과학 탐구·로봇 제어 등 특화 도메인을 위한 자율 에이전트 및 멀티모달 기술의 고도화
DataFlow: An LLM-Driven Framework for Unified Data Preparation and Workflow Automation in the Era of Data-Centric AI
https://arxiv.org/abs/2512.16676
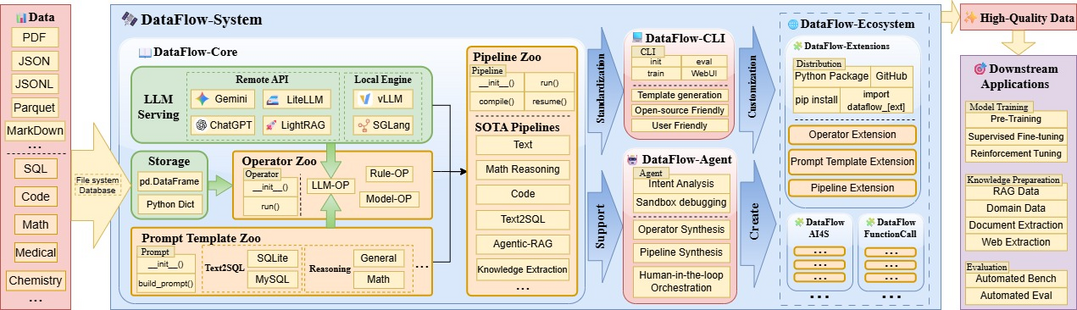
[메타X(MetaX)] 대규모 언어 모델(LLM)을 위한 고품질 데이터 준비의 중요성이 커짐에 따라, 기존의 비체계적인 스크립트 위주 방식을 개선하기 위해 통합적이고 확장 가능한 데이터 준비 프레임워크인 DataFlow를 제안한다. 이 프레임워크는 PyTorch 스타일의 API와 200여 개의 재사용 가능한 연산자를 통해 모듈화된 데이터 변환을 지원하며, 자연어 명세를 실행 가능한 파이프라인으로 자동 변환하는 DataFlow-Agent를 도입하여 사용성을 극대화했다. 텍스트, 수학, 코드 등 다양한 도메인에서 검증한 결과, DataFlow는 텍스트-SQL 변환 정확도와 코드 벤치마크 등에서 기존의 합성 데이터나 인간 구축 데이터셋보다 우수한 성능을 입증하며 신뢰할 수 있는 데이터 중심 AI 개발의 기반을 마련했다.
