2024년 W39/W40에 공개된 주목할만한 인공지능(AI) 분야의 논문들을 소개합니다.
TL;DR
아래 논문들은 이미지 생성, 데이터셋, 로봇 제어, 멀티모달 모델, LLM 능력 평가, 이미지-캡션 데이터 대한 내용들을 다루고 있습니다.
- 이미지 생성: Imagine yourself는 튜닝 없는 개인화 이미지 생성 모델을 제시합니다.
- 데이터셋: YesBut은 Vision-Language 모델의 풍자 이해력 평가를 위한 고품질 데이터셋을 소개합니다.
- 로봇 제어: RACER는 언어 기반 실패 복구 정책을 통해 로봇 조작 능력을 향상시킵니다. 언어 모델 평가: HelloBench는 LLMs의 장문 생성 능력을 평가하는 새로운 벤치마크를 제안합니다.
- 멀티모달 모델: Molmo는 오픈 소스 기반의 최첨단 멀티모달 모델을 소개하고, ProX는 LLM 사전 학습 데이터 품질을 향상시키는 프레임워크를 제시하며, MaskLLM은 LLMs의 효율성을 높이는 학습 가능한 희소성 방법을 제안합니다. Emu3는 next-token 예측만으로 멀티모달 태스크를 수행하는 혁신적인 접근법을 보여주고, MIO는 다양한 모달리티를 통합하는 새로운 foundation 모델을 소개합니다. MM1.5는 데이터 중심 접근법을 통해 MLLM의 성능을 향상시키는 방법을 제시합니다.
- LLM 능력 평가: Law of the Weakest Link는 LLMs의 cross capabilities를 체계적으로 분석합니다.
- 이미지-캡션 데이터: Revisit Large-Scale Image-Caption Data는 멀티모달 모델 사전 훈련에서 이미지-캡션 데이터의 역할을 재검토합니다.
Imagine yourself: Tuning-Free Personalized Image Generation
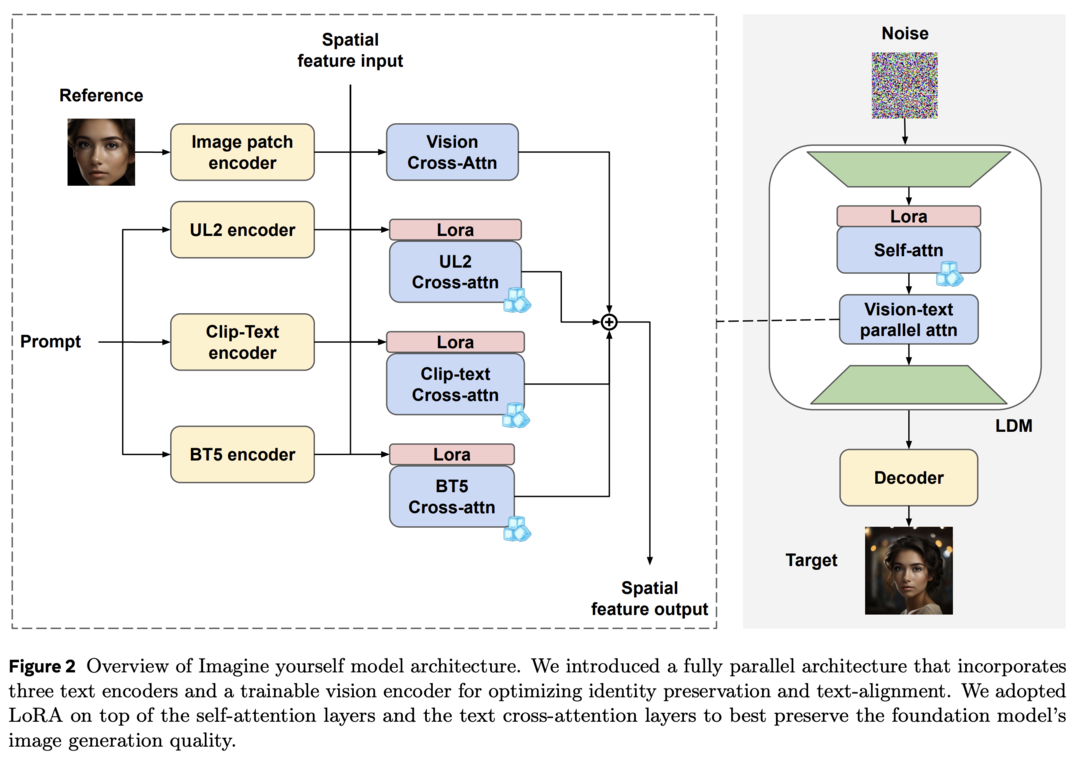
이 연구는 개인화된 이미지 생성을 위한 튜닝이 필요 없는 'Imagine yourself' 모델을 소개합니다. 이 모델은 새로운 합성 페어 데이터 생성 메커니즘, 세 개의 텍스트 인코더와 완전히 학습 가능한 비전 인코더를 갖춘 완전 병렬 어텐션 아키텍처, 그리고 coarse-to-fine 다단계 미세 조정 방법론을 도입하여 이미지 다양성, 텍스트 충실도, 시각적 품질을 향상시켰습니다. 결과적으로 ID 보존, 복잡한 프롬프트 따르기, 시각적 품질 유지 사이의 균형을 개선하여 최첨단 개인화 모델을 능가하는 성능을 보여줍니다.
