2024년 W36에 발표된 주목할만한 인공지능(AI) 분야의 논문들을 소개합니다.
TL;DR
자연어 처리 분야에서는 SciLitLLM이 과학 문헌 이해를 위한 특화된 LLM을, Mini-Omni가 실시간 음성 상호작용이 가능한 오디오 기반 대화 모델을, OLMoE가 개방형 Mixture-of-Experts 언어 모델을 제시했습니다. LongRecipe는 LLM의 장문 컨텍스트 일반화를 위한 효율적인 훈련 전략을 제안했으며, LongCite는 장문 컨텍스트 QA에서 세밀한 인용 생성 능력을 개선했습니다.
컴퓨터 비전 분야에서는 VisionTS가 이미지 모델을 활용한 혁신적인 시계열 예측 접근법을, Loopy는 오디오 기반 인물 아바타 생성을 위한 새로운 방법을, Guide-and-Rescale은 실제 이미지 편집을 위한 효과적인 접근법을 소개했습니다.
멀티모달 모델링 분야에서는 LongLLaVA가 1000개 이미지를 효율적으로 처리할 수 있는 멀티모달 LLM을 개발했고, Kvasir-VQA는 GI 트랙트 진단을 위한 텍스트-이미지 쌍 데이터셋을 제공했습니다.
AI 시스템 해석 분야에서는 LLM의 attention head에 대한 포괄적인 survey가 진행되었으며, 보안 분야에서는 FuzzCoder가 LLM을 활용한 새로운 fuzzing 접근법을 제시했습니다.
SciLitLLM: How to Adapt LLMs for Scientific Literature Understanding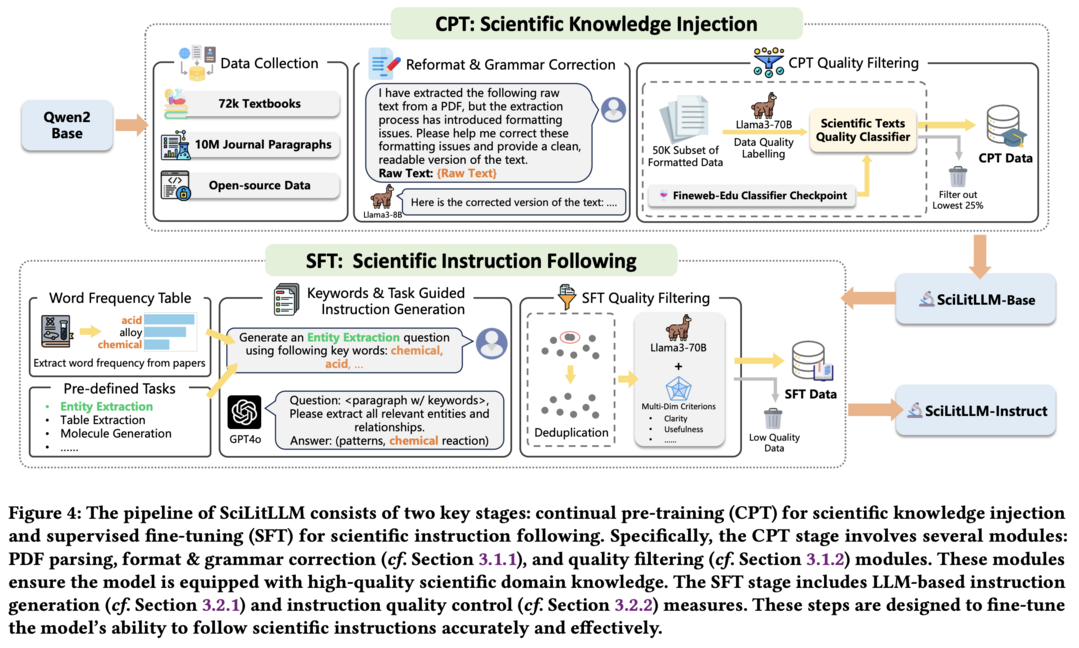 이 논문은 과학 문헌 이해를 위해 특화된 Large Language Model(LLM) 개발 방법을 제안합니다. 연구진은 연속적 사전 훈련(CPT)과 지도 학습 미세 조정(SFT)을 통합한 하이브리드 전략을 통해 과학적 도메인 지식을 주입하고 도메인 특화 태스크에 대한 지시 따르기 능력을 향상시켰습니다. 고품질 CPT 코퍼스 구축과 다양한 SFT 지시문 생성이라는 두 가지 주요 과제를 해결하기 위해 PDF 텍스트 추출, 파싱 오류 수정, 품질 필터링, 합성 지시문 생성 등의 세심한 파이프라인을 구축했습니다. 그 결과 SciLitLLM은 과학 문헌 이해 벤치마크에서 유망한 성능 향상을 보여주었습니다.