Probing Scientific General Intelligence of LLMs with Scientist-Aligned Workflows
https://arxiv.org/abs/2512.16969
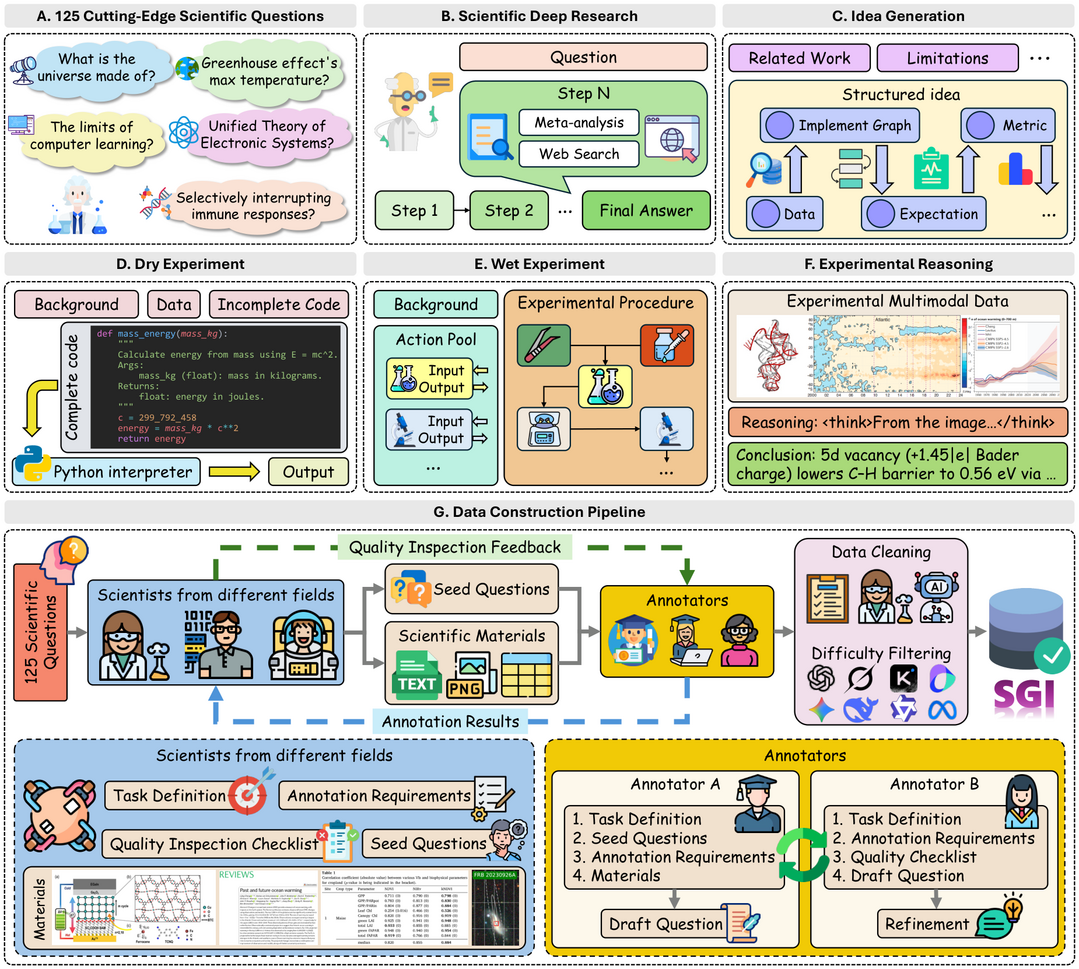
과학적 일반 지능(SGI)의 개념을 실용적 탐구 모델(PIM)에 기반하여 정립하고, 이를 심층 연구, 아이디어 생성, 실험 설계 및 추론 등 4가지 작업으로 구체화한 SGI-Bench를 통해 최신 LLM의 과학적 능력을 체계적으로 평가했다. 1,000개 이상의 전문가 큐레이팅 샘플을 바탕으로 평가한 결과, LLM은 심층 연구의 정확도나 아이디어의 실현 가능성, 실험 결과 예측 등에서 여전히 한계를 보였으며, 이를 보완하기 위해 추론 시 검색 증강 기반의 보상을 최적화하는 테스트 타임 강화 학습(TTRL)을 제안하여 가설의 참신성을 높이는 방법을 제시했다.
SemanticGen: Video Generation in Semantic Space
https://arxiv.org/abs/2512.20619
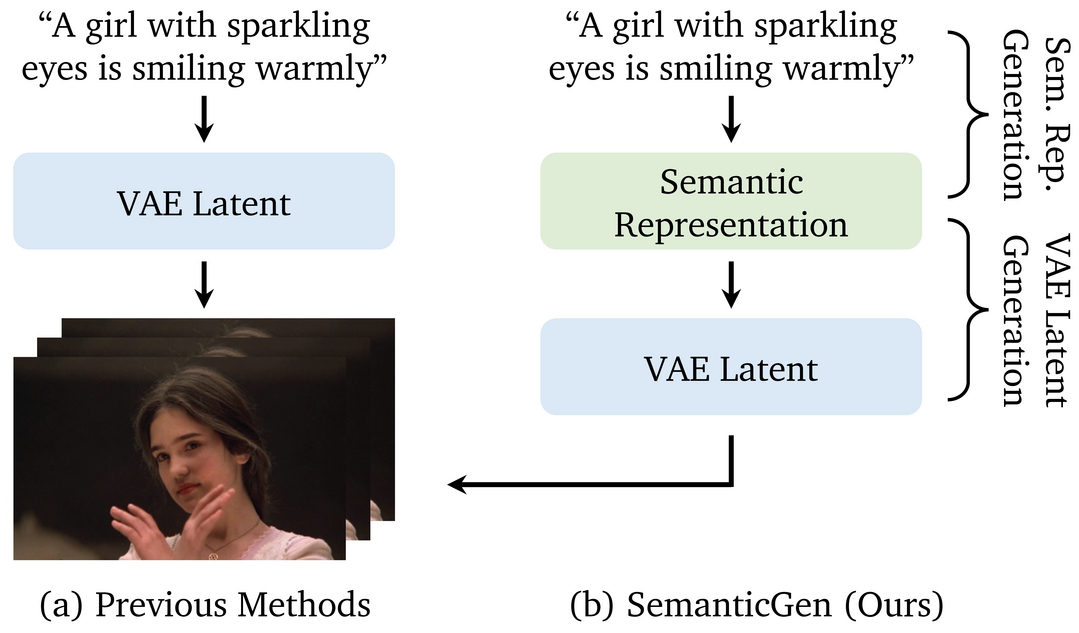
기존 비디오 생성 모델이 VAE 잠재 공간에서 픽셀로 매핑하는 방식의 느린 수렴 속도와 높은 비용 문제를 해결하기 위해, 의미적 공간(Semantic Space)에서 비디오를 생성하는 새로운 접근법인 SemanticGen을 제안한다. 