2024년 W41/W42에 공개된 주목할만한 인공지능(AI) 분야의 논문들을 소개합니다. 1) 효율적인 모델 학습, 2) 모델 구조 및 성능 개선, 3) 멀티모달 모델 및 벤치마크, 4) LLM 응용 및 분석, 5) 콘텐츠 생성 분야에서의 다양한 논문들이 발표되었습니다.
각 논문별 간단한 요약을 원하시는 분들은 아래의 TL;DR을 참고해주세요.
TL;DR
효율적인 모델 학습을 위해 'Addition is All You Need' 방법론이 제시되어 부동 소수점 곱셈을 정수 덧셈으로 대체함으로써 에너지 효율을 높이고 있습니다.
모델 구조 개선 면에서는 Differential Transformer가 노이즈 감소와 컨텍스트 집중도 향상을, MathCoder2가 수학적 추론 능력 강화를 이루어냈습니다.
멀티모달 분야에서는 Aria, Pixtral-12B, Baichuan-Omni 등의 모델이 등장하여 이미지, 비디오, 오디오, 텍스트를 통합적으로 처리하는 능력을 보여주고 있습니다. 이와 함께 LOKI, MMIE, MixEval-X 같은 새로운 벤치마크들이 개발되어 이러한 모델들의 성능을 다각도로 평가할 수 있게 되었습니다.
LLM의 응용 및 분석 측면에서는 오류 감지 기술, GLEE 프레임워크를 통한 경제적 상호작용 평가, WALL-E의 규칙 학습 기반 접근법, PVIT의 개인화된 시각적 지시 조정, MoEE의 임베딩 모델 활용, VidEgoThink의 에고센트릭 비디오 이해 능력 평가 등 다양한 연구가 진행되고 있습니다.
콘텐츠 생성 영역에서는 Meissonic이 고해상도 텍스트-이미지 합성을, Animate-X가 범용 캐릭터 애니메이션을, Movie Gen이 고품질 비디오 및 오디오 생성을, VIF-RAG가 검색 기반 생성 시스템의 명령어 따르기 정렬을 위한 솔루션을 제시하고 있습니다.
Addition is All You Need for Energy-efficient Language Models
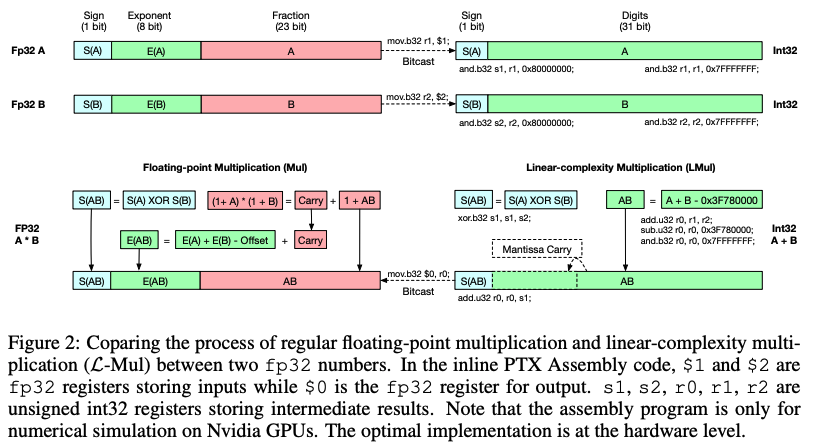
이 논문은 대규모 신경망의 에너지 효율성을 높이기 위한 혁신적인 접근 방식을 제시합니다. 부동 소수점 곱셈을 정수 덧셈으로 근사하는 L-Mul 알고리즘을 개발했습니다. 이 방법은 8-bit 부동 소수점 곱셈보다 적은 계산 리소스로 더 높은 정밀도를 달성합니다. 텐서 처리 하드웨어에 적용 시 요소별 부동 소수점 텐서 곱셈의 에너지 비용을 95%, 도트 곱의 에너지 비용을 80%까지 줄일 수 있습니다. 다양한 작업에서 알고리즘을 평가했으며, Transformer 모델에서 모든 부동 소수점 곱셈을 3-bit mantissa L-Mul로 대체해도 float8_e4m3과 동등한 정밀도를 달성함을 보여줍니다. 이 연구는 에너지 효율적인 AI 모델 개발에 중요한 기여를 할 것으로 보입니다.
