2024년 W37/W38에 공개된 주목할만한 인공지능(AI) 분야의 논문들을 소개합니다.
TL;DR
아래 논문들은 LLM 평가, 멀티모달 모델, 음성 및 음악 생성, 이미지 생성, LLM 개선에 대한 내용들을 다루고 있습니다.
- LLM 평가: MEDIC는 임상 응용을 위한 LLM 평가 프레임워크를 제시하고, PingPong은 역할 수행 능력 평가를 위한 벤치마크를 소개하며, DSBench는 데이터 사이언스 에이전트 평가를 위한 현실적인 작업을 제공합니다.
- 멀티모달 모델: NVLM과 Qwen2-VL은 각각 최첨단 멀티모달 LLM과 동적 해상도 처리 기능을 갖춘 비전-언어 모델을 제안합니다.
- 음성 및 음악 생성: LLaMA-Omni는 저지연 음성 상호작용 모델을, Seed-Music은 제어 가능한 음악 생성 프레임워크를 소개합니다.
- 이미지 생성: OmniGen은 통합된 이미지 생성을 위한 새로운 diffusion 모델을 제시합니다.
- LLM 개선: LLM의 선호도 학습에 대한 통합된 관점을 제공하는 서베이와 강화학습을 통한 LLM의 Self-Correct 능력 향상 연구가 소개되었습니다.
Towards a Unified View of Preference Learning for Large Language Models: A Survey
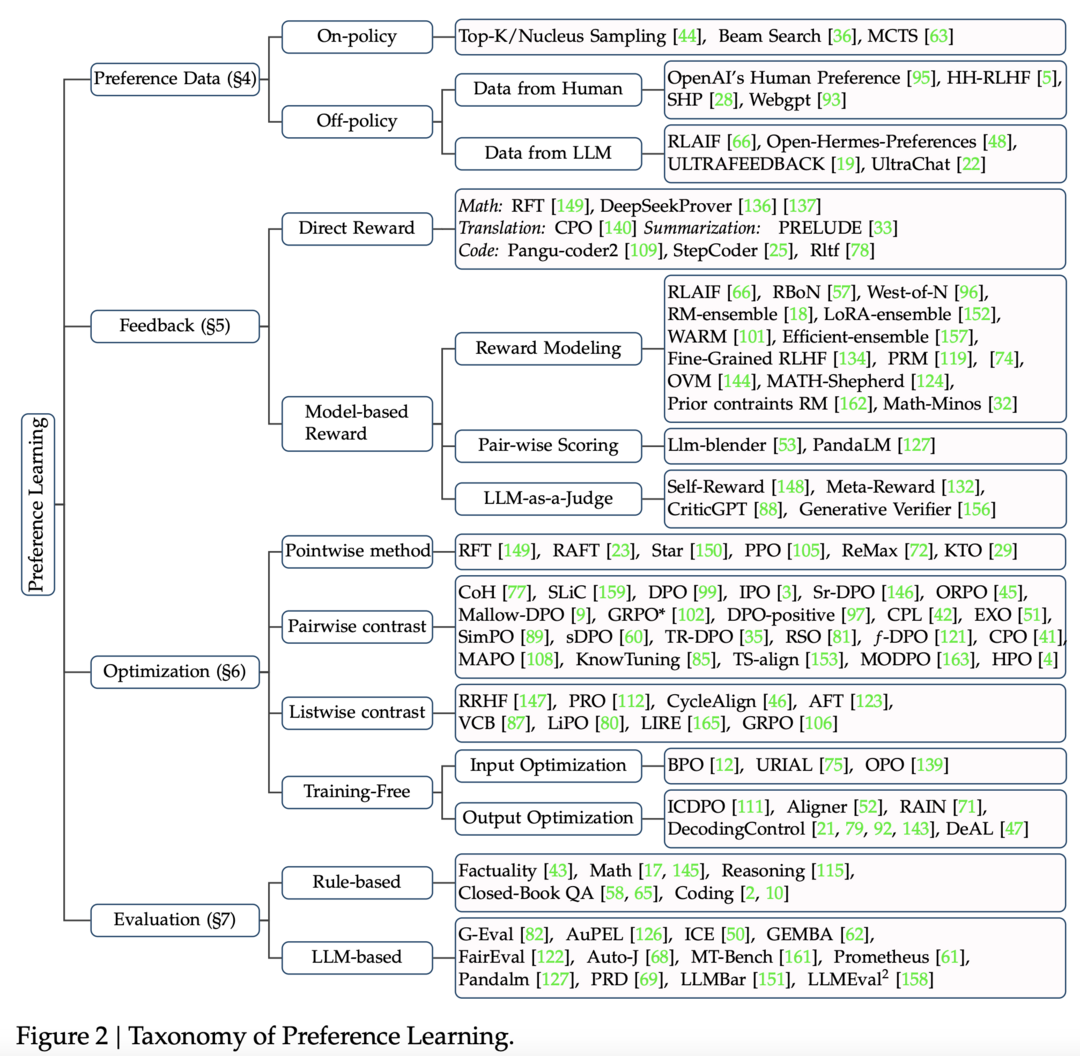
