2024년 W35에 주목할만한 인공지능(AI) 분야의 논문들을 소개합니다.
SAD, Inheritune, Transformer to Mamba는 모델 효율성을 향상시켰고, TSDE는 시계열 데이터 학습을, Neural Assets는 3D 객체 제어를, T3M은 음성-텍스트 기반 모션 생성을 개선했습니다. 언어 모델 연구는 지식 저장 용량과 새로운 학습 방법을 탐구했으며, Multilingual Arbitrage와 MTMamba++는 다국어 및 다중 작업 처리를 발전시켰습니다. LLM 스케줄링은 서비스 최적화에 기여했고, TAG는 AI와 데이터베이스 융합 가능성을 보여주었습니다.
Autonomous Driving with Spiking Neural Networks
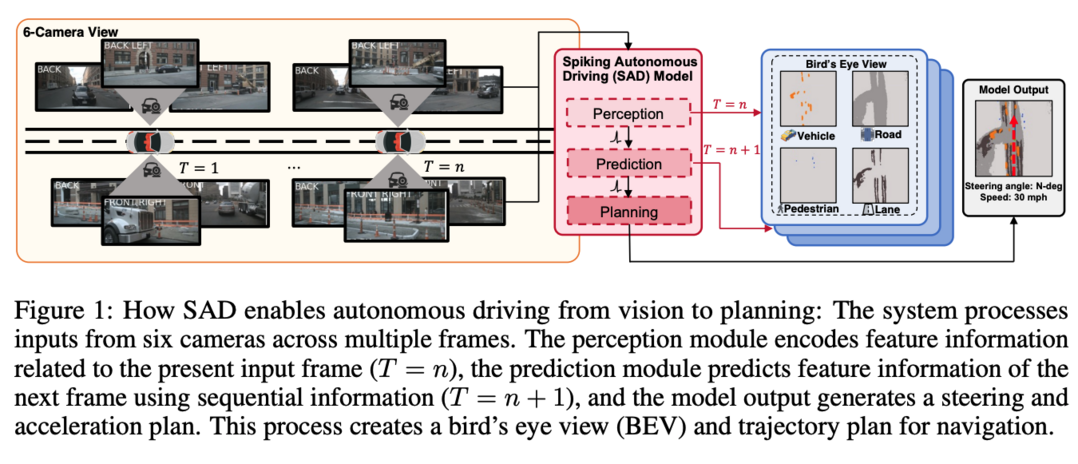
자율주행 시스템은 에너지 효율이 매우 중요한데, 이 논문에서는 Spiking Neural Network (SNN) 기반의 자율주행 시스템 SAD를 제안합니다. SNN은 이벤트 기반 연산을 통해 에너지 효율을 높인 신경망 모델입니다. SAD는 perception, prediction, planning 세 가지 모듈로 구성되어 다중 카메라 입력을 처리하고, 미래 상황을 예측하며, 안전한 주행 경로를 생성합니다. nuScenes 데이터셋을 이용한 실험에서 SAD는 기존 SNN보다 우수한 성능을 보이며 에너지 효율적인 자율주행 기술 가능성을 보여줍니다.
