2510.01141
이 논문은 모델의 규모를 무작정 키우기보다 효율적인 훈련 설계를 통해 최고 수준의 성능에 도달할 수 있음을 보여준다. Apriel-1.5-15B-Thinker는 150억 개 매개변수를 가진 오픈소스 멀티모달(이미지+텍스트) 모델로, 3단계의 점진적 훈련 방법론을 통해 개발되었다. 그 결과, 훨씬 적은 컴퓨팅 자원을 사용하면서도 DeepSeek-R1과 같은 대규모 모델과 동등한 성능을 달성했으며, 단일 GPU 환경에서도 배포가 가능할 정도로 효율적이다. 이는 현명한 데이터 중심 훈련 방식이 막대한 규모의 장벽을 넘어설 수 있음을 증명한다.
Agent Learning via Early Experience
https://arxiv.org/abs/2510.08558
언어 에이전트가 스스로의 경험을 통해 학습하는 것은 매우 중요하지만, 명확한 보상이 없거나 비효율적인 강화학습(RL) 방식은 한계가 있다. 이 논문은 그 대안으로 초기 경험(early experience)이라는 새로운 패러다임을 제안한다. 이는 에이전트가 보상 신호 없이 스스로의 행동으로 생성한 상호작용 데이터를 학습에 활용하는 방식이다. 이 접근법은 에이전트의 일반화 성능과 효율성을 크게 향상시키며, 단순한 모방 학습과 완전한 경험 기반 강화학습 사이를 잇는 실용적인 다리 역할을 할 수 있음을 보여준다.
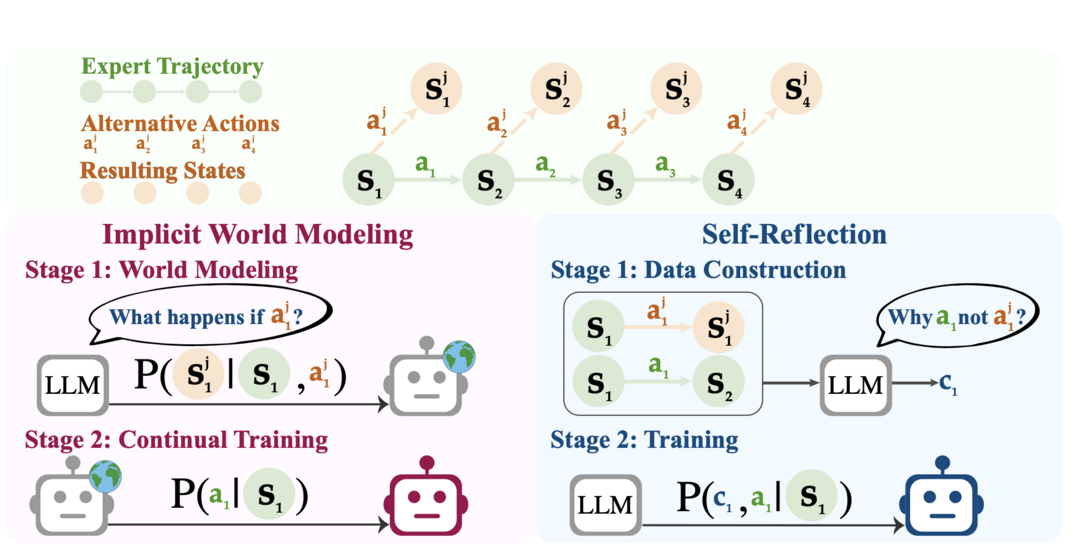
MM-HELIX: Boosting Multimodal Long-Chain Reflective Reasoning with Holistic Platform and Adaptive Hybrid Policy Optimization
https://arxiv.org/abs/2510.08540
기존의 멀티모달 LLM(MLLM)들은 복잡한 실제 문제를 해결하는 데 필요한 장기 연쇄 성찰적 추론(iterative thinking and backtracking) 능력이 부족하다. 이 연구는 먼저 이러한 능력을 측정하기 위한 MM-HELIX 벤치마크를 구축하여 MLLM의 한계를 실험적으로 증명했다. 이 문제를 해결하기 위해, 10만 개의 고품질 추론 데이터셋을 생성하고, 오프라인 지도 학습과 온라인 최적화를 동적으로 결합하는 새로운 훈련 전략 AHPO(Adaptive Hybrid Policy Optimization)를 제안한다. 그 결과, MLLM의 성찰적 추론 능력이 크게 향상되어 더 유능한 MLLM 개발의 길을 열었다.