이 논문은 Large Language Models(LLMs)의 출력을 인간의 선호도와 일치시키는 과정에 대해 통합된 관점을 제시하는 Survey 입니다. 해당 논문에서는 기존의 선호도 학습 전략들을 모델, 데이터, 피드백, 알고리즘의 네 가지 구성 요소로 분해하여 분석합니다. 이러한 통합된 시각은 기존 alignment 알고리즘에 대한 깊이 있는 이해를 제공하고, 다양한 전략들의 장점을 결합할 수 있는 가능성을 열어줍니다. 또한 논문은 주요 알고리즘들의 상세한 작동 예시를 제공하고, LLM을 인간의 선호도와 일치시키는 데 있어서의 도전 과제와 향후 연구 방향을 탐색합니다.
LLaMA-Omni: Seamless Speech Interaction with Large Language Models
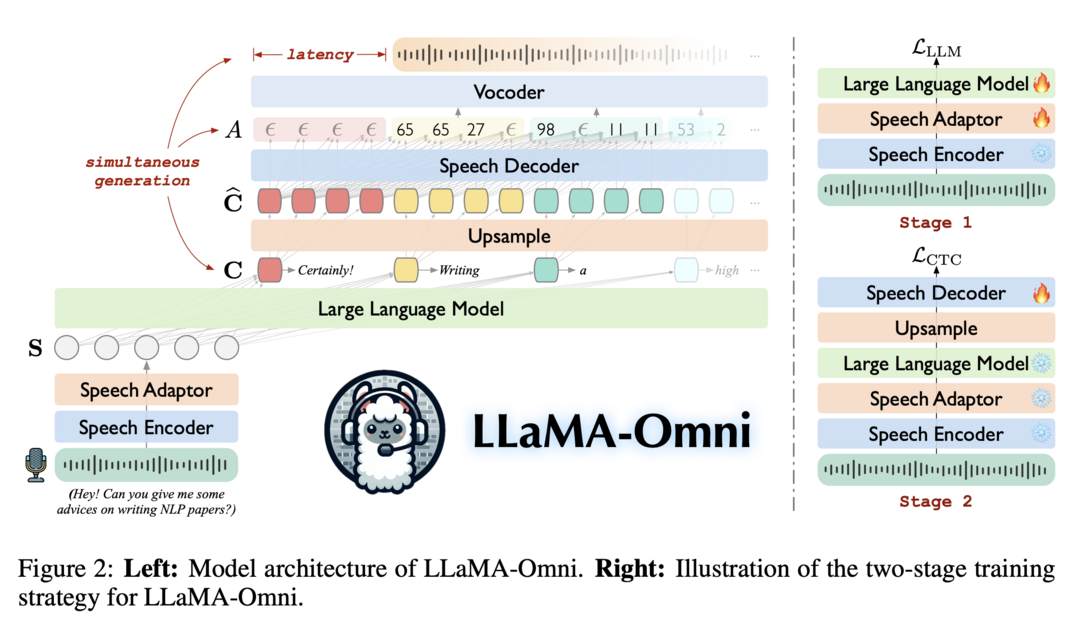
LLaMA-Omni는 오픈소스 LLM을 기반으로 한 저지연, 고품질 음성 상호작용 모델 아키텍처입니다. 이 모델은 사전 학습된 speech encoder, speech adaptor, LLM, 그리고 streaming speech decoder를 통합하여 음성 전사 과정 없이 음성 지시로부터 직접 텍스트와 음성 응답을 동시에 생성합니다. Llama-3.1-8B-Instruct 모델을 기반으로 구축되었으며, 200K개의 음성 지시와 응답을 포함하는 InstructS2S-200K 데이터셋을 사용해 학습되었습니다. 실험 결과, LLaMA-Omni는 기존 speech-language 모델들에 비해 더 나은 내용과 스타일의 응답을 제공하며, 응답 지연 시간은 226ms에 불과합니다.