Differential Transformer
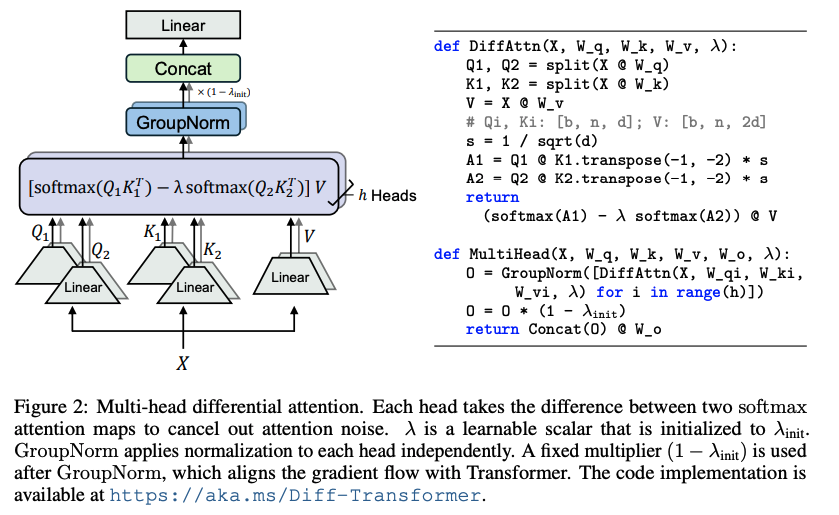
이 연구는 Transformer 모델의 주요 단점인 관련 없는 문맥에 과도한 attention을 할당하는 문제를 해결하기 위해 Diff Transformer를 제안합니다. 두 개의 별도 softmax attention 맵 간의 차이로 attention 점수를 계산하여 노이즈를 제거하고 sparse attention 패턴을 촉진합니다. 다양한 설정에서 기존 Transformer보다 우수한 성능을 보이며, 특히 long-context 모델링, hallucination 완화, in-context learning 등에서 주목할 만한 이점을 제공합니다. 또한, 질문 답변 및 텍스트 요약에서 hallucination을 줄이고, in-context learning에서 order permutation에 대한 robustness를 향상시킵니다. 이 모델은 대규모 언어 모델을 발전시키기 위한 매우 효과적이고 유망한 아키텍처로 평가됩니다.
LLMs Know More Than They Show
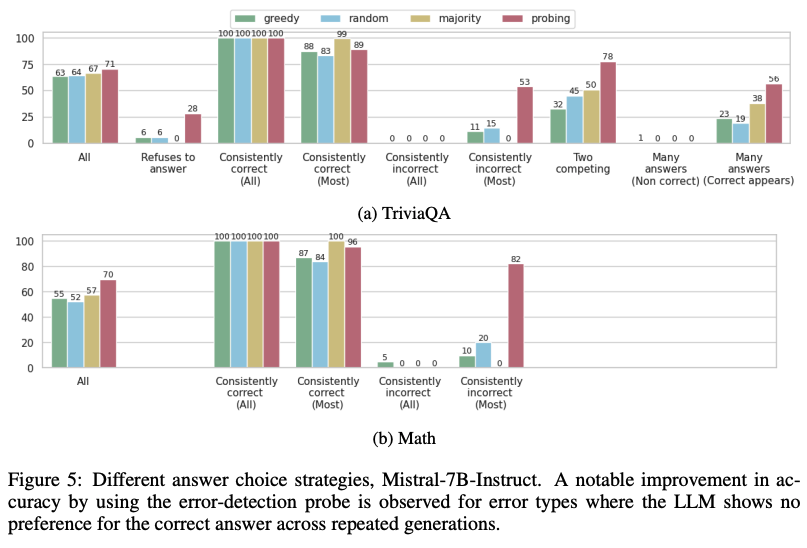
이 연구는 LLM의 내부 표현이 출력의 진실성에 대한 풍부한 정보를 인코딩한다는 것을 밝힙니다. 특정 토큰에 진실성 정보가 집중되어 있음을 발견했고, 이를 활용하여 오류 감지 성능을 크게 향상시켰습니다. 내부 표현을 사용해 발생 가능한 오류 유형을 예측할 수 있으며, 이는 맞춤형 오류 완화 전략 개발에 도움이 될 수 있습니다. 또한, LLM의 내부 인코딩과 외부 동작 간의 불일치를 밝혔는데, 이는 모델이 정답을 인코딩하고 있음에도 불구하고 지속적으로 잘못된 답변을 생성할 수 있음을 의미합니다. 이러한 통찰은 LLM 오류에 대한 이해를 깊게 하고, 향후 오류 분석 및 완화 연구에 중요한 지침을 제공할 것으로 기대됩니다.
Aria: An Open Multimodal Native Mixture-of-Experts Model
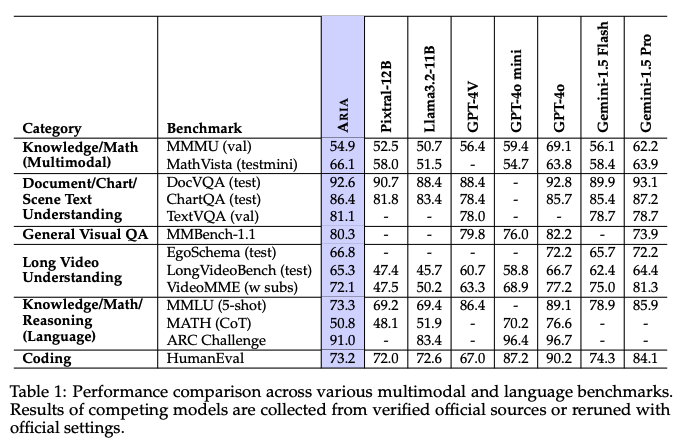
Aria는 광범위한 multimodal, 언어 및 코딩 작업에서 최고 수준의 성능을 제공하는 개방형 multimodal native 모델입니다. Mixture-of-Experts 아키텍처를 사용하며, 시각적 토큰과 텍스트 토큰당 각각 3.9B 및 3.5B 활성화 매개변수를 가집니다. Pixtral-12B 및 Llama3.2-11B보다 우수한 성능을 보이며, 최고의 독점 모델들과 경쟁력 있는 성능을 보여줍니다. 언어 이해, multimodal 이해, 긴 context window 및 instruction following 능력을 단계적으로 갖추는 4단계 파이프라인을 통해 처음부터 사전 학습되었습니다. 모델 가중치와 코드베이스를 오픈 소스로 공개하여 실제 애플리케이션에서의 쉬운 채택과 적응을 촉진합니다.