YesBut: A High-Quality Annotated Multimodal Dataset for evaluating Satire Comprehension capability of Vision-Language Models
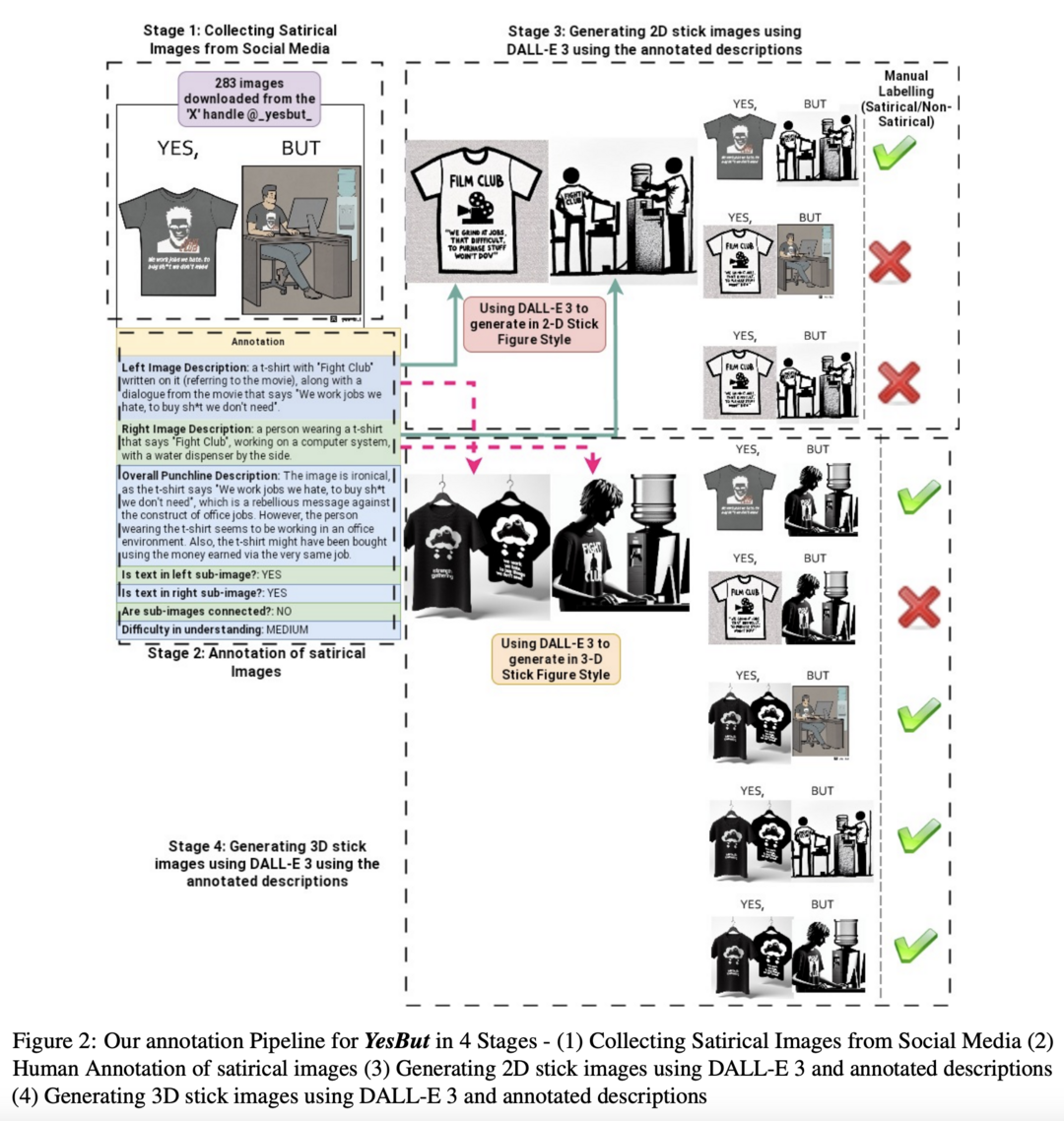
이 연구는 Vision-Language 모델의 풍자 이해 능력을 평가하기 위한 YesBut 데이터셋을 제안합니다. 2,547개의 이미지로 구성된 이 데이터셋은 풍자 이미지 감지, 이해, 완성이라는 도전적인 태스크를 포함합니다. 각 풍자 이미지는 일반적인 시나리오와 함께 재미있거나 아이러니한 상반된 시나리오를 보여줍니다. 실험 결과, 현재의 Vision-Language 모델들이 Visual QA와 Image Captioning 같은 멀티모달 태스크에서 성공을 거두었음에도 불구하고, Zero-Shot 설정에서 YesBut 데이터셋의 태스크에 대해 성능이 저조함을 보여줍니다.
RACER: Rich Language-Guided Failure Recovery Policies for Imitation Learning

이 연구는 로봇 조작을 위한 Rich languAge-guided failure reCovERy (RACER) 프레임워크를 제안합니다. RACER는 실패 복구 데이터와 풍부한 언어 설명을 결합하여 로봇 제어를 향상시킵니다. 이 프레임워크는 오류 수정과 태스크 실행을 위한 상세한 언어 가이드를 제공하는 vision-language model (VLM)과 다음 행동을 예측하는 language-conditioned visuomotor 정책을 특징으로 합니다. 실험 결과, RACER가 표준 long-horizon 태스크, 동적 목표 변경 태스크, zero-shot 미지 태스크를 포함한 다양한 평가 설정에서 우수한 성능을 보여주었습니다.