PingPong: A Benchmark for Role-Playing Language Models with User Emulation and Multi-Model Evaluation
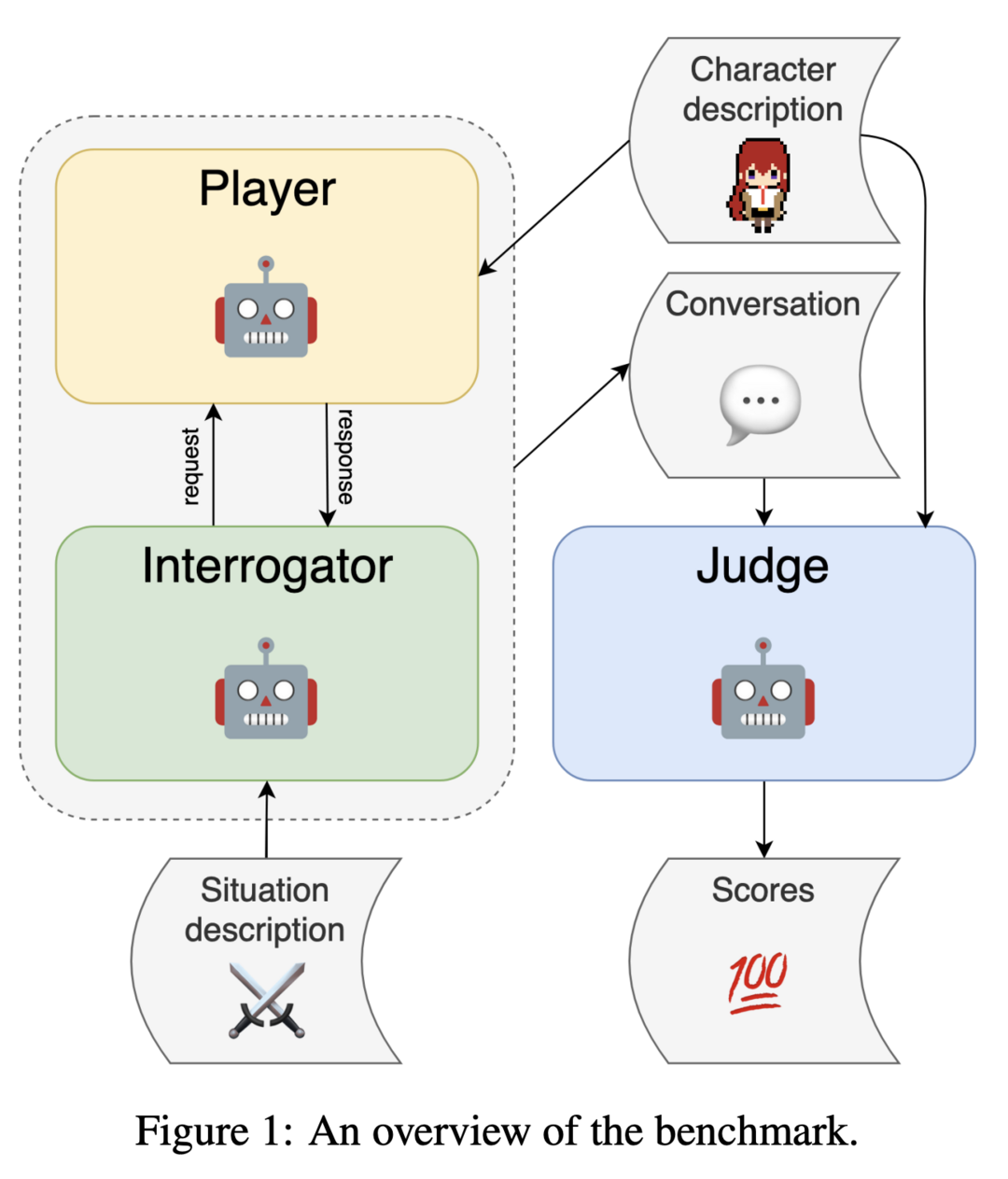
PingPong은 언어 모델의 역할 수행 능력을 평가하기 위한 새로운 벤치마크입니다. 이 접근 방식은 언어 모델 자체를 활용하여 동적인 다중 턴 대화에서 사용자를 모방하고 결과 대화를 평가합니다. 프레임워크는 특정 캐릭터 역할을 맡는 player 모델, 사용자 행동을 시뮬레이션하는 interrogator 모델, 그리고 대화 품질을 평가하는 judge 모델로 구성됩니다. 자동화된 평가와 인간 주석을 비교하는 실험을 통해 접근 방식의 유효성을 검증했으며, 여러 기준에서 강한 상관관계를 보여주었습니다. 이 연구는 대화형 시나리오에서 모델 능력의 강력하고 동적인 평가를 위한 기반을 제공합니다.