Pre-training Small Base LMs with Fewer Tokens
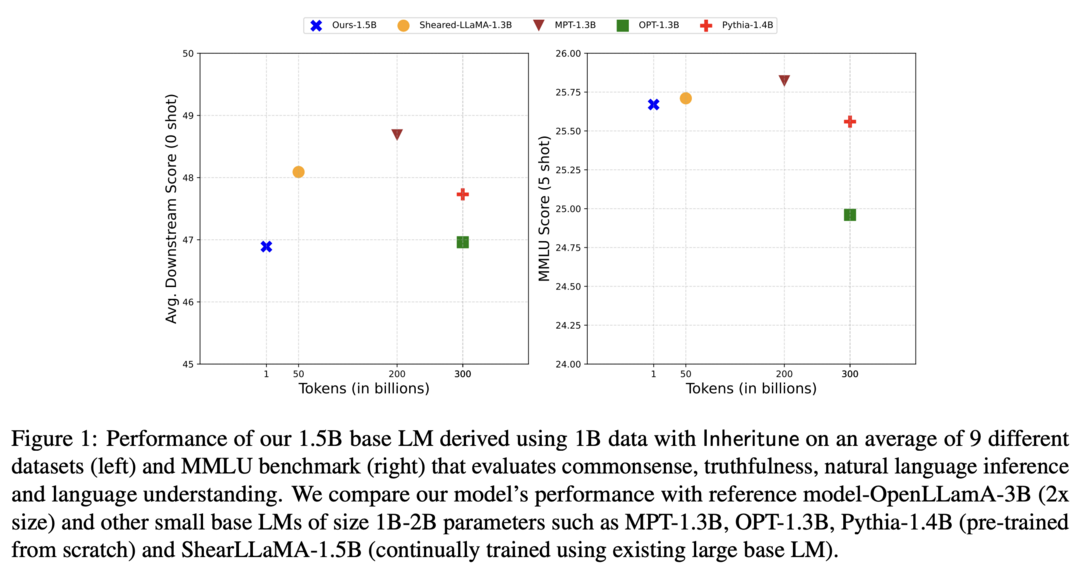
대규모 언어 모델(Large Language Model, LM)을 처음부터 학습시키는 것은 많은 시간과 자원을 필요로 합니다. 이 논문에서는 적은 양의 데이터와 계산 자원으로 효율적으로 작은 LM을 학습시키는 Inheritune 기법을 제안합니다. Inheritune은 큰 LM의 일부 레이어를 물려받아 작은 LM의 초기 가중치로 사용하고, 작은 데이터셋으로 추가 학습을 진행합니다. 실험 결과, Inheritune으로 학습된 작은 LM은 적은 데이터와 학습 시간으로도 기존 방법들과 비슷하거나 더 나은 성능을 달성했습니다. GPT2-medium과 GPT2-large 모델의 일부 레이어를 활용하여 작은 LM을 학습시켰고, OpenWebText 데이터셋으로 동일한 학습 시간 동안 학습했을 때, 큰 모델과 비슷한 검증 손실을 달성했습니다. 다양한 실험을 통해 Inheritune 기법의 효율성을 입증했습니다.
Self-Supervised Learning of Time Series Representation via Diffusion Process and Imputation-Interpolation-Forecasting Mask
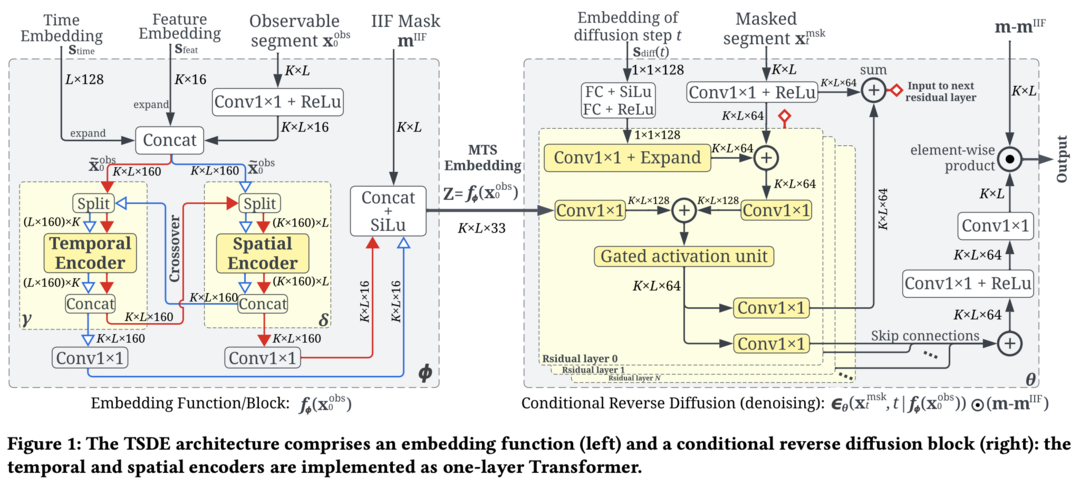
시계열 데이터의 유용한 표현을 학습하는 것은 다양한 예측 및 분석 작업에 중요합니다. 이 논문에서는 Diffusion Process 기반의 새로운 자기 지도 학습(Self-Supervised Learning, SSL) 방법인 TSDE(Time Series Diffusion Embedding)를 제안합니다. TSDE는 시계열 데이터를 관측된 부분과 마스킹된 부분으로 나누고, 마스킹된 부분을 예측하도록 학습합니다. 특히, Imputation-Interpolation-Forecasting (IIF) 마스크를 사용하여 다양한 시계열 예측 작업에 효과적으로 활용될 수 있는 표현을 학습합니다. 실험 결과, TSDE는 기존 방법들보다 시계열 데이터의 다양한 작업에서 우수한 성능을 보여줍니다.