이 논문은 과학 문헌 이해를 위해 특화된 Large Language Model(LLM) 개발 방법을 제안합니다. 연구진은 연속적 사전 훈련(CPT)과 지도 학습 미세 조정(SFT)을 통합한 하이브리드 전략을 통해 과학적 도메인 지식을 주입하고 도메인 특화 태스크에 대한 지시 따르기 능력을 향상시켰습니다. 고품질 CPT 코퍼스 구축과 다양한 SFT 지시문 생성이라는 두 가지 주요 과제를 해결하기 위해 PDF 텍스트 추출, 파싱 오류 수정, 품질 필터링, 합성 지시문 생성 등의 세심한 파이프라인을 구축했습니다. 그 결과 SciLitLLM은 과학 문헌 이해 벤치마크에서 유망한 성능 향상을 보여주었습니다.
Mini-Omni: Language Models Can Hear, Talk While Thinking in Streaming
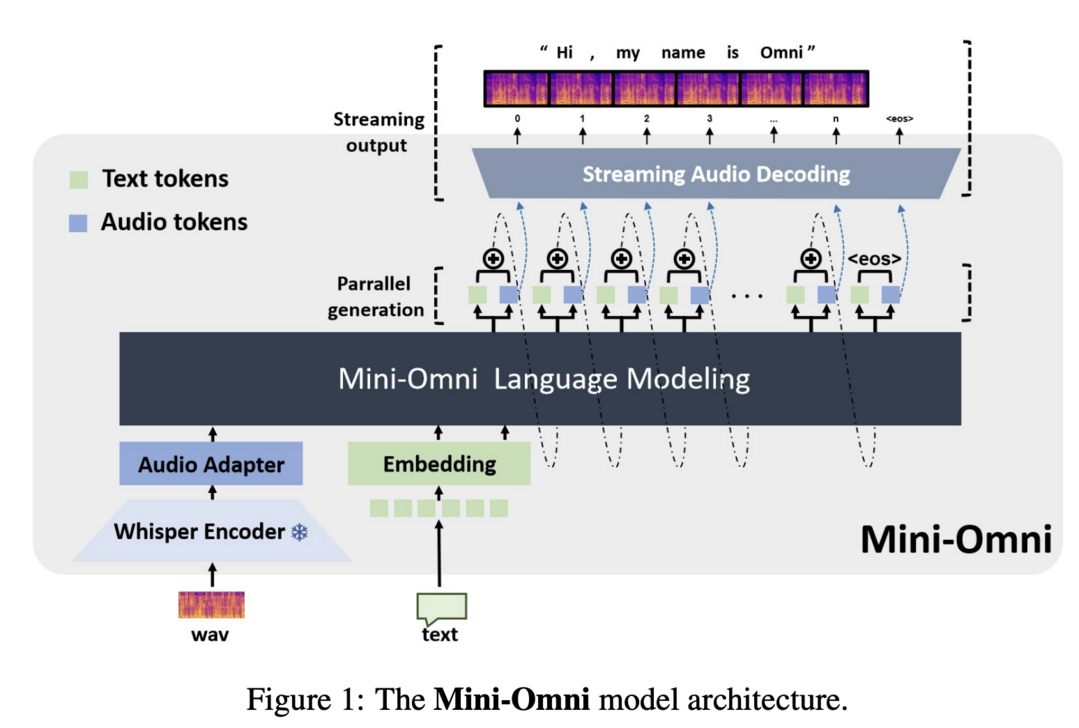
이 연구는 실시간 음성 상호작용이 가능한 오디오 기반 엔드투엔드 대화 모델인 Mini-Omni를 소개합니다. 연구진은 텍스트 지시 음성 생성 방법과 추론 시 병렬 배치 전략을 제안하여 실시간 성능을 향상시켰습니다. 이 방법은 원래 모델의 언어 능력을 최소한의 성능 저하로 유지하면서 실시간 상호작용 능력을 부여합니다. 또한 음성 출력에 최적화된 모델 미세 조정을 위해 VoiceAssistant-400K 데이터셋을 소개했습니다. Mini-Omni는 실시간 음성 상호작용을 위한 최초의 완전 엔드투엔드 오픈소스 모델로, 향후 연구에 큰 잠재력을 제공합니다.