HelloBench: Evaluating Long Text Generation Capabilities of Large Language Models
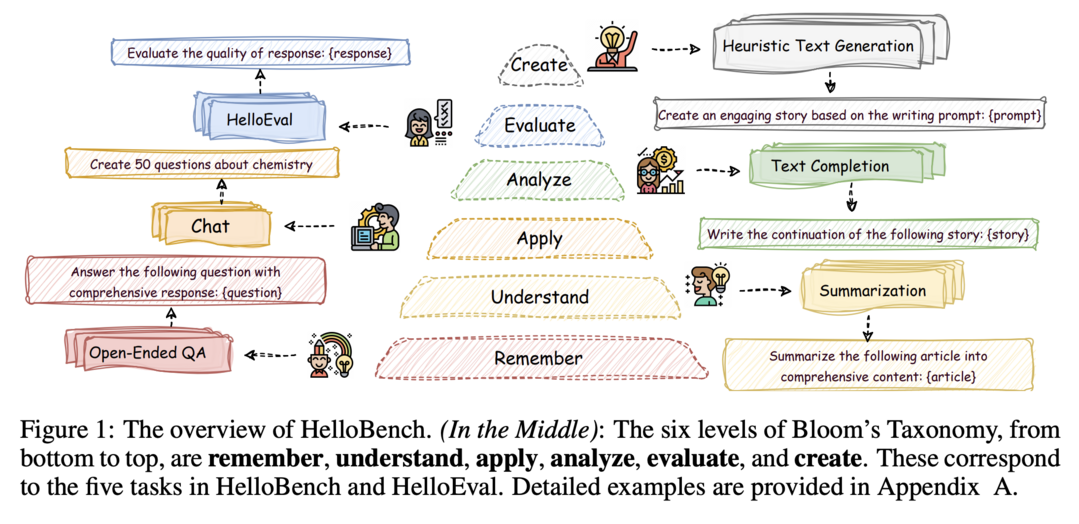
이 연구는 Large Language Models (LLMs)의 장문 생성 능력을 평가하기 위한 HelloBench를 소개합니다. HelloBench는 Bloom's Taxonomy를 기반으로 장문 생성 태스크를 다섯 가지 하위 태스크로 분류하고, 인간 평가와 높은 상관관계를 유지하면서 평가에 필요한 시간과 노력을 크게 줄이는 HelloEval 방법을 제안합니다. 약 30개의 주류 LLMs에 대한 광범위한 실험을 통해 현재 LLMs가 장문 생성 능력이 부족함을 관찰했으며, HelloEval이 전통적인 메트릭과 LLM-as-a-Judge 방법과 비교했을 때 인간 평가와 가장 높은 상관관계를 보인다는 것을 입증했습니다.
Molmo and PixMo: Open Weights and Open Data for State-of-the-Art Multimodal Models
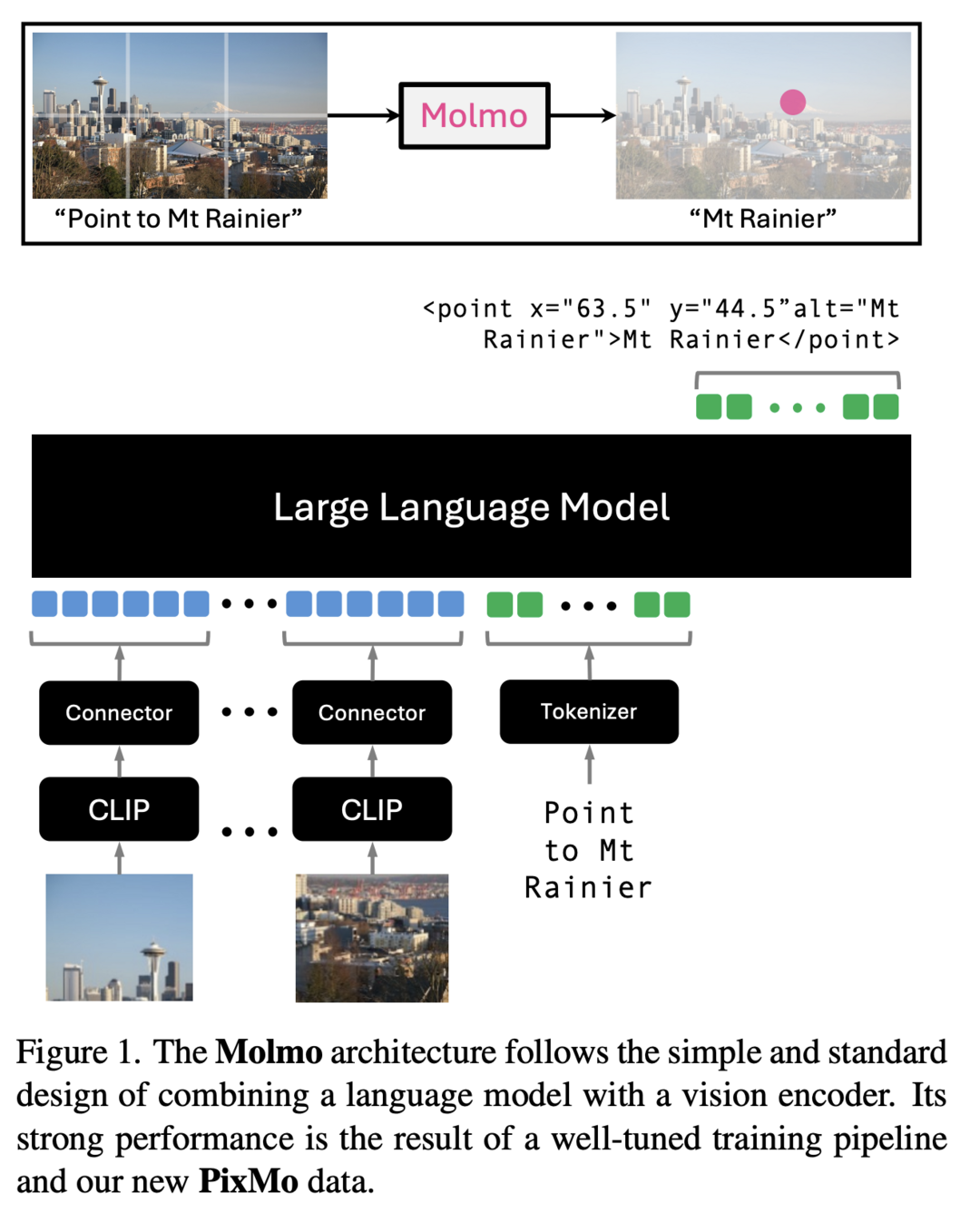
이 연구는 오픈 웨이트와 오픈 데이터를 기반으로 한 최첨단 멀티모달 모델 가족인 Molmo를 소개합니다. Molmo의 주요 혁신은 음성 기반 설명을 사용하여 인간 주석자로부터 수집한 상세한 이미지 캡션 데이터셋입니다. 