Neural Assets: 3D-Aware Multi-Object Scene Synthesis with Image Diffusion Models

이미지 생성 모델에서 여러 객체의 3D 포즈를 제어하는 것은 어려운 문제입니다. 이 논문에서는 이미지에서 객체의 시각적 표현을 추출하여 3D 포즈 정보와 결합한 Neural Assets 개념을 제안합니다. Neural Assets를 이용하면 기존 텍스트 기반 이미지 생성 모델에서 텍스트 대신 객체의 3D 위치 및 포즈를 제어하여 원하는 장면을 생성할 수 있습니다. Neural Assets는 다양한 장면에서 객체를 생성하고 조작하는 데 사용될 수 있으며, 실제 비디오 데이터셋에서도 효과적으로 작동합니다.
T3M: Text Guided 3D Human Motion Synthesis from Speech

음성 기반 3D 모션 합성은 가상현실, 게임, 영화 제작 등 다양한 분야에서 활용될 수 있습니다. 기존 방법들은 음성 정보만을 사용하여 모션을 생성했기 때문에 정확도와 유연성이 떨어졌습니다. 이 논문에서는 텍스트 정보를 추가적으로 활용하여 더욱 정확하고 다양한 3D 모션을 생성하는 T3M이라는 새로운 방법을 제안합니다. T3M은 텍스트 입력을 통해 모션 생성을 정밀하게 제어할 수 있어 사용자 맞춤 설정 및 다양성을 향상시킵니다.
Physics of Language Models: Part 3.3, Knowledge Capacity Scaling Laws
언어 모델의 크기와 성능 사이의 관계를 나타내는 Scaling Laws 연구는 활발하게 진행되고 있습니다. 이 논문에서는 언어 모델이 저장할 수 있는 지식의 양을 비트 단위로 측정하여 모델의 크기 변화에 따른 지식 저장 용량 변화를 분석합니다. 연구 결과, 언어 모델은 파라미터 당 2비트의 지식을 저장할 수 있으며, 70억 개의 파라미터를 가진 모델은 영어 위키백과와 여러 교과서를 합친 것보다 많은 양의 지식을 저장할 수 있다는 것을 밝혀냈습니다. 특히 이 논문에서는 언어 모델의 지식 저장 용량에 영향을 미치는 다양한 요인들을 분석합니다. 학습 시간, 모델 아키텍처, 양자화, sparsity 제약 조건, 데이터의 signal-to-noise ratio 등 다양한 요인들이 모델의 지식 저장 용량에 미치는 영향을 실험적으로 보여줍니다. 특히, Rotary Embedding을 사용하는 GPT-2 아키텍처가 짧은 학습 시간 동안 LLaMA/Mistral 아키텍처보다 더 많은 지식을 저장할 수 있다는 것을 발견했습니다.