MEDIC: Towards a Comprehensive Framework for Evaluating LLMs in Clinical Applications
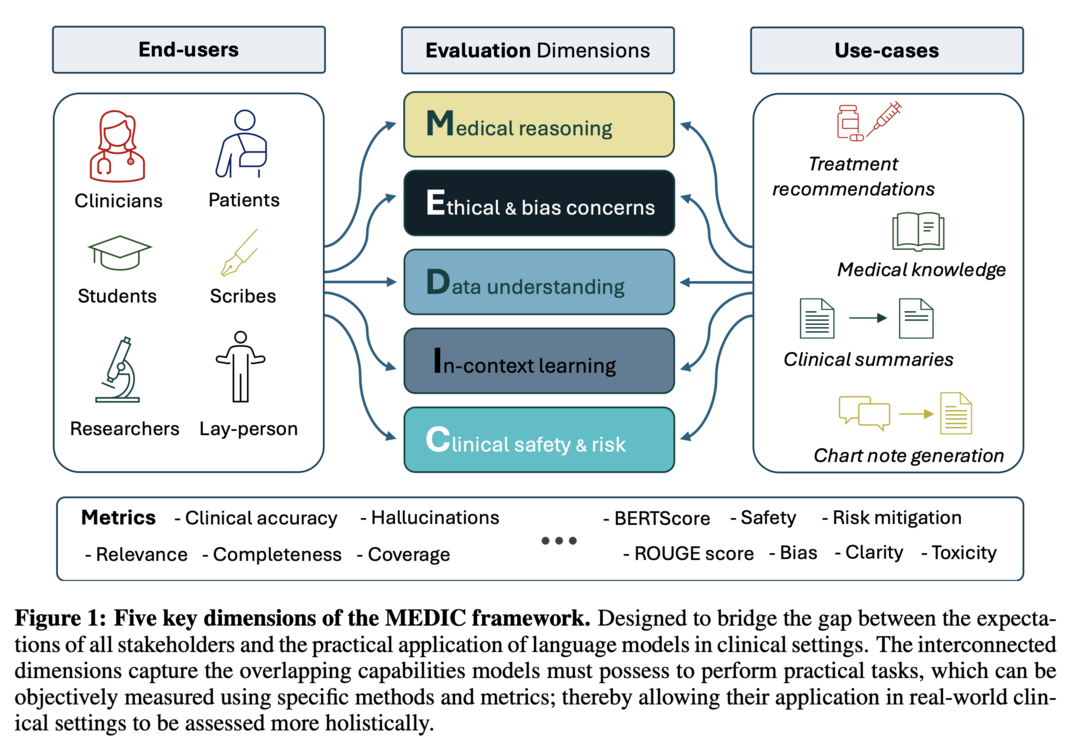
MEDIC는 LLM의 임상 응용 능력을 평가하기 위한 포괄적인 프레임워크입니다. 이 프레임워크는 의학적 추론, 윤리와 편견, 데이터 및 언어 이해, 맥락 내 학습, 그리고 임상 안전성이라는 다섯 가지 핵심 차원에서 LLM을 평가합니다. MEDIC는 참조 출력 없이도 LLM의 성능을 정량화할 수 있는 새로운 교차 검증 프레임워크를 특징으로 합니다. 의료 질문 답변, 안전성, 요약, 노트 생성 등의 작업에서 LLM을 평가한 결과, 모델 크기, 기본 모델과 의학적으로 미세 조정된 모델 간의 성능 차이를 보여주었습니다. MEDIC의 다면적 평가는 이러한 성능 트레이드오프를 드러내어 이론적 능력과 의료 환경에서의 실제 구현 사이의 격차를 좁히는 데 기여합니다.