또한, 다양한 사용자 상호작용을 가능하게 하기 위해 in-the-wild Q&A와 혁신적인 2D pointing 데이터를 포함한 다양한 데이터셋 혼합물을 fine-tuning에 도입했습니다. Molmo 가족 내 최고 성능의 72B 모델은 오픈 웨이트 및 데이터 모델 클래스에서 다른 모델들을 능가할 뿐만 아니라, 학술 벤치마크와 인간 평가에서 GPT-4o, Claude 3.5, Gemini 1.5와 같은 독점 시스템과 비교해도 우수한 성능을 보여줍니다.
Programming Every Example: Lifting Pre-training Data Quality like Experts at Scale
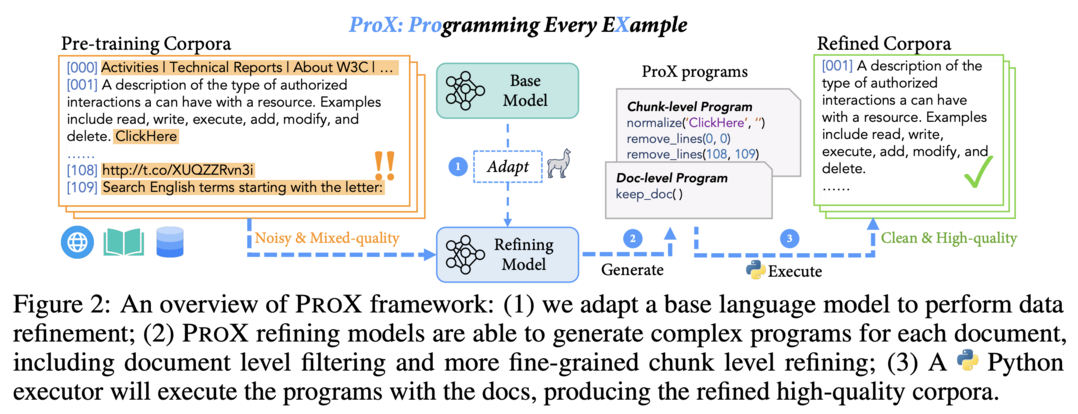
이 연구는 데이터 정제를 프로그래밍 태스크로 취급하여 모델이 각 개별 예제에 대해 세분화된 작업을 생성하고 실행함으로써 대규모로 코퍼스를 정제할 수 있게 하는 ProX 프레임워크를 소개합니다. 실험 결과, ProX로 정제된 데이터로 사전 학습된 모델이 다양한 downstream 벤치마크에서 원본 데이터나 다른 선택 방법으로 필터링된 데이터보다 2% 이상 우수한 성능을 보였습니다. 또한, ProX는 도메인 특정 continual pre-training에서 상당한 잠재력을 보여, 인간이 만든 규칙 기반 방법을 능가하는 성능을 달성했으며, 훈련 FLOPs를 크게 절약하여 효율적인 LLM 사전 학습을 위한 유망한 경로를 제시합니다.