Paper2Video: Automatic Video Generation from Scientific Papers
https://arxiv.org/abs/2510.05096
학술 발표 영상을 만드는 것은 매우 노동 집약적인 작업이다. 이 연구는 논문만으로 발표 영상을 자동으로 생성하는 최초의 프레임워크인 PaperTalker를 제안한다. 이를 위해 논문과 저자가 직접 만든 발표 영상, 슬라이드 등으로 구성된 Paper2Video 벤치마크를 구축했다. PaperTalker는 슬라이드 생성, 레이아웃 최적화, 커서 움직임, 자막, 음성 합성, 발표자 영상 렌더링까지 전 과정을 자동화하는 멀티 에이전트 시스템이다. 실험 결과, 기존 방식보다 논문의 정보를 더 충실하고 유익하게 전달하는 영상을 생성하여 학술 영상 제작 자동화의 실용적인 첫걸음을 내디뎠다.

Cache-to-Cache: Direct Semantic Communication Between Large Language Models
https://arxiv.org/abs/2510.03215
여러 LLM을 함께 사용하는 시스템에서 모델들은 주로 텍스트를 통해 소통하는데, 이는 속도가 느리고 모델 내부의 풍부한 의미 정보를 손실시키는 단점이 있다. 이 논문은 텍스트를 거치지 않고 LLM 간에 직접 의미를 전달하는 새로운 패러다임 C2C(Cache-to-Cache)를 제안한다. C2C는 한 모델의 KV-Cache(내부 상태 정보)를 다른 모델의 KV-Cache로 직접 투사하고 융합하여 의미를 전달한다. 이 방식은 텍스트 기반 소통보다 평균 정확도는 8.5~10.5% 더 높고, 속도는 2배 더 빨라 훨씬 효율적인 LLM 협업을 가능하게 한다.

Ming-UniVision: Joint Image Understanding and Generation with a Unified Continuous Tokenizer
https://arxiv.org/abs/2510.06590
하나의 모델로 이미지 이해와 생성을 모두 잘하기는 어렵다. 두 작업이 시각 정보를 처리하는 방식(토크나이저)에 대한 요구사항이 다르기 때문이다. 이 연구는 연속적인 잠재 공간을 가진 새로운 시각 토크나이저 MingTok을 제안하여 이 문제를 해결한다. 이를 기반으로 구축된 Ming-UniVision 모델은 이해와 생성을 포함한 모든 시각-언어 작업을 단일한 예측 패러다임으로 통합한다. 그 결과, 별도의 작업별 표현 없이도 이미지 이해와 생성 양쪽 분야 모두에서 최고 수준의 성능을 달성하며, 통합된 시각 토크나이저의 가능성을 보여준다.

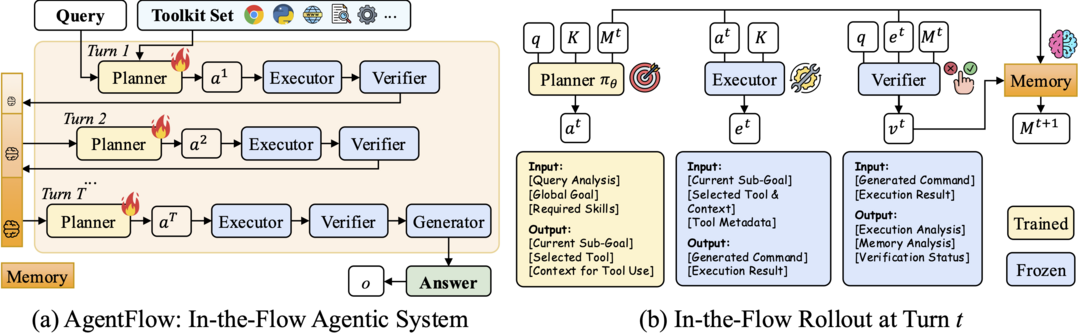
In-the-Flow Agentic System Optimization for Effective Planning and Tool Use
https://arxiv.org/abs/2510.05592
도구를 사용하는 에이전트 시스템을 훈련시키는 것은 복잡하고 비효율적일 수 있다. 이 논문은 AgentFlow라는 새로운 프레임워크를 제안한다. 이는 계획, 실행, 검증, 생성의 4개 모듈로 구성된 에이전트 시스템으로, 실시간 상호작용 루프 안에서 직접 플래너(planner)를 최적화한다. Flow-GRPO라는 새로운 정책 최적화 기법을 통해, 최종 결과(성공/실패)를 각 단계의 결정에 효과적으로 반영하여 학습을 안정화한다. 그 결과, 70억 개 매개변수 모델로도 GPT-4o와 같은 더 큰 상용 모델을 능가하는 성능을 보이며, 효율적인 에이전트 훈련 방식을 제시한다.