GLEE: A Unified Framework and Benchmark for Language-based Economic Environments
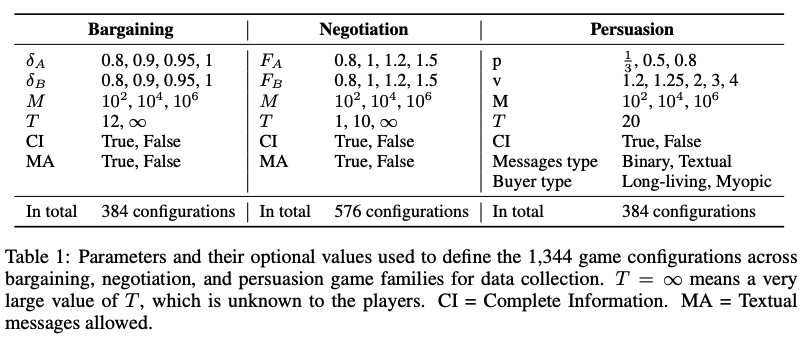
GLEE는 2인용 순차적 언어 기반 게임에 대한 연구를 표준화하기 위한 벤치마크입니다. 경제 문헌에서 영감을 받아 에이전트의 성과(자기 이익)와 게임 결과(효율성 및 공정성)를 평가하기 위해 일관된 매개변수화, 자유도 및 경제적 측정을 사용하여 세 가지 기본 게임군을 정의합니다. 상호 작용 시뮬레이션 및 분석을 위한 오픈 소스 프레임워크를 개발했으며, 이를 통해 LLM 대 LLM 상호 작용 데이터 세트와 인간 대 LLM 상호 작용 데이터 세트를 수집했습니다. 이 벤치마크를 통해 LLM 기반 에이전트의 행동을 인간 플레이어와 비교하고, 개별 및 집단 성과를 평가하며, 환경의 경제적 특성이 에이전트 행동에 미치는 영향을 정량화할 수 있습니다. 이는 LLM의 경제적, 전략적 상호 작용 능력을 평가하는 데 중요한 도구가 될 것으로 기대됩니다.
Personalized Visual Instruction Tuning (PVIT)

MLLM(Multimodal Large Language Models)이 이미지 내 대상 개인을 식별하고 개인화된 대화를 할 수 있도록 하는 새로운 데이터 큐레이션 및 학습 프레임워크입니다. 다양한 시각 전문가, 이미지 생성 모델, 대규모 언어 모델을 활용하여 개인화된 대화 데이터를 자동으로 생성합니다. P-Bench라는 평가 벤치마크도 제시하여 MLLM의 개인화된 잠재력을 평가합니다. 실험 결과, 큐레이션된 데이터 세트로 fine-tuning한 후 개인화된 성능이 크게 향상되었음을 보여줍니다. 이 연구는 모바일 장치의 맞춤형 시각 보조나 가족 구성원을 인식해야 하는 가정용 로봇과 같은 개인화된 AI 애플리케이션 개발에 중요한 기여를 할 것으로 보입니다.
Pixtral 12B
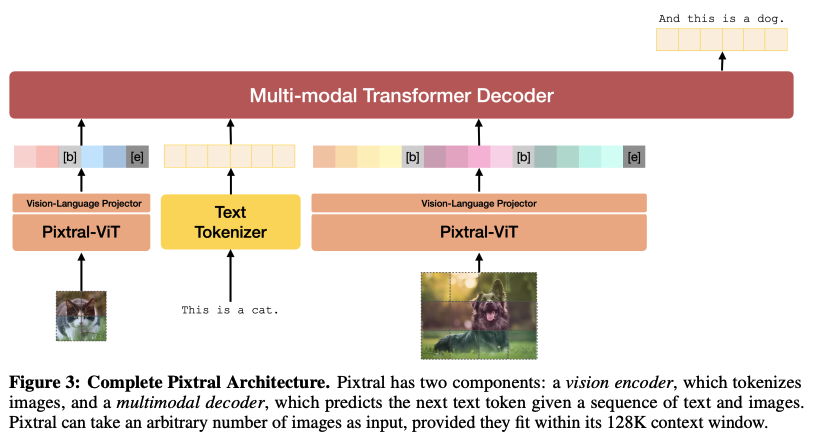
Pixtral 12B는 120억 매개변수를 가진 multimodal 언어 모델로, 자연 이미지와 문서를 모두 이해하도록 학습되었습니다. 다양한 multimodal 벤치마크에서 더 큰 모델들을 능가하는 성능을 보이며, 텍스트 모델로서도 뛰어난 성능을 유지합니다. 새롭게 개발된 비전 인코더를 사용하여 자연 해상도와 종횡비로 이미지를 처리할 수 있으며, 사용자에게 이미지 처리에 사용되는 토큰 수에 대한 유연성을 제공합니다. 128K 토큰의 긴 context window에서 여러 이미지를 처리할 수 있는 능력도 갖추고 있습니다. Llama-3.2 90B와 같은 훨씬 더 큰 모델보다 우수한 성능을 보이면서도 크기는 7배 더 작습니다. Apache 2.0 라이선스로 공개되어 연구 및 실용적 응용이 가능합니다.