MaskLLM: Learnable Semi-Structured Sparsity for Large Language Models
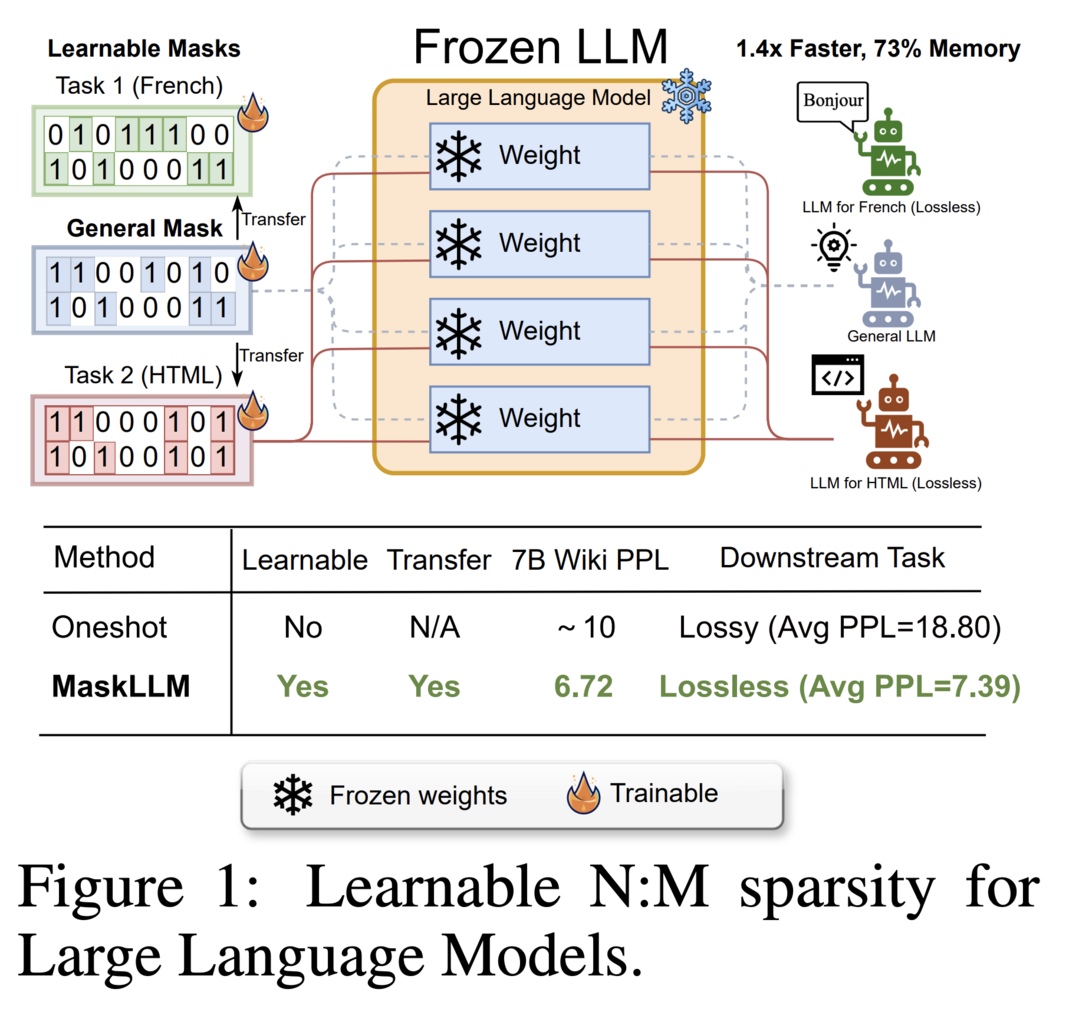
이 연구는 Large Language Models (LLMs)의 추론 시 계산 오버헤드를 줄이기 위해 Semi-structured (또는 "N:M") Sparsity를 확립하는 학습 가능한 가지치기 방법인 MaskLLM을 소개합니다. MaskLLM은 N:M 패턴을 Gumbel Softmax 샘플링을 통해 학습 가능한 분포로 명시적으로 모델링합니다. 이 접근 방식은 대규모 데이터셋에서의 end-to-end 훈련을 용이하게 하고, 고품질 마스크 생성과 도메인 또는 태스크 간 희소성의 전이 학습을 가능하게 합니다. LLaMA-2, Nemotron-4, GPT-3 등 다양한 LLMs에 대해 2:4 희소성을 사용하여 MaskLLM을 평가한 결과, state-of-the-art 방법들을 크게 능가하는 성능을 보여주었습니다.
Emu3: Next-Token Prediction is All You Need
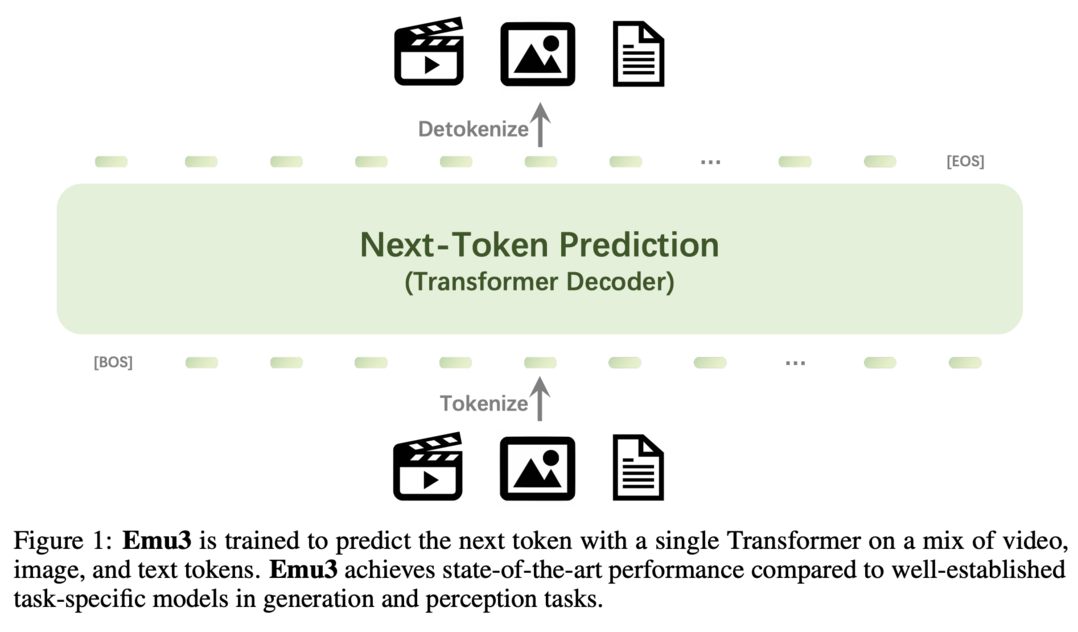
이 연구는 next-token 예측만을 사용하여 훈련된 최첨단 멀티모달 모델 suite인 Emu3를 소개합니다. Emu3는 이미지, 텍스트, 비디오를 이산 공간으로 토큰화하고, 멀티모달 시퀀스 혼합물에 대해 단일 transformer를 처음부터 훈련시킵니다. 이 모델은 생성 및 인식 태스크에서 SDXL과 LLaVA-1.6 같은 주요 모델들을 능가하면서, diffusion이나 compositional 아키텍처의 필요성을 제거합니다. Emu3는 또한 비디오 시퀀스에서 다음 토큰을 예측함으로써 고품질 비디오 생성이 가능합니다. 이 연구는 복잡한 멀티모달 모델 설계를 토큰에 대한 단일 초점으로 단순화하여, 훈련과 추론 과정에서 큰 잠재력을 unlock합니다.
