[메타X(MetaX)] 2025년 10월, 위키미디어 재단은 흥미롭지만 불편한 보고서를 공개했다. 올해 5월 이후, 전 세계 위키백과의 인간 방문자 트래픽이 전년 대비 약 8% 감소했다는 것이다.
이는 단순한 이용률 하락이 아니라, AI와 소셜미디어가 인터넷의 정보 소비 방식을 근본적으로 바꿔놓고 있음을 보여주는 신호다.
지금, 사람들은 더 이상 ‘위키백과를 검색하지 않는다’. 대신 AI가 위키백과를 읽고, 요약된 답변만 사용자에게 전달한다.
“트래픽 급감, 그러나 봇은 폭증”
위키미디어 재단은 2025년 봄, 브라질을 중심으로 비정상적인 트래픽 급증 현상을 포착했다. 처음에는 이용자 증가로 보였지만, 알고 보니 대부분은 AI 크롤러와 데이터 수집용 봇(bot)이었다.
AI 기업들이 위키백과의 방대한 텍스트를 언어모델(LLM) 훈련 데이터로 활용하기 위해 자동화된 수집기를 가동하면서, ‘봇 트래픽’이 사람을 압도하는 현상이 발생한 것이다.
위키미디어의 봇 탐지 로직이 업데이트되자, ‘인간 방문’으로 분류되던 상당량의 접속이 실제로는 AI 봇의 접근으로 재분류되었다. 그 결과, 인간 이용자 페이지뷰는 2024년 대비 약 8% 감소로 나타났다.
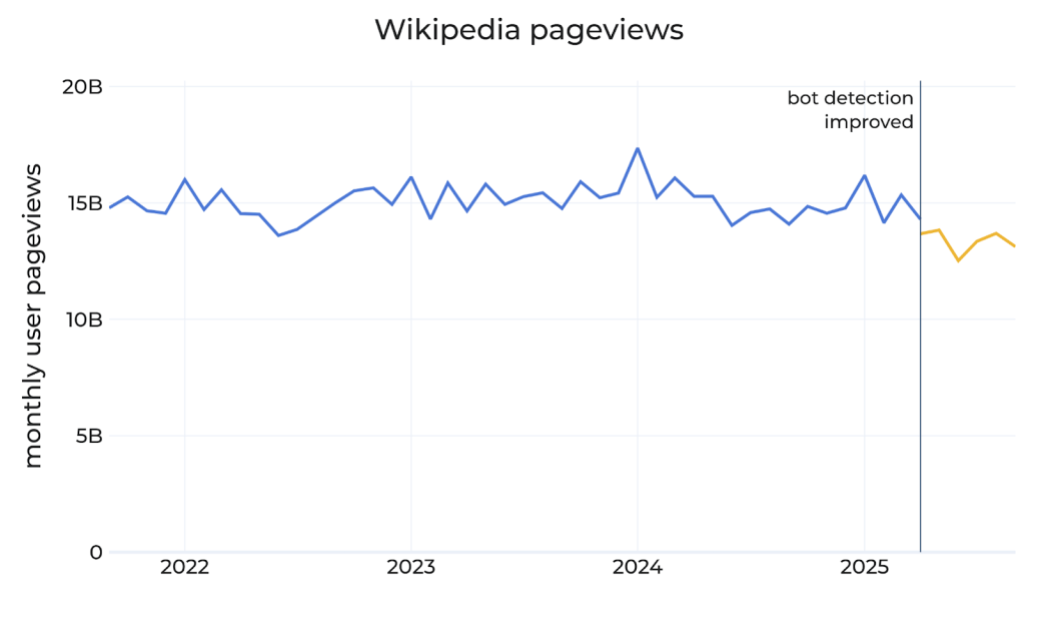
이 수치는 단순히 ‘트래픽이 줄었다’는 의미가 아니다. AI가 사람 대신 읽고, 사람은 AI가 가공한 요약만 소비하는, ‘지식 유통의 단절’이 시작된 것을 보여준다.
AI는 위키백과를 먹고 자란다
AI의 급성장은 위키백과 없이는 불가능했다. ChatGPT, Gemini, Claude, Perplexity, Copilot 등 주요 생성형 AI는 모두 위키백과 데이터를 핵심 학습 코퍼스로 사용한다.
위키백과는 인류가 집단적으로 축적한 가장 방대한 구조화 텍스트 데이터이며, 검증성·중립성·표준 문법을 갖춘 거의 유일한 오픈 데이터 세트다. 문제는, 이 데이터가 AI 기업의 수익 모델에 흡수되면서 “정보의 원천은 공개되어 있지만, 유통은 폐쇄된 구조”가 된다는 점이다.
즉, 위키백과는 AI의 뇌 속에 흡수되어 있지만, AI는 그 원천으로의 ‘링크’를 사용자에게 돌려주지 않는다.