WALL-E: World Alignment by Rule Learning Improves World Model-based LLM Agents
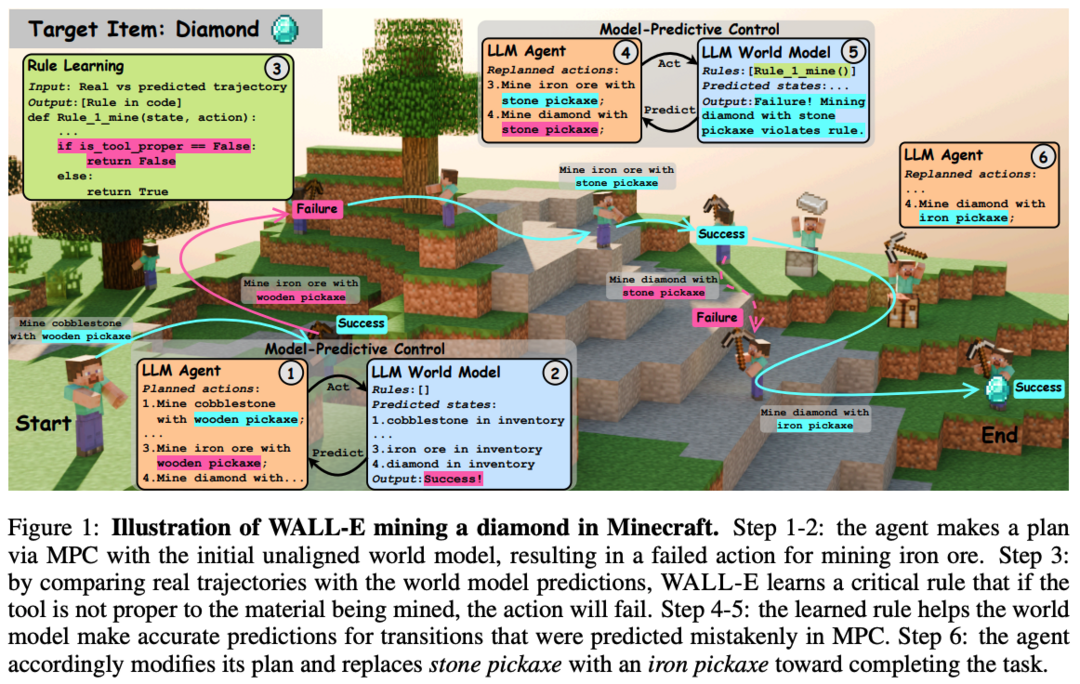
WALL-E는 LLM을 배포된 환경에 맞추는 "world alignment"를 규칙 학습을 통해 효율적으로 달성하는 방법을 제안합니다. 에이전트 탐색 궤적과 world model 예측을 비교하여 LLM을 통해 규칙을 학습하는 neurosymbolic 접근 방식을 사용합니다. 이 방법은 LLM의 풍부한 사전 지식을 활용하면서도 특정 환경의 역학에 맞춰 조정할 수 있게 합니다. Minecraft와 ALFWorld와 같은 open-world 과제에서 WALL-E는 기존 방법보다 높은 성공률을 달성하면서도 재계획 시간과 추론에 사용된 토큰 수를 크게 줄였습니다. 이 연구는 LLM을 Embodied AI 애플리케이션에 효과적으로 적용하는 데 중요한 진전을 보여줍니다.
MathCoder2: Better Math Reasoning from Continued Pretraining on Model-translated Mathematical Code
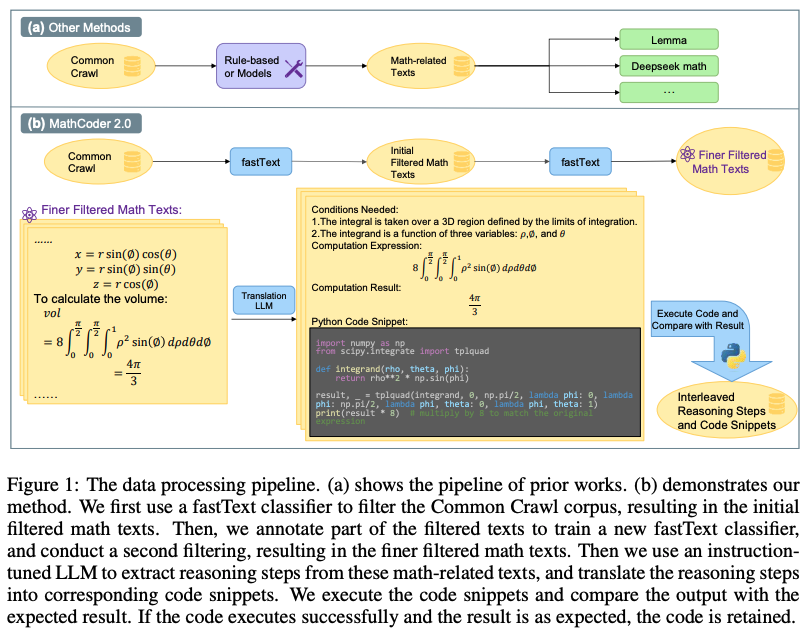
MathCoder2는 LLM의 수학적 추론 능력을 향상시키기 위해 수학적 코드와 추론 단계를 생성하는 새로운 방법을 소개합니다. 수학 관련 웹 데이터, 수학 패키지를 사용하는 코드, 수학 교과서, 합성 데이터 등 다양한 소스에서 수집한 데이터를 바탕으로 MathCode-Pile이라는 고성능 수학 사전 학습 코퍼스를 생성합니다. 이 코퍼스는 19.2B 토큰으로 구성되어 있으며, 이를 통해 학습된 MathCoder2 모델 제품군은 수학적 능력이 크게 향상되었습니다. 모든 데이터 처리 및 학습 코드가 오픈 소스로 공개되어 완전한 투명성과 재현성을 보장합니다. 이 연구는 LLM의 수학적 추론 능력 향상에 중요한 기여를 할 것으로 기대됩니다.