Generative Verifiers: Reward Modeling as Next-Token Prediction
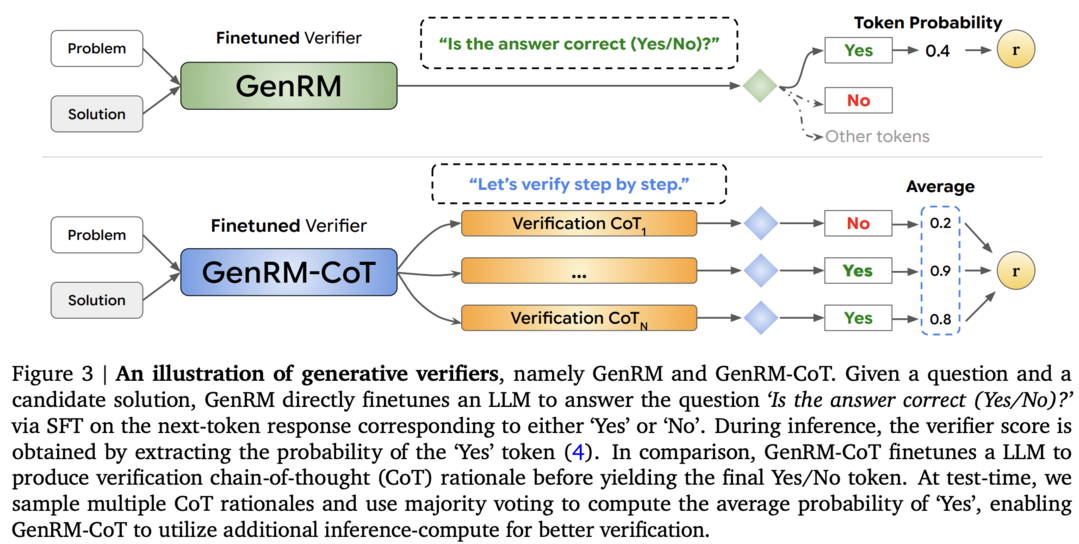
대규모 언어 모델(LLM)의 추론 성능을 향상시키기 위해 보상 모델(Reward Model)이 자주 사용됩니다. 이 논문에서는 LLM 기반 보상 모델을 학습하는 새로운 방법인 Generative Verifiers (GenRM)을 제안합니다. GenRM은 기존의 분류 기반 학습 방식 대신, LLM의 텍스트 생성 능력을 활용하여 다음 토큰 예측을 통해 보상 모델을 학습합니다. 실험 결과, GenRM은 기존 방법들보다 알고리즘 및 수학 문제 풀이에서 더 나은 성능을 보여주었으며, 데이터 세트 크기, 모델 용량 및 추론 시간 계산에 따라 효과적으로 확장될 수 있음을 보여주었습니다.
Multilingual Arbitrage: Optimizing Data Pools to Accelerate Multilingual Progress
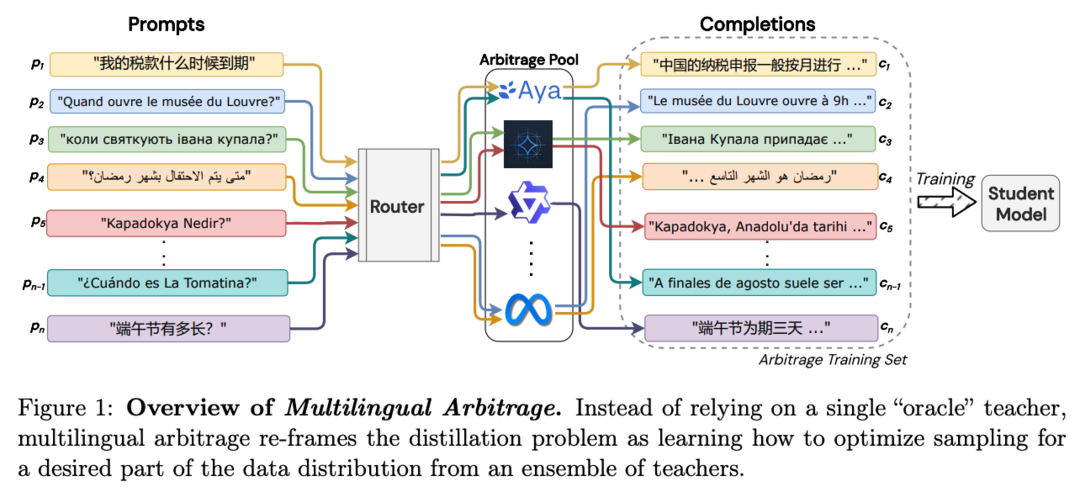
합성 데이터는 최근 인공지능 발전에 중요한 역할을 하고 있습니다. 그러나 단일 모델에 의존하는 기존 방법들은 모델 편향 및 성능 저하 문제를 야기할 수 있습니다. 특히 다국어 환경에서는 모든 언어에서 뛰어난 성능을 보이는 단일 모델을 찾기 어렵습니다. 이 논문에서는 여러 모델의 장점을 활용하여 다국어 성능을 향상시키는 Multilingual Arbitrage 기법을 제안합니다. 다양한 언어에 특화된 여러 모델을 활용하여 데이터 샘플을 전략적으로 라우팅함으로써 단일 모델을 사용하는 것보다 최대 56.5% 높은 성능 향상을 달성했습니다. 특히, 자원이 부족한 언어에서 더 큰 성능 향상을 보였습니다.