이 모델은 비디오의 전반적인 레이아웃을 정의하는 압축된 의미적 특징을 먼저 생성한 후, 이를 바탕으로 세부적인 VAE 잠재 변수를 생성하는 2단계 확산 과정을 통해 작동한다. 실험 결과, SemanticGen은 기존 방식보다 빠른 수렴 속도를 보이며 긴 비디오 생성에서도 효율적일 뿐만 아니라, 최신 모델들을 능가하는 고품질의 비디오를 생성할 수 있음을 입증했다.
Step-DeepResearch Technical Report
https://arxiv.org/abs/2512.20491
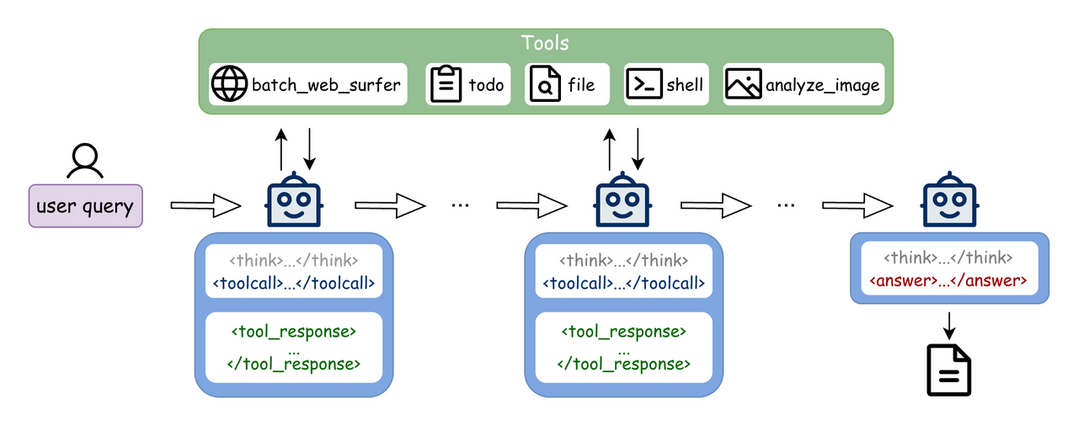
자율 에이전트로의 전환 흐름에 맞춰, 개방형 연구 수행에 필요한 의도 인식, 장기적 의사결정, 교차 검증 능력을 갖춘 비용 효율적인 엔드투엔드 에이전트인 Step-DeepResearch를 소개한다. 기획 및 보고서 작성 능력을 강화하기 위해 원자적 능력 기반의 데이터 합성 전략과 단계별 학습 경로(중간 학습, SFT, RL)를 적용하고 체크리스트 스타일의 평가자를 도입하여 견고성을 높였다. 중국 도메인 평가를 위해 구축한 ADR-Bench와 Scale AI 루브릭 평가에서, 32B 규모의 이 모델은 동급 모델을 능가하고 OpenAI나 Gemini의 최신 모델과 대등한 성능을 보이며 중간 규모 모델로도 전문가 수준의 연구 역량을 달성할 수 있음을 증명했다.