‘공공재의 무임승차’ 현상
위키백과는 기부와 자원봉사자들의 편집으로 유지되는 디지털 공공재다. 하지만 지금, AI 기업들은 그 공공재를 무료로 학습하며 수십억 달러의 상업적 수익을 창출한다.
이 현상은 경제학적으로 공공재의 무임승차(free riding)에 해당한다. AI는 위키백과를 “보이지 않는 공공 인프라”처럼 사용하지만, 그 대가로 위키백과의 지속 가능성은 위협받는다. 재단은 이에 대응하기 위해 ‘Wikimedia Enterprise 프로젝트’를 통해 AI 기업들에게 공정한 라이선스와 재기여 의무를 부과하는 ‘책임 있는 데이터 접근 정책’을 추진 중이다.
“사람이 읽지 않으면, 지식은 멈춘다”
위키백과의 본질은 단순한 정보 저장소가 아니다. 그것은 사람이 쓰고, 검증하고, 수정하며 성장시키는 살아있는 지식 생태계다.
그런데 지금, 이용자들은 검색결과에서 AI가 만든 요약만 읽고 더 이상 “원문을 클릭”하지 않는다.
이는 단순한 방문자 감소가 아니라, 편집자·기여자 감소 → 검증 약화 → 지식 품질 하락으로 이어지는 악순환의 시작이다.
AI는 여전히 위키백과를 학습하지만, 사람이 읽고 수정하지 않는다면 그 데이터는 시간이 멈춘 과거의 지식이 된다. AI가 ‘모르는 것을 알려주지 못하는 이유’는, 결국 인간의 업데이트가 멈췄기 때문이다.
“AI는 출처를 돌려주고 있는가”
AI의 답변은 대부분 위키백과를 기반으로 하지만, 대부분의 플랫폼은 출처 표기를 생략한다. 검색엔진의 ‘요약 답변(Snippet)’이나 AI 챗봇의 응답에는 “이 내용은 위키백과에서 인용됨”이라는 문구가 거의 없다. 위키미디어 재단은 이 문제를 “정보 생태계의 불공정성”으로 규정한다.
AI가 위키백과 데이터를 활용하려면 출처를 명시하고, 다시 원문으로 연결(link-back)할 의무가 있다는 것이다. 재단은 현재 AI 기업들과 협력해 “AI 학습용 데이터 재사용 가이드라인”을 마련 중이며, 이것이 향후 AI 투명성의 핵심 기준이 될 전망이다.
AI 시대의 ‘트래픽 위기’는 보편적이다
AI로 인한 트래픽 감소는 위키백과만의 문제가 아니다. 뉴욕타임스, 로이터, 가디언 등 주요 언론사들도 “AI가 우리의 기사를 요약해 독자가 사라졌다”며 오픈AI·구글을 상대로 집단 소송을 제기했다.
AI가 콘텐츠를 ‘읽고’ 요약을 ‘생산’함으로써 원천 사이트의 존재 이유가 희미해지는 구조적 위기가 발생한 것이다. 결국, “누가 정보를 만들고, 누가 그 대가를 받는가”라는 디지털 저작권의 근본 문제가 다시 부상하고 있다.
‘위키백과 세대’를 다시 만드는 실험
위키미디어 재단은 단순히 위기를 방어하는 것이 아니라 새로운 독자층을 만들어가기 위한 실험에 착수했다.
- Future Audiences 프로젝트: 유튜브, 틱톡, 로블록스 등에서 위키백과 콘텐츠를 영상·게임·챗봇으로 재구성.
- 모바일 편집 UX 개선: 스마트폰에서도 간편하게 문서 수정 가능.
- Reader Growth 팀 신설: AI 세대가 ‘검색 대신 참여’로 전환할 수 있도록 새로운 독서·편집 경험을 디자인.
이러한 시도는 “위키백과를 다시 인간 중심으로 돌려놓는” 가장 근본적인 전략이다.
‘AI가 읽고 인간이 사라지는’ 시대를 막기 위해
AI와 SNS 시대의 정보 소비는 편리하지만,그 편리함이 지식의 원천을 약화시키는 역설을 낳고 있다.
사람이 클릭하지 않는 순간, 공동의 지식은 사라지고, AI는 더 이상 ‘학습할 새로운 것’을 찾지 못한다.
위키백과의 위기는 곧 인간이 참여하지 않는 인터넷의 위기다. 지금 필요한 것은 더 많은 알고리즘이 아니라, 더 많은 ‘사람의 방문’과 ‘사람의 편집’이다.
AI가 정보를 빠르게 전달하는 시대일수록, 우리는 더 자주 물어야 한다.
“내가 지금 읽는 이 문장은, 정말 사람이 쓴 걸까?”
[저작권자ⓒ META-X. 무단전재-재배포 금지]