MIO: A Foundation Model on Multimodal Tokens
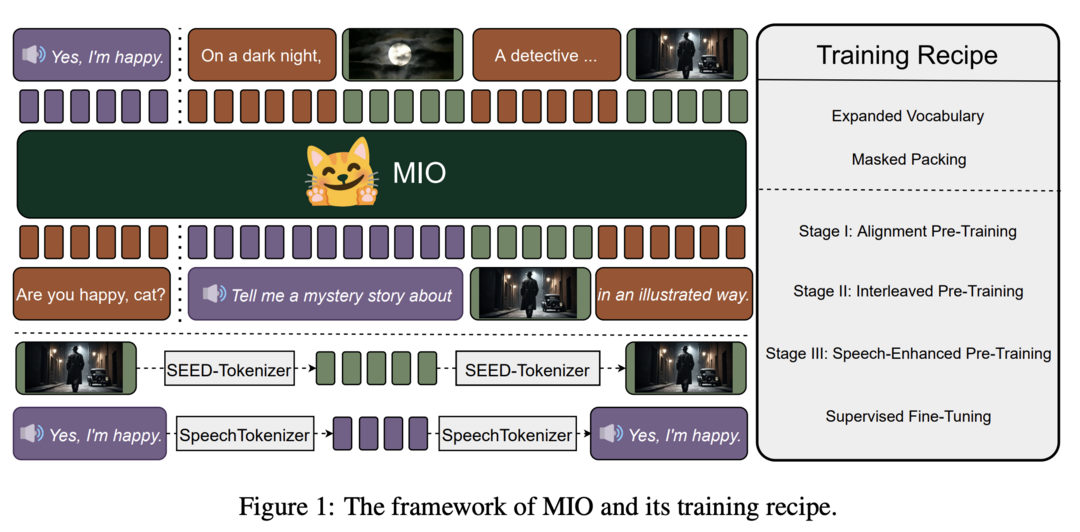 이 연구는 speech, text, images, videos를 end-to-end, autoregressive 방식으로 이해하고 생성할 수 있는 새로운 foundation 모델인 MIO를 소개합니다. MIO는 네 가지 모달리티에 걸친 이산 토큰의 혼합물에 대해 causal multimodal modeling을 사용하여 훈련됩니다. 이 모델은 4단계 훈련 과정을 거치며, 실험 결과 이전의 dual-modal 베이스라인, any-to-any 모델 베이스라인, 심지어 모달리티 특정 베이스라인과 비교해서 경쟁력 있는, 때로는 우수한 성능을 보여줍니다. 또한, MIO는 interleaved video-text generation, chain-of-visual-thought reasoning, visual guideline generation, instructional image editing 등 any-to-any 특성에 내재된 고급 기능을 보여줍니다.
이 연구는 speech, text, images, videos를 end-to-end, autoregressive 방식으로 이해하고 생성할 수 있는 새로운 foundation 모델인 MIO를 소개합니다. MIO는 네 가지 모달리티에 걸친 이산 토큰의 혼합물에 대해 causal multimodal modeling을 사용하여 훈련됩니다. 이 모델은 4단계 훈련 과정을 거치며, 실험 결과 이전의 dual-modal 베이스라인, any-to-any 모델 베이스라인, 심지어 모달리티 특정 베이스라인과 비교해서 경쟁력 있는, 때로는 우수한 성능을 보여줍니다. 또한, MIO는 interleaved video-text generation, chain-of-visual-thought reasoning, visual guideline generation, instructional image editing 등 any-to-any 특성에 내재된 고급 기능을 보여줍니다.