DSBench: How Far Are Data Science Agents to Becoming Data Science Experts?

DSBench는 데이터 사이언스 에이전트를 현실적인 작업으로 평가하기 위해 설계된 포괄적인 벤치마크입니다. Eloquence와 Kaggle 대회에서 추출한 466개의 데이터 분석 작업과 74개의 데이터 모델링 작업을 포함하며, 긴 컨텍스트, 멀티모달 작업 배경, 대규모 데이터 파일 및 다중 테이블 구조를 사용한 추론, 그리고 엔드-투-엔드 데이터 모델링 작업 수행 등 현실적인 설정을 제공합니다. 최신 LLM, LVLM, 에이전트에 대한 평가 결과, 가장 우수한 에이전트도 데이터 분석 작업의 34.12%만 해결했으며, 34.74%의 Relative Performance Gap(RPG)을 기록했습니다. 이러한 결과는 더욱 실용적이고 지능적이며 자율적인 데이터 사이언스 에이전트 개발의 필요성을 강조합니다.
Seed-Music: A Unified Framework for High Quality and Controlled Music Generation
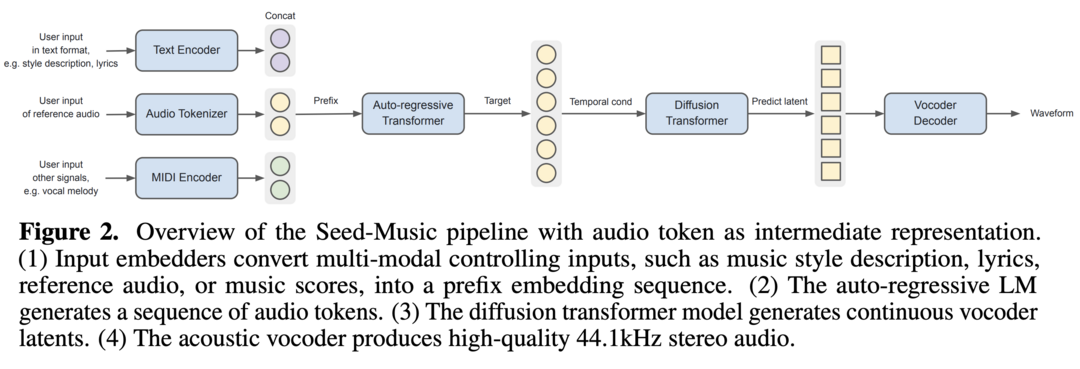
Seed-Music은 세밀한 스타일 제어가 가능한 고품질 음악 생성 시스템입니다. 이 통합 프레임워크는 auto-regressive language modeling과 diffusion 접근 방식을 모두 활용하여 두 가지 주요 음악 제작 워크플로우를 지원합니다: 제어된 음악 생성과 후반 작업 편집입니다. 제어된 음악 생성에서는 스타일 설명, 오디오 참조, 악보, 음성 프롬프트 등 다양한 멀티모달 입력을 통해 보컬 음악 생성의 성능을 제어할 수 있습니다. 후반 작업 편집에서는 생성된 오디오에서 직접 가사와 보컬 멜로디를 편집할 수 있는 대화형 도구를 제공합니다. 이 시스템은 음악 생성 분야에서 유연성과 제어 가능성을 크게 향상시킵니다.
OmniGen: Unified Image Generation

OmniGen은 통합된 이미지 생성을 위한 새로운 diffusion 모델입니다. 기존의 인기 있는 diffusion 모델들과 달리, OmniGen은 다양한 제어 조건을 처리하기 위해 ControlNet이나 IP-Adapter와 같은 추가 모듈을 필요로 하지 않습니다. 이 모델은 텍스트-이미지 생성 능력뿐만 아니라 이미지 편집, 주제 기반 생성, 시각적 조건부 생성과 같은 다운스트림 작업도 본질적으로 지원합니다. 또한 엣지 감지나 인간 포즈 인식과 같은 고전적인 컴퓨터 비전 작업을 이미지 생성 작업으로 변환하여 처리할 수 있습니다. OmniGen의 아키텍처는 매우 간단화되어 있어 추가적인 텍스트 인코더가 필요하지 않으며, 복잡한 작업을 지시만으로 수행할 수 있어 사용자 친화적입니다. 통합된 형식으로의 학습을 통해 OmniGen은 다양한 작업 간에 지식을 효과적으로 전이하고, 새로운 작업과 도메인을 관리하며, 새로운 능력을 보여줍니다.