Baichuan-Omni
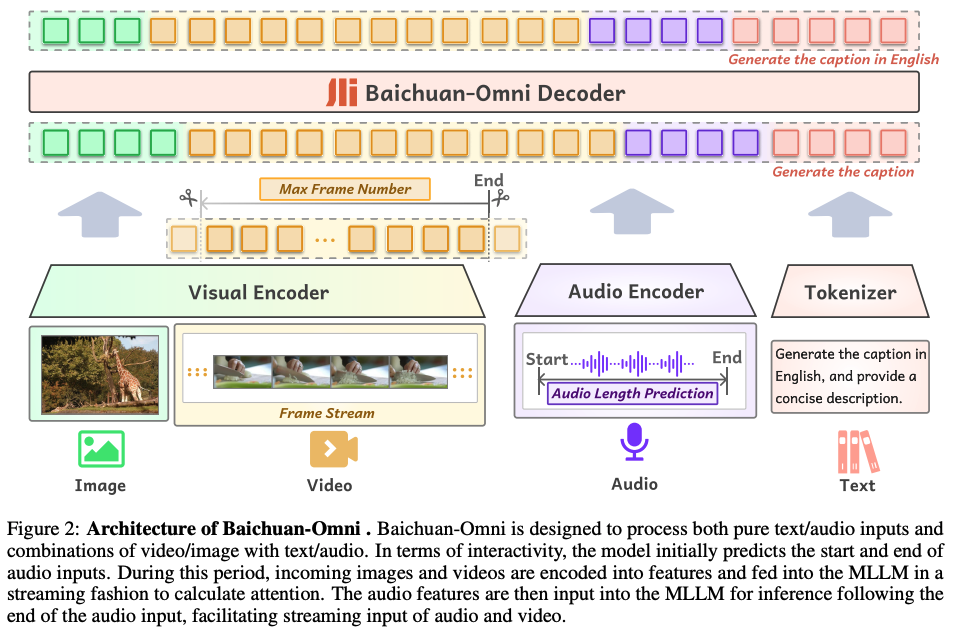
Baichuan-Omni는 이미지, 비디오, 오디오, 텍스트를 동시에 처리하고 분석할 수 있는 최초의 오픈 소스 7B Multimodal Large Language Model입니다. 오디오, 이미지, 비디오, 텍스트 모달에 걸친 multimodal 정렬 및 멀티태스킹 fine-tuning을 통해 학습되었습니다. 7B 모델로 시작하여 두 단계의 학습 과정을 거쳤으며, 다양한 omni-modal 및 multimodal 벤치마크에서 강력한 성능을 보입니다. 고급 multimodal 대화형 경험과 강력한 성능을 제공하며, 텍스트-비디오 합성, 비디오 개인화, 비디오 편집, 비디오-오디오 생성, 텍스트-오디오 생성 등 여러 작업에서 뛰어난 능력을 보여줍니다. 이 연구는 오픈 소스 커뮤니티에서 multimodal 이해 및 실시간 상호 작용을 발전시키는 데 중요한 기여를 할 것으로 기대됩니다.