VisionTS: Visual Masked Autoencoders Are Free-Lunch Zero-Shot Time Series Forecasters
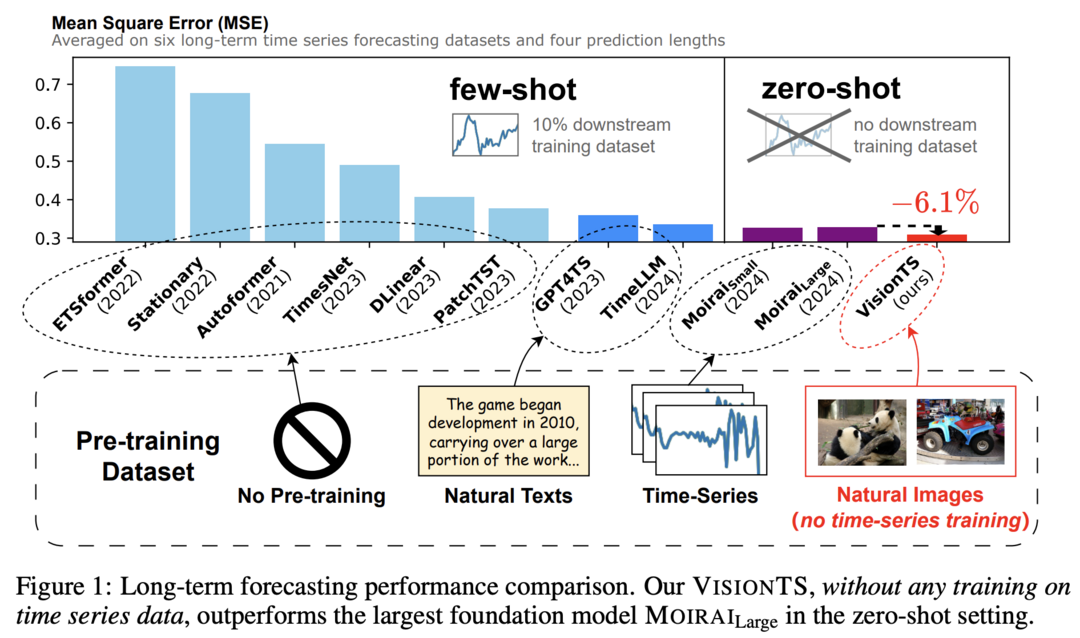
이 논문은 시계열 예측(TSF)을 위한 새로운 접근 방식을 제안합니다. 연구진은 자연 이미지의 풍부하고 고품질 데이터를 활용하여 TSF 기반 모델을 구축하는 방법을 탐구했습니다. TSF 태스크를 이미지 재구성 태스크로 재구성하고, ImageNet 데이터셋에서 사전 훈련된 visual masked autoencoder(MAE)로 처리했습니다. 놀랍게도 시계열 도메인에서의 추가 적응 없이도, 제안된 VisionTS는 기존 TSF 기반 모델들보다 우수한 제로샷 예측 성능을 달성했습니다. 이 발견은 컴퓨터 비전과 TSF 간의 향후 교차 도메인 연구 가능성을 시사합니다.