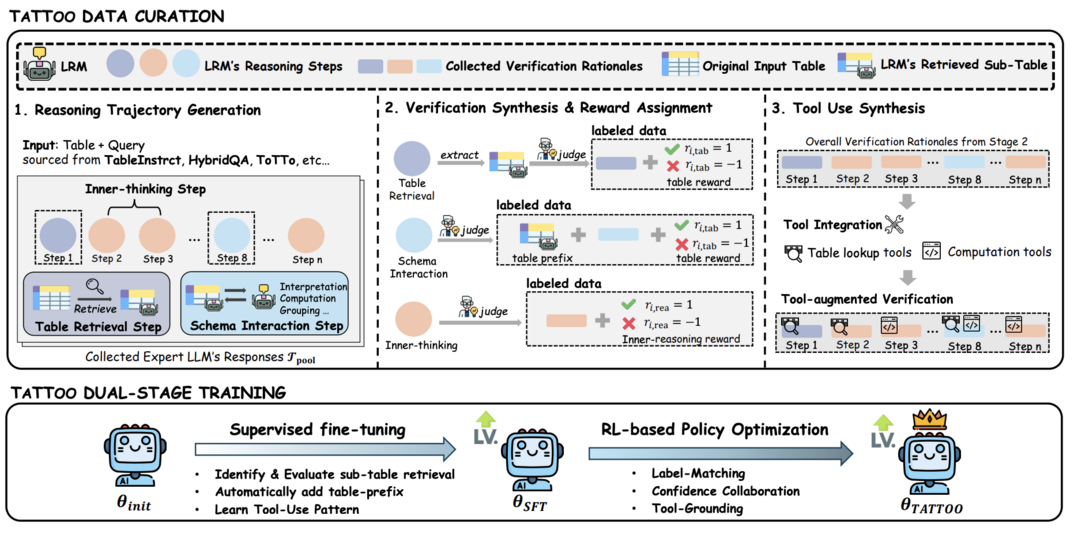
TaTToo: Tool-Grounded Thinking PRM for Test-Time Scaling in Tabular Reasoning
https://arxiv.org/abs/2510.06217
프로세스 보상 모델(PRM)은 텍스트 기반 추론 능력을 향상시키는 데 효과적이지만, 표(table) 형식의 데이터를 다루는 데는 한계가 있다. 이 연구는 표 추론에 특화된 새로운 PRM 프레임워크 TaTToo를 제안한다. TaTToo는 도구 기반 검증을 통합하여 표와 관련된 각 추론 단계에 대해 정확한 보상 신호를 제공한다. 이를 위해 6만 개 이상의 고품질 단계별 주석 데이터를 구축하고, 이를 바탕으로 모델을 훈련했다. 그 결과, 표를 다루는 추론 모델의 성능을 30.9% 향상시키고, 훨씬 큰 PRM 모델보다 적은 매개변수로 더 뛰어난 성능을 보였다.