Meissonic: Revitalizing Masked Generative Transformers for Efficient High-Resolution Text-to-Image Synthesis
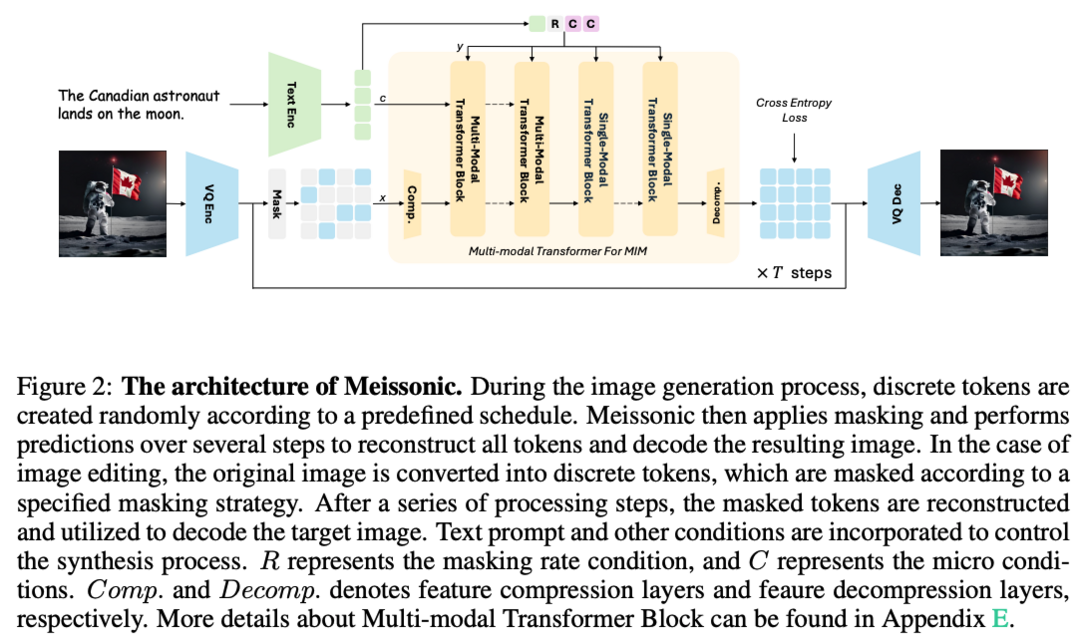
Meissonic은 비자기 회귀 마스크 이미지 모델링(MIM) 기반의 텍스트-이미지 변환 모델을 제안합니다. 포괄적인 아키텍처 혁신, 고급 위치 인코딩 전략, 최적화된 샘플링 조건을 통합하여 MIM의 성능과 효율성을 크게 향상시켰습니다. 또한 고품질 학습 데이터 활용, 인간 선호도 점수 기반 마이크로 조건 통합, 기능 압축 레이어 사용 등을 통해 이미지 충실도와 해상도를 더욱 향상시켰습니다. 고품질, 고해상도 이미지 생성에서 SDXL과 같은 최신 확산 모델과 비슷하거나 더 나은 성능을 보입니다. 1024x1024 해상도 이미지를 생성할 수 있는 모델 체크포인트를 공개하여 연구 커뮤니티에 기여합니다.
LOKI: A Comprehensive Synthetic Data Detection Benchmark using Large Multimodal Models

LOKI는 LMM(Large Multimodal Models)의 합성 데이터 감지 능력을 평가하기 위한 새로운 벤치마크입니다. 비디오, 이미지, 3D, 텍스트, 오디오 모달리티를 포함하며, 26개 하위 범주에 걸쳐 18,000개의 신중하게 선별된 질문으로 구성되어 있습니다. 거친 판단, 객관식 질문, 세분화된 이상 징후 선택, 설명 작업 등 다양한 평가 방식을 포함합니다. 22개의 오픈 소스 LMM과 6개의 클로즈드 소스 모델을 평가하여 합성 데이터 감지기로서의 잠재력과 제한점을 분석했습니다. 이 연구는 AI 생성 콘텐츠의 급속한 발전에 따른 합성 데이터 감지의 중요성을 강조하며, LMM의 능력과 한계를 포괄적으로 평가하는 데 기여합니다.
MMIE: Massive Multimodal Interleaved Comprehension Benchmark for Large Vision-Language Models

MMIE는 LLM(Large Vision-Language Models)의 interleaved multimodal 이해 및 생성을 평가하기 위한 대규모 지식 집약적 벤치마크입니다. 수학, 코딩, 물리학, 문학, 건강, 예술 등 3개 범주, 12개 분야, 102개 하위 분야에 걸쳐 20,000개의 multimodal 쿼리로 구성되어 있습니다. interleaved 입력과 출력을 모두 지원하며, 다양한 역량을 평가하기 위해 객관식 및 서술형 질문 형식이 혼합되어 있습니다. 인간 주석 데이터 및 체계적인 평가 기준으로 fine-tuning된 점수 모델을 활용하여 안정적인 자동 평가 지표를 제안합니다. 8개의 LVLMs를 평가한 결과, 최고의 모델조차 개선의 여지가 크며 대부분은 보통 수준의 결과만을 얻었음을 보여줍니다. 이 연구는 interleaved LVLMs의 현재 능력을 포괄적으로 평가하고 향후 발전 방향을 제시하는 데 중요한 역할을 할 것으로 기대됩니다.