MM1.5: Methods, Analysis & Insights from Multimodal LLM Fine-tuning
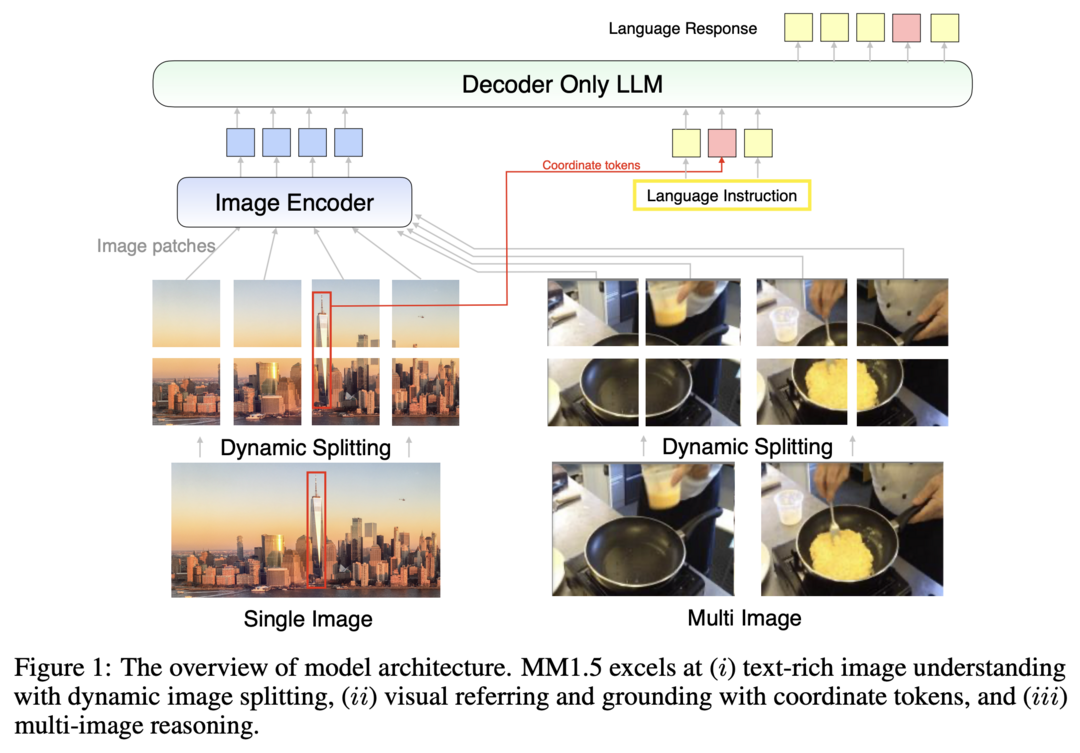
이 연구는 텍스트가 풍부한 이미지 이해, visual referring 및 grounding, 다중 이미지 추론 능력을 향상시키기 위해 설계된 새로운 멀티모달 large language model (MLLM) 가족인 MM1.5를 소개합니다. MM1 아키텍처를 기반으로 한 MM1.5는 모델 훈련의 전체 생명주기에 걸쳐 다양한 데이터 혼합물의 영향을 체계적으로 탐구하는 데이터 중심 접근 방식을 채택합니다. 이 모델은 1B에서 30B 매개변수 범위의 dense 및 mixture-of-experts (MoE) 변형을 포함하며, 신중한 데이터 큐레이션과 훈련 전략이 작은 규모(1B 및 3B)에서도 강력한 성능을 낼 수 있음을 보여줍니다. 또한, 비디오 이해를 위한 MM1.5-Video와 모바일 UI 이해를 위한 MM1.5-UI라는 두 가지 특수 변형을 소개합니다.
Law of the Weakest Link: Cross Capabilities of Large Language Models
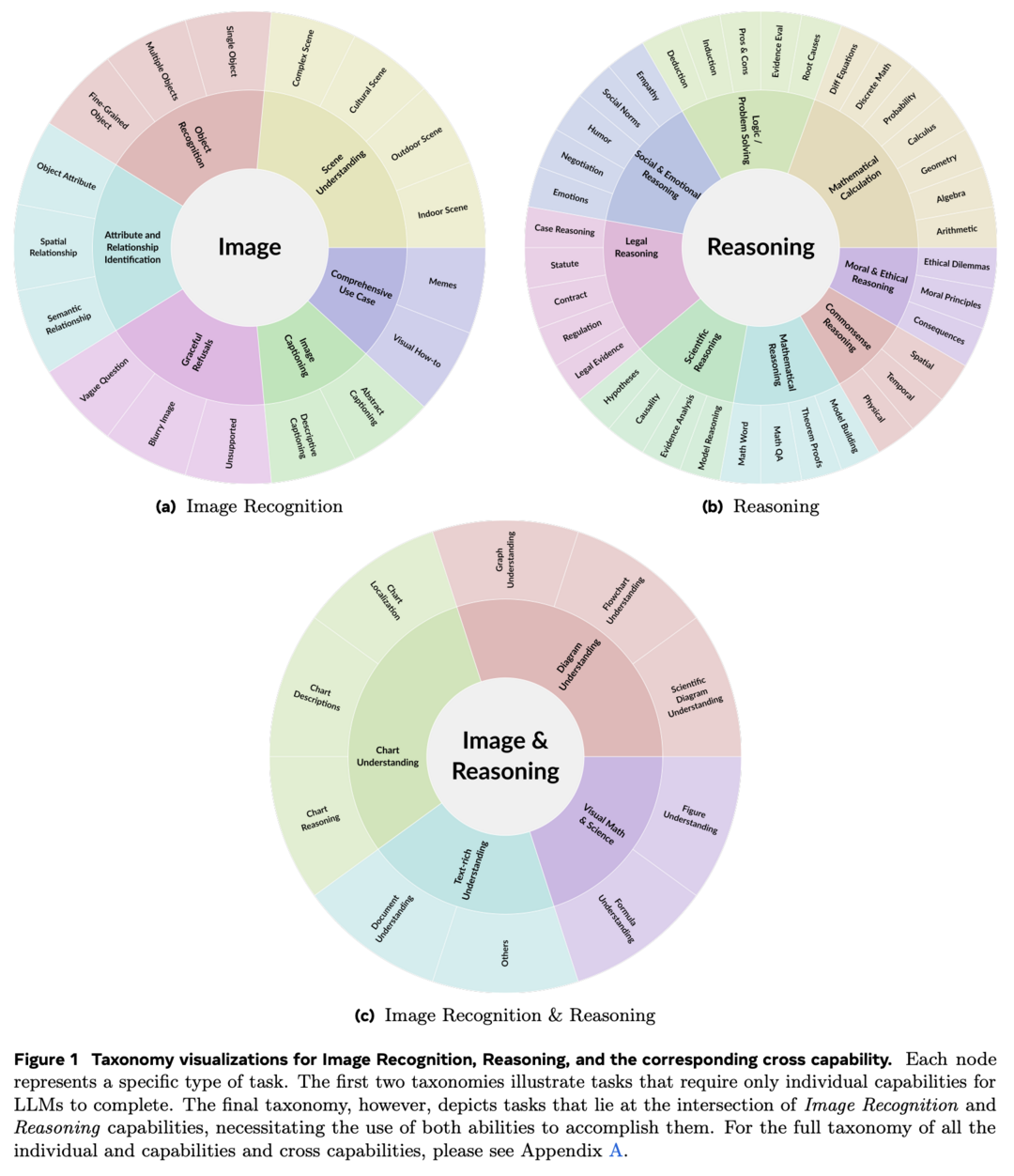
이 연구는 Large Language Models (LLMs)의 cross capabilities, 즉 실제 작업에 필요한 여러 능력의 교차점에 대해 체계적으로 탐구합니다. 연구진은 7개의 핵심 개별 능력을 정의하고 이를 쌍으로 결합하여 7개의 일반적인 cross capabilities를 형성했습니다. 이를 바탕으로 CrossEval이라는 벤치마크를 도입하여 1,400개의 인간 주석 프롬프트를 포함하고 있습니다. 