Text2SQL is Not Enough: Unifying AI and Databases with TAG
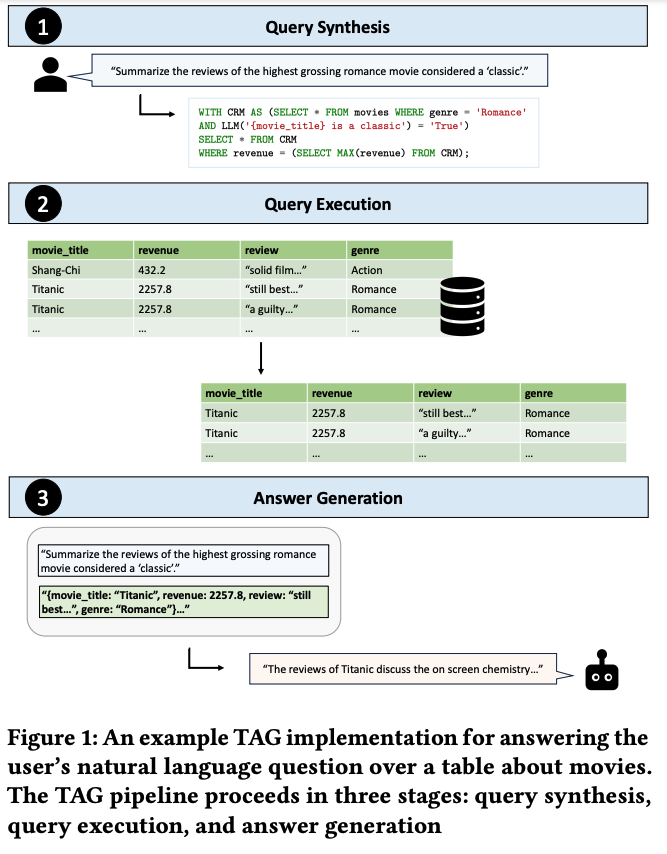
데이터베이스 질의를 위한 인공지능 시스템은 자연어 처리와 데이터베이스 기술의 결합으로 큰 가치를 창출할 수 있습니다. 그러나 기존 방법들은 자연어 질의를 관계형 대수로 변환하는 데 집중하여 실제 사용자의 요구를 충족시키지 못하는 경우가 많습니다. 이 논문에서는 자연어 질의를 처리하기 위한 새롭고 포괄적인 패러다임인 Table-Augmented Generation (TAG)을 제안합니다. TAG는 언어 모델과 데이터베이스 간의 다양한 상호 작용을 모델링하여 기존 방법들보다 폭넓은 질의를 처리할 수 있도록 합니다.
The Mamba in the Llama: Distilling and Accelerating Hybrid Models
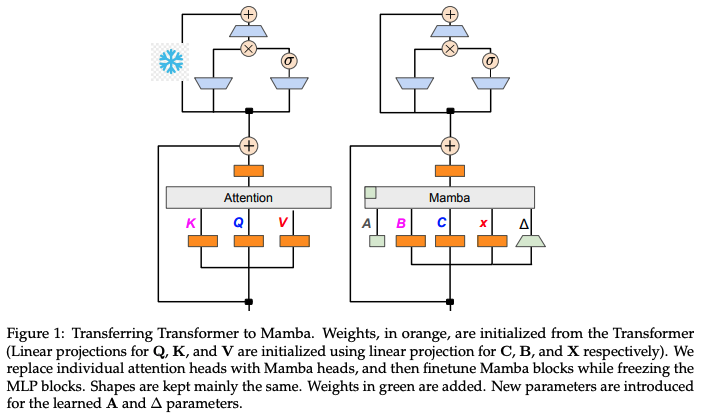
Mamba와 같은 선형 RNN 아키텍처는 언어 모델링에서 Transformer 모델과 경쟁할 수 있는 성능을 보이면서도 효율적인 배포 특성을 가지고 있습니다. 이 논문에서는 사전 학습된 Transformer 모델을 선형 RNN으로 변환하여 배포하는 방법을 제안합니다. Transformer 모델의 어텐션 레이어에서 선형 투영 가중치를 재사용하여 Mamba 모델로 지식을 전이하는 방법을 통해, 기존 Transformer 모델의 성능을 유지하면서도 더 빠른 추론 속도를 달성했습니다.