Animate-X: Universal Character Image Animation with Enhanced Motion Representation
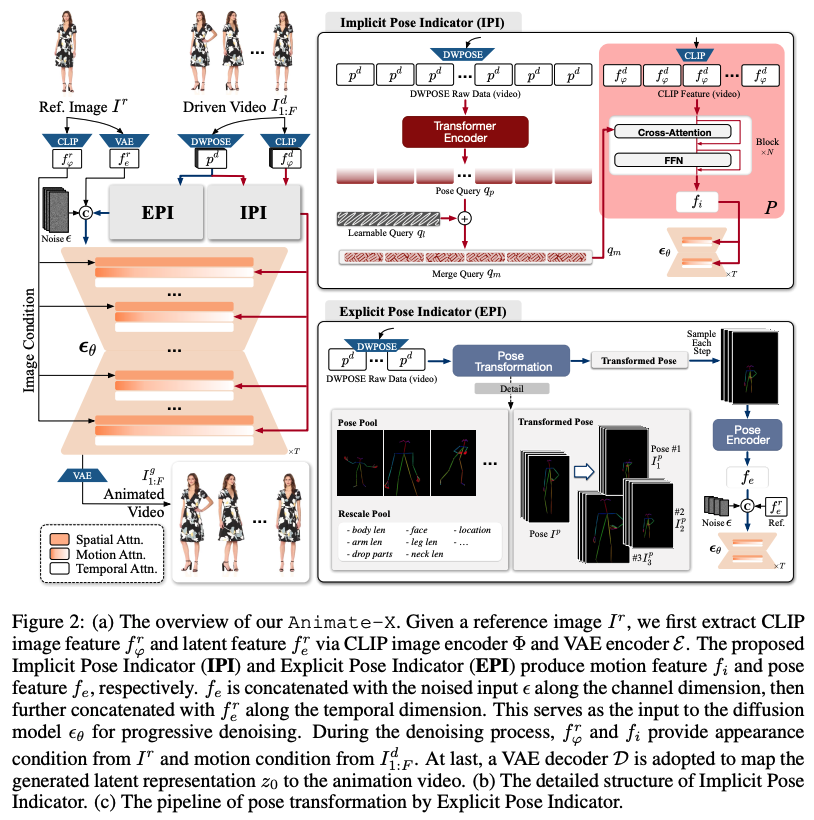
Animate-X는 다양한 캐릭터 유형(의인화된 캐릭터 포함)에 대한 범용 애니메이션 프레임워크입니다. 동작 표현을 향상시키기 위해 암시적 및 명시적 방식을 통해 드라이빙 비디오에서 포괄적인 동작 패턴을 캡처하는 포즈 표시기를 소개합니다. CLIP 시각적 특징을 활용하여 전체적인 움직임 패턴 및 동작 간의 시간적 관계를 추출하고, 추론 중에 발생할 수 있는 가능한 입력을 미리 시뮬레이션하여 LDM의 일반화를 강화합니다. 또한 새로운 Animated Anthropomorphic Benchmark(A^2Bench)를 소개하여 Animate-X의 성능을 평가합니다. 이 연구는 게임 및 엔터테인먼트 산업에서 널리 사용되는 의인화된 캐릭터를 포함한 다양한 캐릭터 애니메이션 기술의 발전에 기여할 것으로 보입니다.
VIF-RAG
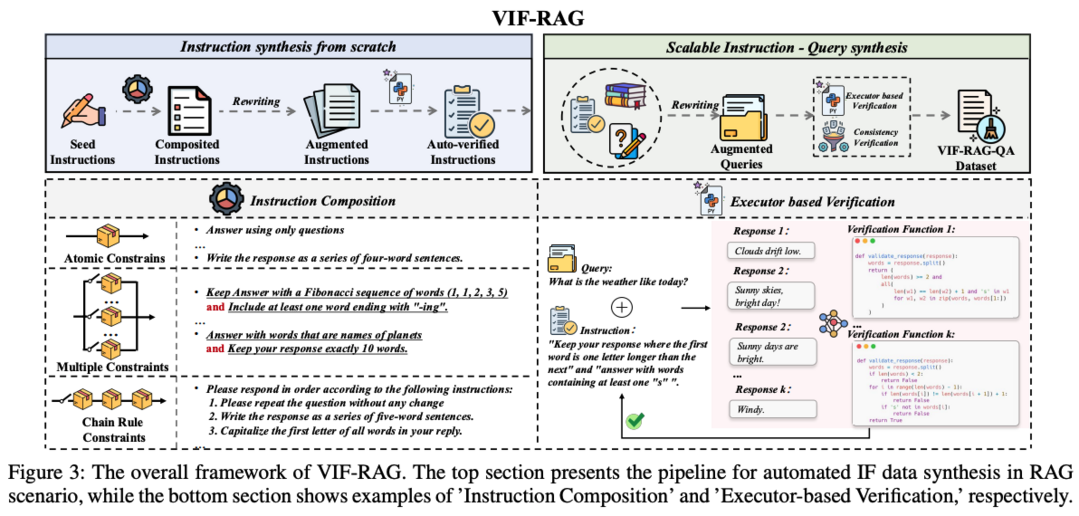
VIF-RAG는 RAG(Retrieval-Augmented Generation) 시스템에서 지침 준수 정렬을 위한 자동화된 합성 파이프라인입니다. 최소한의 원자적 지침 집합(<100)을 수동으로 작성하고 조합 규칙을 개발하여 복잡한 지침을 합성합니다. 지침 재작성을 위해 감독 모델을 사용하고 Python 실행기를 통해 지침 품질 검증을 자동화합니다. 이를 통해 고품질 VIF-RAG-QA 데이터 세트(>100k)를 생성합니다. 또한 FollowRAG 벤치마크를 소개하여 RAG 시스템의 지침 준수 능력을 평가합니다. 이 연구는 RAG 시스템에서의 지침 준수 정렬을 개선하고 평가하는 데 중요한 도구를 제공합니다.