Kvasir-VQA: A Text-Image Pair GI Tract Dataset
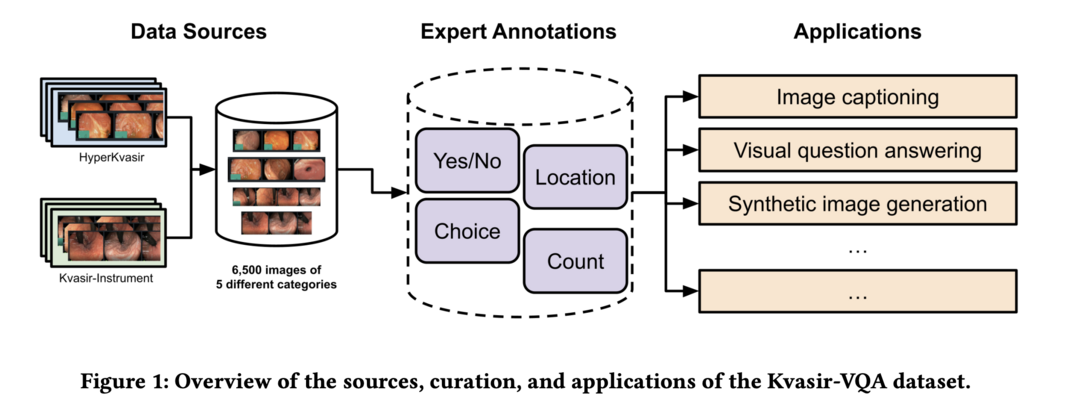
이 논문은 HyperKvasir와 Kvasir-Instrument 데이터셋을 확장한 Kvasir-VQA 데이터셋을 소개합니다. 이 데이터셋은 위장관(GI) 진단 분야의 고급 기계 학습 태스크를 위해 질문-답변 주석이 추가된 6,500개의 annotated 이미지로 구성되어 있습니다. 다양한 GI 트랙트 상태와 수술 기구를 포함하며, 예/아니오, 선택, 위치, 수치 계산 등 다양한 유형의 질문을 지원합니다. 이미지 캡셔닝, Visual Question Answering(VQA), 합성 의료 이미지 생성, 객체 감지, 분류 등의 응용 분야를 위해 설계되었습니다. 실험 결과, 세 가지 선택된 태스크에서 모델 훈련에 효과적임을 입증했습니다.
OLMoE: Open Mixture-of-Experts Language Models
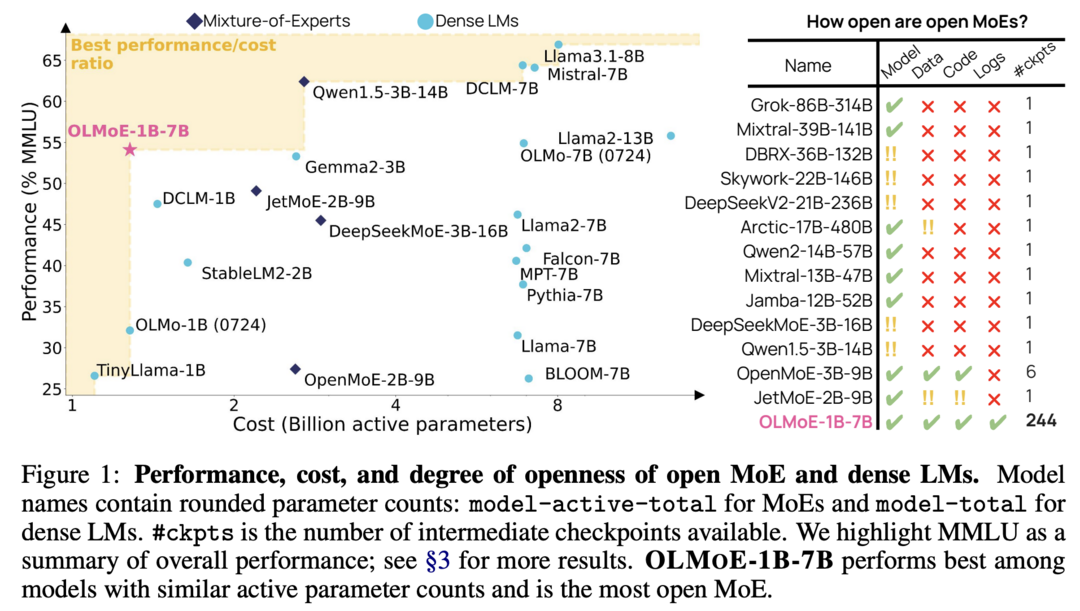
이 연구는 완전히 개방된 최첨단 언어 모델인 OLMoE를 소개합니다. OLMoE-1B-7B는 70억 개의 매개변수를 가지지만 입력 토큰당 10억 개만 사용합니다. 연구진은 이 모델을 5조 개의 토큰으로 사전 훈련시키고 추가로 적응시켜 OLMoE-1B-7B-Instruct를 만들었습니다. 이 모델들은 유사한 활성 매개변수를 가진 모든 사용 가능한 모델들을 능가하며, Llama2-13B-Chat와 DeepSeekMoE-16B와 같은 더 큰 모델들도 능가합니다. 연구진은 MoE 훈련에 대한 다양한 실험을 수행하고, 모델의 라우팅을 분석하여 높은 전문화를 보여주었습니다. 모델 가중치, 훈련 데이터, 코드, 로그 등 모든 측면을 오픈소스로 공개했습니다.