PhysBrain: Human Egocentric Data as a Bridge from Vision Language Models to Physical Intelligence
https://arxiv.org/abs/2512.16793
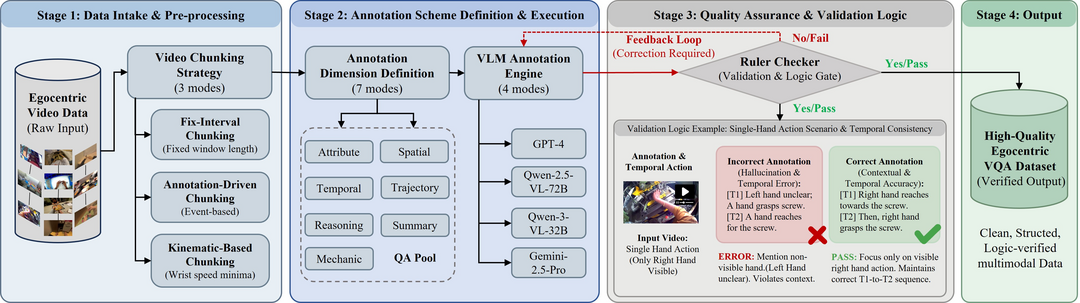
3인칭 데이터 위주로 학습된 기존 시각-언어 모델(VLM)이 휴머노이드 로봇의 1인칭 시점과 불일치하는 문제를 해결하기 위해, 대규모 인간 1인칭 비디오를 구조화된 로봇 학습 데이터로 변환하는 파이프라인과 이를 통해 구축한 E2E-3M 데이터셋을 제안한다. 이 데이터셋으로 학습된 PhysBrain 모델은 1인칭 시점의 상호작용과 인과관계 이해 능력이 대폭 향상되었으며, 특히 로봇 제어 시뮬레이션인 SimplerEnv에서 53.9%의 성공률을 기록하여 인간의 1인칭 데이터가 로봇의 물리적 지능으로 효과적으로 전이될 수 있음을 입증했다.
Robust-R1: Degradation-Aware Reasoning for Robust Visual Understanding
https://arxiv.org/abs/2512.17532
실세계의 시각적 품질 저하 환경에서 멀티모달 대규모 언어 모델(MLLM)의 성능이 급격히 떨어지는 문제를 해결하기 위해, 구조화된 추론 체인을 통해 시각적 열화를 명시적으로 모델링하는 Robust-R1 프레임워크를 제안한다. 이 방법은 열화 인식 추론을 위한 지도 미세 조정, 파라미터 인식을 위한 보상 기반 정렬, 열화 강도에 따른 동적 추론 깊이 조절을 통합하였으며, 11,000건의 전문 데이터셋을 구축하여 학습에 활용했다. 평가 결과, Robust-R1은 R-Bench 등 다양한 벤치마크에서 기존 모델들을 능가하는 견고성을 보였으며, 복합적이고 적대적인 열화 상황에서도 우수한 시각적 이해 능력을 유지했다.