NVLM: Open Frontier-Class Multimodal LLMs
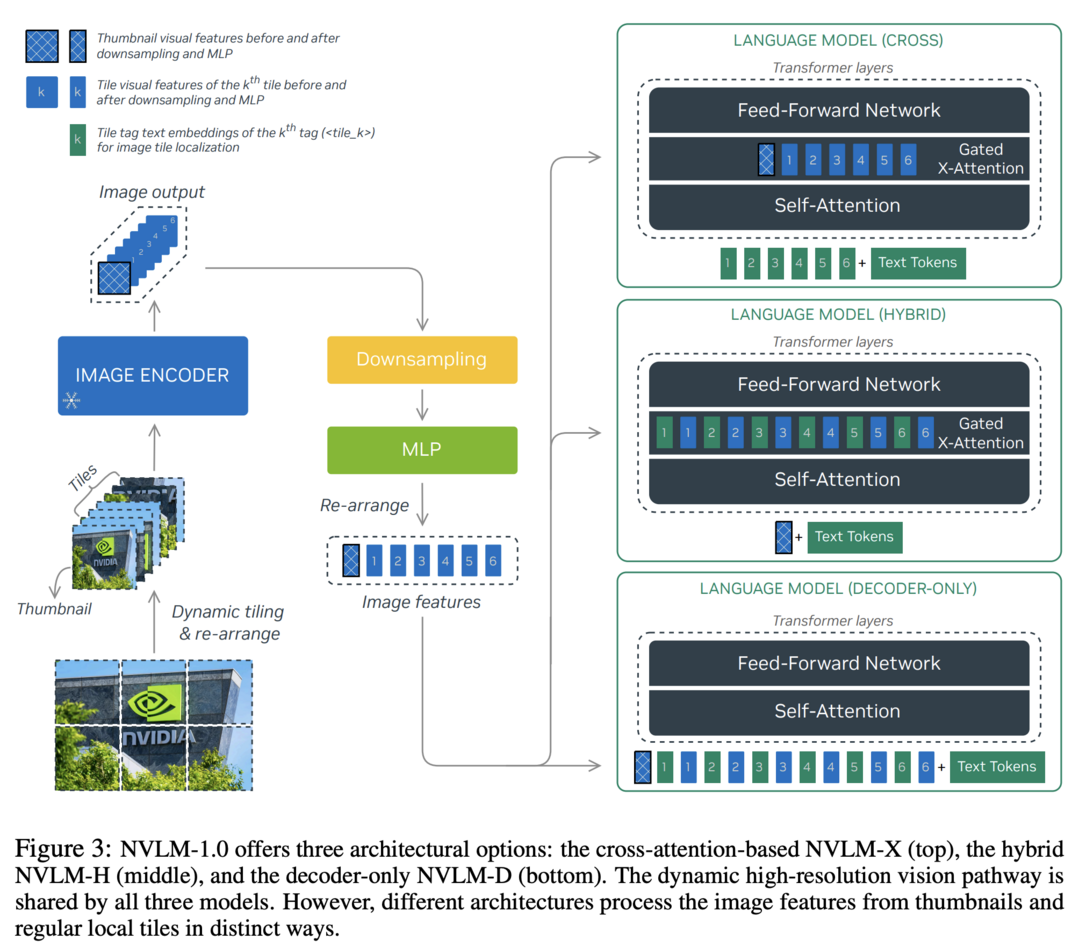
NVLM 1.0은 최첨단 멀티모달 large language models(LLMs) 제품군으로, vision-language 작업에서 GPT-4o나 Llama 3-V 405B, InternVL 2와 같은 선두 모델들과 견줄 만한 성능을 보여줍니다. 주목할 만한 점은 NVLM 1.0이 멀티모달 학습 후에도 텍스트 전용 성능이 향상되었다는 것입니다. 이 연구는 decoder-only 멀티모달 LLM과 cross-attention 기반 모델을 포괄적으로 비교하고, 두 접근 방식의 장단점을 바탕으로 학습 효율성과 멀티모달 추론 능력을 향상시키는 새로운 아키텍처를 제안합니다. 또한 타일 기반 동적 고해상도 이미지를 위한 1-D tile-tagging 설계를 도입하여 멀티모달 추론 및 OCR 관련 작업의 성능을 크게 향상시켰습니다. NVLM 1.0 모델은 고품질 텍스트 전용 데이터셋과 상당량의 멀티모달 수학 및 추론 데이터를 통합하여 모달리티 간 수학 및 코딩 능력을 향상시켰습니다.