LongRecipe: Recipe for Efficient Long Context Generalization in Large Languge Models
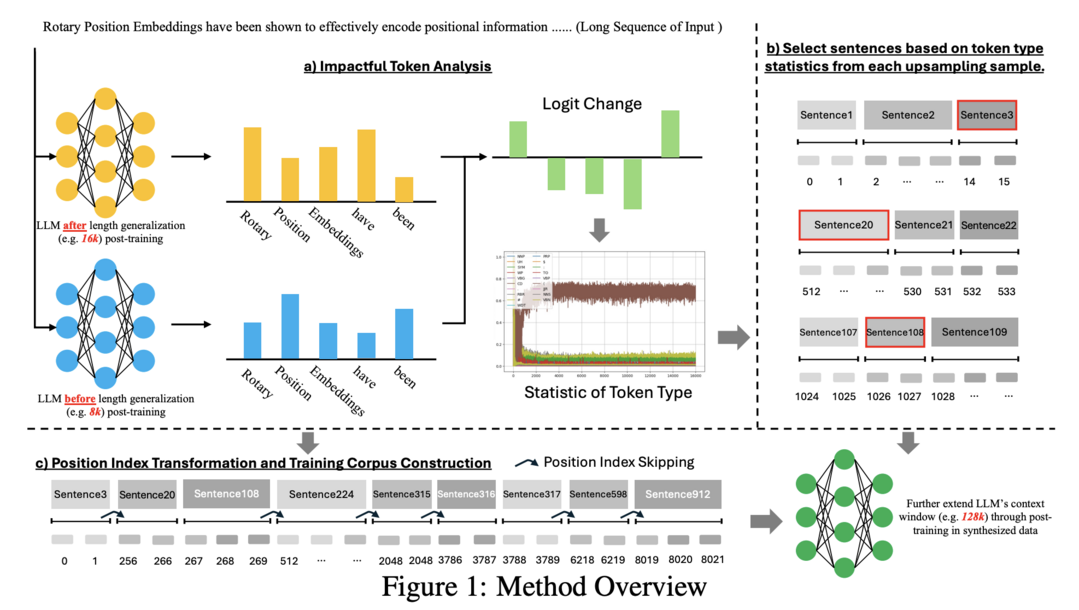
이 논문은 LLM의 컨텍스트 윈도우를 확장하기 위한 효율적인 훈련 전략인 LongRecipe를 소개합니다. 이 방법은 impactful token 분석, 위치 인덱스 변환, 훈련 최적화 전략을 포함하며, 훈련 효율성을 유지하면서 긴 시퀀스 입력을 시뮬레이션하여 모델의 장거리 의존성 이해를 크게 향상시킵니다. 세 가지 유형의 LLM에 대한 실험 결과, LongRecipe는 목표 컨텍스트 윈도우 크기의 30%만 사용하면서도 긴 시퀀스를 활용할 수 있으며, 전체 시퀀스 훈련에 비해 85% 이상의 계산 훈련 리소스를 절감했습니다. 또한 일반 태스크에서 원래 LLM의 능력을 유지합니다. 결과적으로 오픈소스 LLM의 효과적인 컨텍스트 윈도우를 8k에서 128k로 확장하여 GPT-4에 근접한 성능을 달성했습니다.