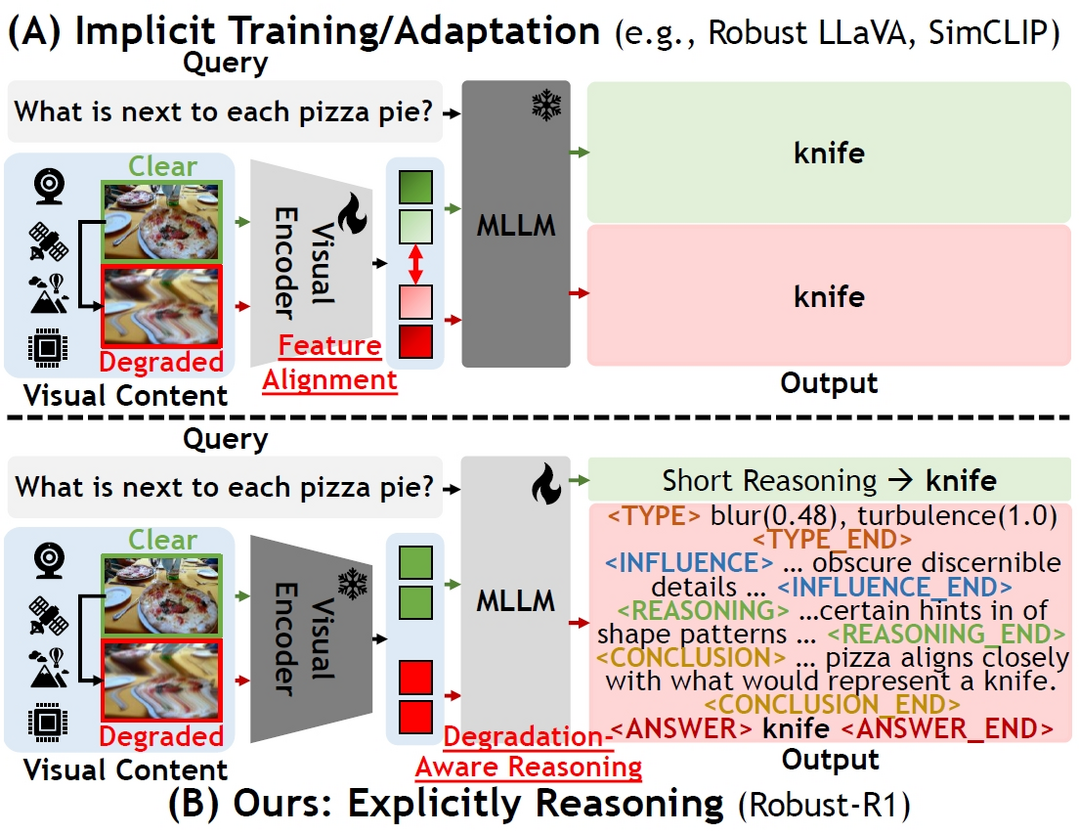
TurboDiffusion: Accelerating Video Diffusion Models by 100-200 Times
https://arxiv.org/abs/2512.16093
비디오 생성 품질을 유지하면서도 엔드투엔드 확산 생성 속도를 100~200배 가속화할 수 있는 프레임워크인 TurboDiffusion을 소개한다. 이 기술은 낮은 비트의 SageAttention과 학습 가능한 희소 선형 어텐션(SLA)을 활용한 연산 가속, rCM 기반의 스텝 증류, 그리고 모델 파라미터와 활성화를 8비트로 양자화하는 기법 등을 결합하여 최적화했다. Wan2.1 모델들에 적용한 실험 결과, 단일 RTX 5090 GPU에서도 비디오 품질 저하 없이 획기적인 속도 향상을 달성했음을 확인했다.
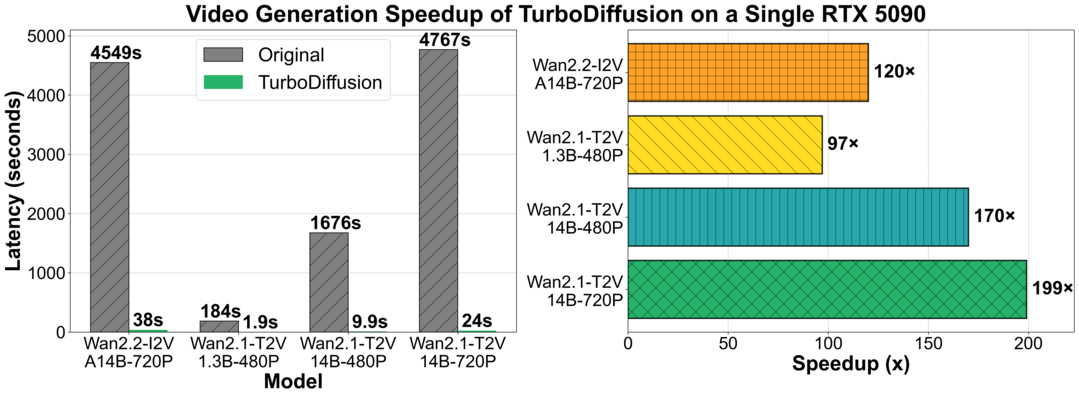
The Prism Hypothesis: Harmonizing Semantic and Pixel Representations via Unified Autoencoding
https://arxiv.org/abs/2512.19693
의미적 인코더는 주로 추상적인 저주파 성분을, 픽셀 인코더는 세밀한 고주파 정보를 포착한다는 스펙트럼 특성을 분석하여, 각 모달리티가 공유된 특징 스펙트럼의 투영이라는 '프리즘 가설'을 제안한다. 이러한 통찰을 바탕으로 의미적 구조와 픽셀 세부 정보를 주파수 대역 변조기를 통해 조화롭게 통합하는 Unified Autoencoding(UAE) 모델을 개발했다. ImageNet과 MS-COCO 벤치마크 실험을 통해, UAE는 단일 잠재 공간 내에서 의미적 추상화와 픽셀 수준의 충실도를 효과적으로 결합하여 최첨단 성능을 달성함을 입증했다.