평가 결과, 현재 LLMs는 일관되게 "약한 고리의 법칙"을 보여주며, cross-capability 성능이 가장 약한 구성 요소에 의해 크게 제한됨을 밝혔습니다. 이 결과는 LLMs의 cross-capability 작업에서의 성능 저하를 강조하며, 복잡한 다차원 시나리오에서 성능을 최적화하기 위해 가장 약한 능력의 식별과 개선이 중요한 우선순위임을 시사합니다.
Revisit Large-Scale Image-Caption Data in Pre-training Multimodal Foundation Models
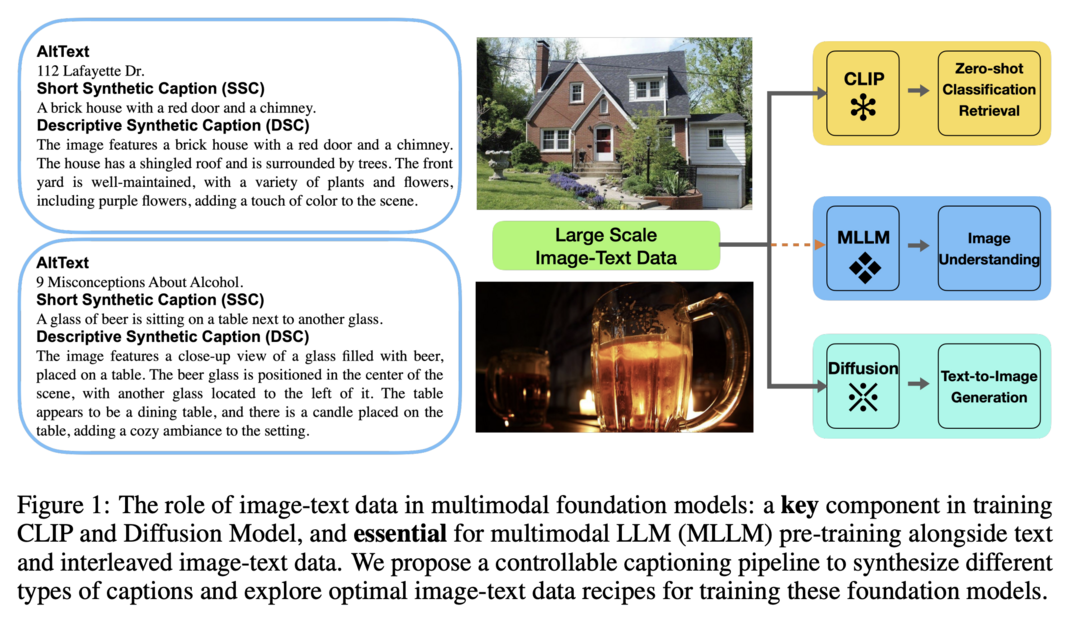
이 연구는 멀티모달 foundation 모델의 사전 훈련에 있어 대규모 이미지-캡션 데이터의 역할을 재검토합니다. 연구진은 다양한 멀티모달 모델에 맞춤화된 캡션 형식을 생성하기 위한 새롭고 제어 가능하며 확장 가능한 캡션 생성 파이프라인을 제안합니다. Short Synthetic Captions (SSC)에서 Dense Synthetic Captions (DSC+)까지를 사례 연구로 삼아, CLIP, 멀티모달 LLMs, diffusion 모델과 같은 다양한 모델에 걸쳐 이들의 효과와 AltTexts와의 상호작용을 체계적으로 탐구했습니다. 연구 결과, 합성 캡션과 AltTexts를 모두 유지하는 하이브리드 접근 방식이 합성 캡션만 사용하는 것보다 더 나은 성능을 보일 수 있으며, alignment와 성능을 모두 향상시킬 수 있음을 발견했습니다. 또한, 각 모델이 특정 캡션 형식에 대한 선호도를 보인다는 점도 밝혀냈습니다.
[저작권자ⓒ META-X. 무단전재-재배포 금지]