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
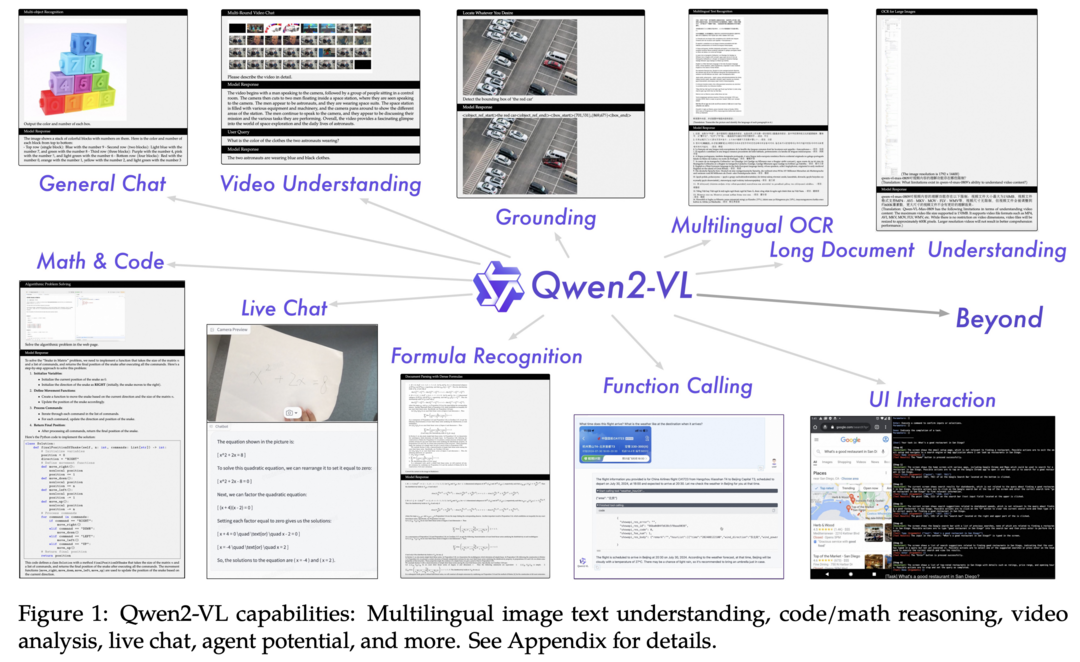
Qwen2-VL 시리즈는 기존의 Qwen-VL 모델을 고도화한 버전으로, 시각적 처리에서 기존의 고정 해상도 접근 방식을 재정의합니다. 이 모델은 Naive Dynamic Resolution 메커니즘을 도입하여 다양한 해상도의 이미지를 동적으로 처리하고 다른 수의 시각적 토큰으로 변환할 수 있습니다. 또한 Multimodal Rotary Position Embedding(M-RoPE)을 통합하여 텍스트, 이미지, 비디오 간의 위치 정보를 효과적으로 융합합니다. Qwen2-VL은 이미지와 비디오 처리를 위한 통합된 패러다임을 채택하여 모델의 시각적 인식 능력을 향상시켰습니다. 이 연구는 2B, 8B, 72B 매개변수 버전의 모델을 통해 large vision-language models(LVLMs)의 스케일링 법칙을 탐구하며, Qwen2-VL-72B 모델은 다양한 멀티모달 벤치마크에서 GPT-4v와 Claude3.5-Sonnet에 필적하는 결과를 달성했습니다.