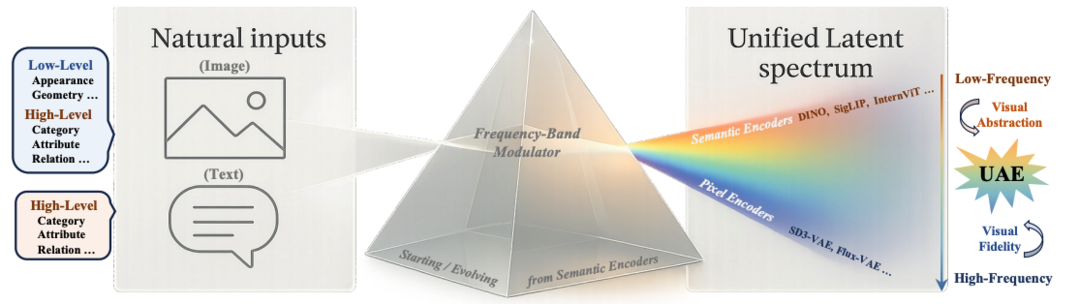
Bottom-up Policy Optimization: Your Language Model Policy Secretly Contains Internal Policies
https://arxiv.org/abs/2512.19673
대규모 언어 모델(LLM)을 단일 정책으로 보는 기존 강화 학습의 한계를 넘어, 모델 내부의 각 레이어와 모듈이 고유한 정책을 가진다는 관점에서 내부 메커니즘을 분석하고 이를 최적화하는 BuPO(Bottom-up Policy Optimization) 기법을 제안한다. 분석 결과 하위 레이어는 탐색을 위해 높은 엔트로피를 유지하고 상위 레이어는 정제를 위해 수렴하는 경향을 발견했으며, 이를 바탕으로 초기 학습 단계에서 하위 레이어의 정책을 직접 최적화하도록 설계했다. 복잡한 추론 벤치마크 실험에서 BuPO는 기초적인 추론 능력을 재구성하고 기존 방법보다 우수한 성능을 발휘함을 확인했다.
When Reasoning Meets Its Laws
https://arxiv.org/abs/2512.17901
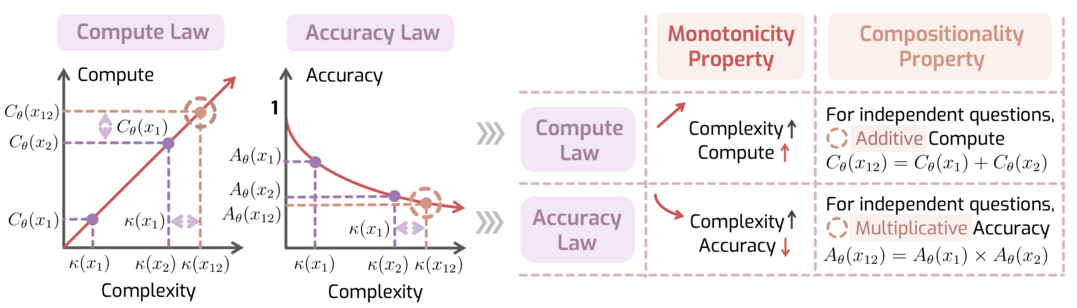
대규모 추론 모델(LRM)의 추론 패턴을 이론적으로 정립하기 위해, 질문의 복잡도에 따라 연산량이 선형적으로 증가해야 한다는 '연산 법칙'과 이에 따른 정확도 법칙을 포함하는 추론의 법칙(LoRe) 프레임워크를 제안한다. 모델들이 이러한 법칙의 단조성과 구성성을 얼마나 따르는지 측정하기 위해 LoRe-Bench를 개발하여 평가한 결과, 대부분의 모델이 구성성 측면에서 부족함을 발견했다. 이에 대응하여 연산 법칙의 구성성을 강화하는 미세 조정 방법을 적용함으로써, 다양한 벤치마크에서 추론 성능을 일관되게 향상시키고 법칙 준수와 성능 간의 시너지 효과를 입증했다.
[METAX = 김한얼 기자]
[저작권자ⓒ META-X. 무단전재-재배포 금지]