Efficient LLM Scheduling by Learning to Rank

대규모 언어 모델(LLM) 추론에서 출력 길이를 예측하는 것은 어렵기 때문에 대부분의 LLM 서빙 시스템은 단순한 선입선출(FCFS) 스케줄링 전략을 사용합니다. 이는 Head-Of-Line(HOL) blocking 현상을 야기하여 처리량과 서비스 품질을 저하시키는 문제점이 있습니다. 이 논문에서는 각 요청의 정확한 생성 길이를 예측하는 대신, 여러 요청의 출력 길이 순위를 예측하는 Learning to Rank 기반 스케줄러를 제안합니다. 이를 통해 최단 작업 우선(SJF) 스케줄링에 가까운 효율적인 스케줄링이 가능해져 챗봇 서빙의 지연 시간을 줄이고 합성 데이터 생성의 처리량을 향상시키는 등 다양한 LLM 응용 프로그램에서 성능을 크게 향상시켰습니다.
MTMamba++: Enhancing Multi-Task Dense Scene Understanding via Mamba-Based Decoders
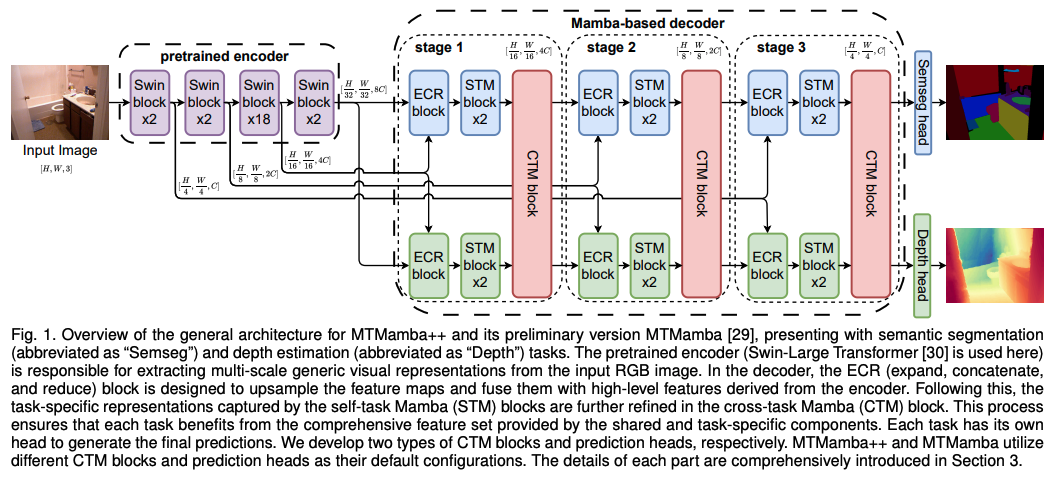
다중 작업 밀집 장면 이해는 여러 밀집 예측 작업을 위해 하나의 모델을 학습하는 것으로, 다양한 응용 분야에서 활용됩니다. 이 논문에서는 Mamba 기반 디코더를 사용하여 장거리 의존성을 효과적으로 모델링하고 작업 간 상호 작용을 강화하는 새로운 아키텍처인 MTMamba++를 제안합니다. MTMamba++는 self-task Mamba (STM) 블록과 cross-task Mamba (CTM) 블록으로 구성되어, STM은 상태 공간 모델을 활용하여 장거리 의존성을 처리하고 CTM은 작업 간 정보 교환을 용이하게 하여 성능을 향상시킵니다.
[저작권자ⓒ META-X. 무단전재-재배포 금지]