Training Language Models to Self-Correct via Reinforcement Learning
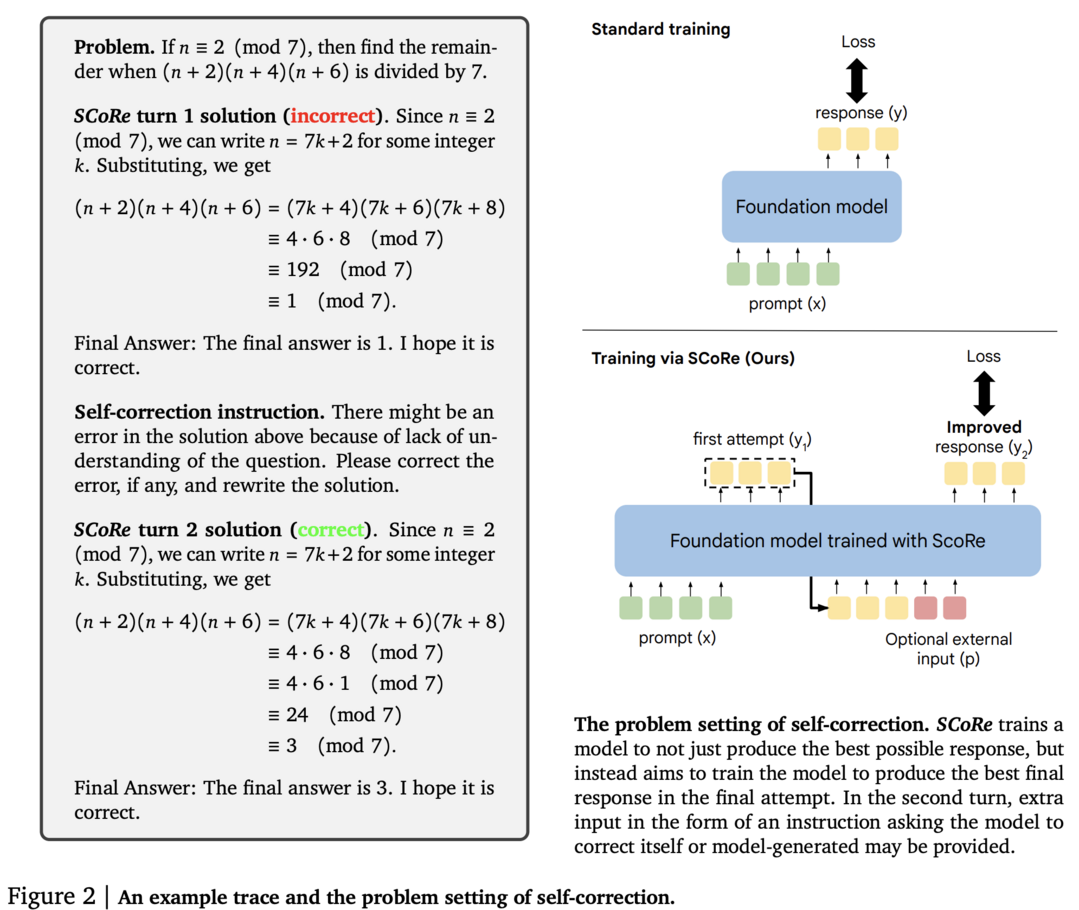
이 연구는 대규모 언어 모델(LLMs)의 Self-Correct 능력을 향상시키기 위한 다중 턴 온라인 강화 학습(RL) 접근 방식인 SCoRe를 제시합니다. SCoRe는 모델이 자체 생성한 데이터만을 사용하여 Self-Correct 능력을 크게 개선합니다. 연구진은 먼저 오프라인에서 모델이 생성한 수정 트레이스에 대한 지도 학습(SFT) 변형이 Self-Correct 행동을 주입하는 데 불충분함을 보여줍니다. SCoRe는 모델 자체의 자체 생성된 수정 트레이스 분포 하에서 학습하고 적절한 정규화를 사용하여 테스트 시 효과적인 Self-Correct 전략을 학습하도록 유도합니다. Gemini 1.0 Pro 및 1.5 Flash 모델에 적용된 SCoRe는 MATH 및 HumanEval 벤치마크에서 각각 15.6% 및 9.1%의 성능 향상을 보여주며, 최첨단 Self-Correct 성능을 달성했습니다.
[저작권자ⓒ META-X. 무단전재-재배포 금지]