Loopy: Taming Audio-Driven Portrait Avatar with Long-Term Motion Dependency

이 논문은 오디오 기반 인물 비디오 생성을 위한 새로운 방법인 Loopy를 제안합니다. 연구진은 inter- 및 intra-clip temporal 모듈과 audio-to-latents 모듈을 설계하여 모델이 데이터의 장기 모션 정보를 활용하여 자연스러운 모션 패턴을 학습하고 오디오-초상화 움직임 상관관계를 개선할 수 있게 했습니다. 이 방법은 기존 방법들이 추론 중 모션을 제한하기 위해 사용하던 수동으로 지정된 공간 모션 템플릿의 필요성을 제거합니다. 광범위한 실험 결과, Loopy는 최근의 오디오 기반 초상화 diffusion 모델들을 능가하며 다양한 시나리오에서 더 생동감 있고 고품질의 결과를 제공합니다.
LongLLaVA: Scaling Multi-modal LLMs to 1000 Images Efficiently via Hybrid Architecture
이 연구는 Multi-modal Large Language Model(MLLM)의 장기 컨텍스트 능력을 확장하기 위한 LongLLaVA를 소개합니다. 연구진은 Mamba와 Transformer 블록의 하이브리드 모델 아키텍처를 채택하고, 다중 이미지 간의 시간적, 공간적 의존성을 고려한 데이터 구성 접근법을 사용하며, 점진적 훈련 전략을 채택했습니다. LongLLaVA는 다양한 벤치마크에서 경쟁력 있는 결과를 달성했을 뿐만 아니라 높은 처리량과 낮은 메모리 소비를 유지합니다. 특히 단일 A100 80GB GPU에서 거의 1000개의 이미지를 처리할 수 있어 광범위한 태스크에 대한 유망한 응용 가능성을 보여줍니다.
LongCite: Enabling LLMs to Generate Fine-grained Citations in Long-context QA

이 논문은 장기 컨텍스트 LLM이 세밀한 문장 수준의 인용을 생성할 수 있게 하는 LongCite를 소개합니다. 연구진은 먼저 현재 LLM의 인용이 포함된 장기 컨텍스트 질문 답변(LQAC) 성능을 평가하기 위한 자동화된 벤치마크인 LongBench-Cite를 도입했습니다. 이를 위해 기성 LLM을 활용하여 정확한 문장 수준 인용이 포함된 장기 컨텍스트 QA 인스턴스를 자동으로 생성하는 CoF(Coarse to Fine) 파이프라인을 제안했습니다. 이 파이프라인을 활용하여 LQAC를 위한 대규모 SFT 데이터셋인 LongCite-45k를 구축했습니다. 최종적으로 LongCite-45k 데이터셋을 사용하여 훈련된 LongCite-8B와 LongCite-9B는 LongBench-Cite 평가에서 GPT-4를 포함한 고급 독점 모델들을 능가하는 최고의 인용 품질을 달성했습니다.
Guide-and-Rescale: Self-Guidance Mechanism for Effective Tuning-Free Real Image Editing

이 논문은 실제 이미지 편집을 위한 새로운 접근 방식인 Guide-and-Rescale을 제안합니다. 연구진은 수정된 diffusion 샘플링 프로세스를 통해 자체 가이던스 기술을 탐구하여 입력 이미지의 전체 구조와 편집되지 않아야 할 로컬 영역의 외관을 보존합니다. 특히 소스 이미지의 로컬 및 글로벌 구조를 보존하기 위한 레이아웃 보존 에너지 함수를 도입했습니다. 또한 생성 과정에서 classifier-free 가이던스와 제안된 가이더의 norm을 균형 잡아 노이즈 분포를 보존하는 노이즈 rescaling 메커니즘을 제안했습니다. 이 접근 방식은 diffusion 모델의 미세 조정이나 정확한 inversion 프로세스를 필요로 하지 않아 빠르고 고품질의 편집 메커니즘을 제공합니다. 인간 평가와 정량적 분석을 통해 제안된 방법이 원본 이미지의 보존과 편집 품질 사이의 더 나은 균형을 달성함을 보여주었습니다.