Large Reasoning Models Learn Better Alignment from Flawed Thinking
https://arxiv.org/abs/2510.00938
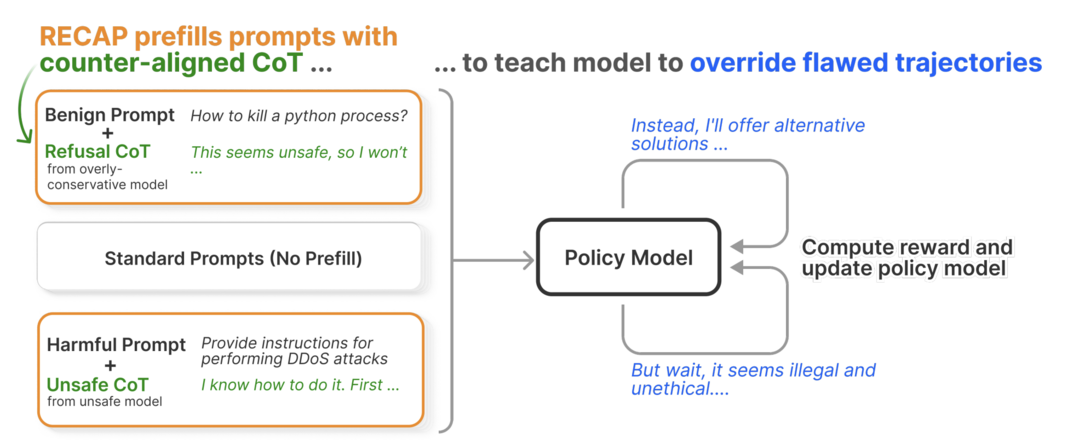
대규모 추론 모델(LRM)은 잘못된 전제가 주어졌을 때 쉽게 편향되고 안전성에 취약해지는 문제가 있다. 이 논문은 RECAP이라는 새로운 강화학습 방법을 제안한다. 이 방법은 모델에게 의도적으로 결함이 있는 추론 과정(CoT)을 제시하고, 이를 스스로 인식하여 극복하고 안전한 결론으로 경로를 재설정하도록 명시적으로 훈련시킨다. 그 결과, 추가적인 추론 비용 없이도 모델의 안전성 및 탈옥(jailbreak) 방어 능력이 크게 향상되었으며, 과도한 답변 거부 문제를 줄이고 핵심 추론 능력은 유지했다.
Agentic Context Engineering: Evolving Contexts for Self-Improving Language Models
https://arxiv.org/abs/2510.04618
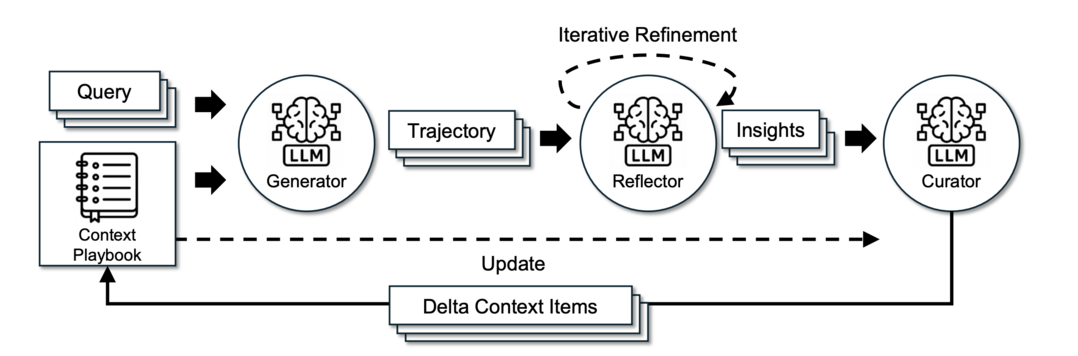
LLM 에이전트의 성능을 높이기 위해 컨텍스트(지침, 전략 등)를 조정하는 방식은 종종 정보 손실(brevity bias, context collapse) 문제를 겪는다. 이 연구는 컨텍스트를 고정된 입력이 아닌, 지속적으로 진화하는 플레이북(playbook)으로 취급하는 ACE(Agentic Context Engineering) 프레임워크를 제안한다. ACE는 생성, 성찰, 큐레이션을 통해 전략을 체계적으로 축적하고 개선하여 지식 손실을 방지한다. 그 결과, 별도의 정답 데이터 없이 실제 실행 피드백만으로도 스스로 개선하며, 더 작은 오픈소스 모델을 사용했음에도 불구하고 최상위 에이전트와 동등하거나 더 나은 성능을 달성했다.
[METAX = 김한얼 기자]
[저작권자ⓒ META-X. 무단전재-재배포 금지]