Attention Heads of Large Language Models: A Survey
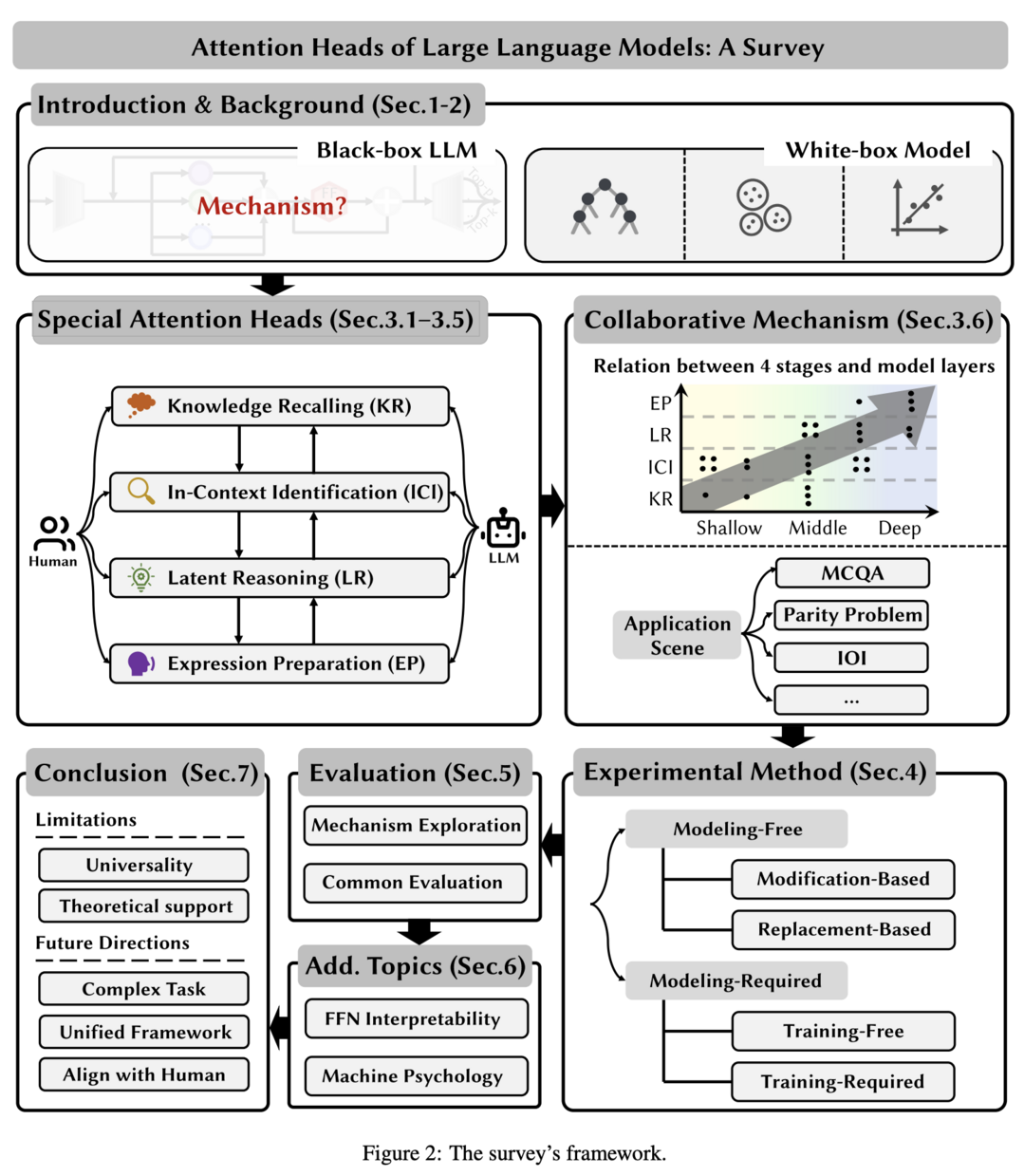
이 논문은 LLM의 내부 추론 과정을 이해하기 위해 attention head의 해석 가능성과 기본 메커니즘에 초점을 맞춘 포괄적인 survey를 제공합니다. 연구진은 인간의 사고 과정을 지식 회상, 컨텍스트 내 식별, 잠재적 추론, 표현 준비의 4단계 프레임워크로 정제했습니다. 이 프레임워크를 사용하여 기존 연구를 체계적으로 검토하여 특정 attention head의 기능을 식별하고 분류했습니다. 또한 이러한 특수 head를 발견하는 데 사용된 실험 방법론을 Modeling-Free 방법과 Modeling-Required 방법의 두 가지 범주로 요약했습니다. 관련 평가 방법과 벤치마크도 개괄적으로 설명했습니다. 마지막으로 현재 연구의 한계를 논의하고 여러 잠재적 미래 방향을 제안했습니다.
FuzzCoder: Byte-level Fuzzing Test via Large Language Model
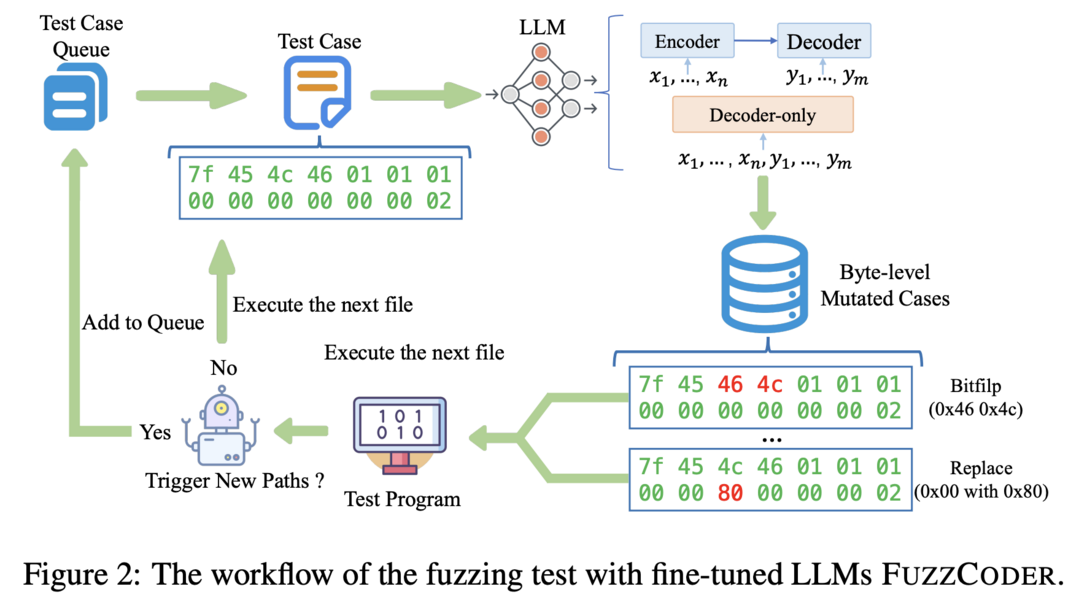
이 논문은 LLM을 활용하여 fuzzing 과정을 개선하는 FuzzCoder를 제안합니다. Fuzzing은 복잡한 소프트웨어의 취약점을 찾기 위한 중요한 동적 프로그램 분석 기술입니다. 연구진은 코드 LLM을 활용하여 fuzzing의 입력 변이 프로세스를 안내하는 프레임워크를 개발했습니다. 변이 프로세스를 sequence-to-sequence 모델링으로 공식화하여 LLM이 바이트 시퀀스를 받아 변이된 바이트 시퀀스를 출력하도록 했습니다. FuzzCoder는 휴리스틱 fuzzing 도구에서 수집된 성공적인 fuzzing 기록으로 생성된 Fuzz-Instruct 데이터셋으로 미세 조정되었습니다. 이를 통해 FuzzCoder는 프로그램의 비정상적 동작을 유발하는 입력 파일의 변이 위치와 전략을 예측할 수 있습니다. 실험 결과, AFL(American Fuzzy Lop) 기반의 FuzzCoder는 ELF, JPG, MP3, XML 등 다양한 입력 형식에 대해 유효 변이 비율(EPM)과 크래시 수(NC) 측면에서 상당한 개선을 보였습니다.
[저작권자ⓒ META-X. 무단전재-재배포 금지]