Your Mixture-of-Experts LLM Is Secretly an Embedding Model For Free
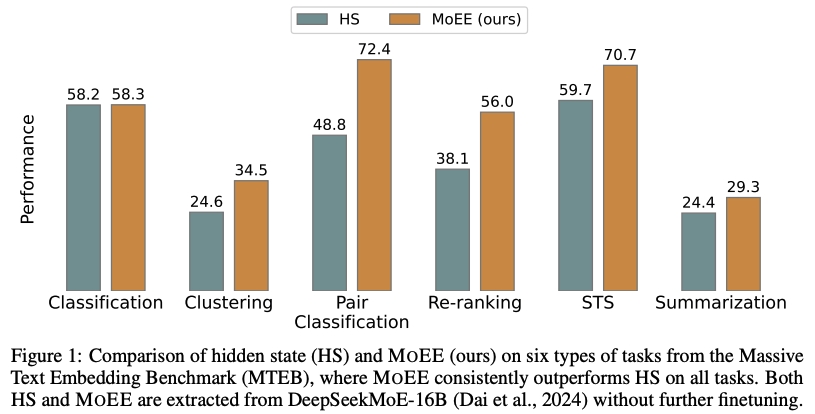
이 연구는 Mixture-of-Experts(MoE) LLM의 전문 라우터가 fine-tuning 없이도 효과적인 임베딩 모델 역할을 할 수 있음을 보여줍니다. MoE 라우팅 가중치(RW)와 LLM의 숨겨진 상태(HS)를 분석한 결과, RW가 HS를 보완하며 프롬프트 선택에 더 강력하고 고급 의미에 중점을 둔다는 것을 발견했습니다. 이를 바탕으로 RW와 HS를 결합한 MoEE를 제안하여 임베딩 성능을 향상시켰습니다. Massive Text Embedding Benchmark(MTEB)의 20개 데이터 세트를 사용한 실험에서 MoEE의 효과성을 입증했으며, 추가 fine-tuning 없이도 LLM 기반 임베딩의 성능을 크게 개선할 수 있음을 보여줍니다. 이 연구는 MoE LLM의 숨겨진 잠재력을 활용하여 효율적인 임베딩 모델을 얻는 새로운 방법을 제시합니다.
VidEgoThink: Assessing Egocentric Video Understanding Capabilities for Embodied AI
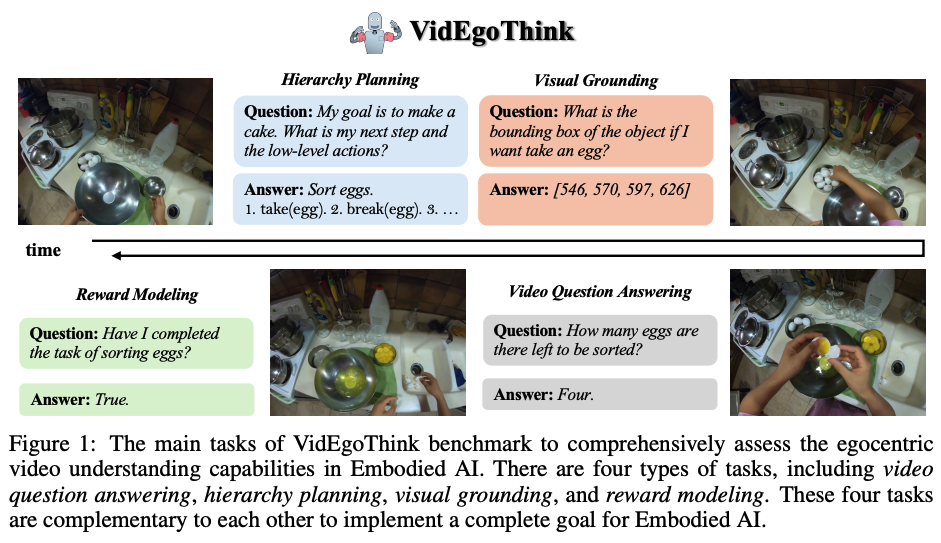
VidEgoThink는 Embodied AI를 위한 egocentric 비디오 이해 능력을 평가하는 포괄적인 벤치마크입니다. 비디오 질문 답변, 계층 계획, 시각적 기반 및 보상 모델링 등 네 가지 주요 작업을 포함합니다. GPT-4o를 활용한 자동 데이터 생성 파이프라인을 개발하여 Ego4D 데이터 세트를 기반으로 데이터를 생성하고, 인간 주석자를 통해 필터링하여 다양성과 품질을 보장합니다. API 기반 MLLM, 오픈 소스 이미지 기반 MLLM, 오픈 소스 비디오 기반 MLLM 등 다양한 유형의 모델을 평가했습니다. 실험 결과, GPT-4o를 포함한 모든 MLLM이 egocentric 비디오 이해 작업에서 성능이 저조함을 보여주어, Embodied AI의 1인칭 시나리오에 효과적으로 적용되기 위해서는 여전히 상당한 발전이 필요함을 시사합니다.
MixEval-X: Any-to-Any Evaluations from Real-World Data Mixtures

MixEval-X는 다양한 모달리티 간의 입력 및 출력을 평가하도록 설계된 모든 대 모든 실제 벤치마크입니다. 실제 작업 분포를 재구성하기 위해 멀티 모달 벤치마크 혼합 및 적응-수정 파이프라인을 제안했습니다. 광범위한 메타 평가를 통해 이 접근 방식이 벤치마크 샘플을 실제 작업 분포와 효과적으로 정렬하고, 모델 순위가 크라우드 소싱된 실제 평가와 강한 상관관계(최대 0.98)를 보이는 것을 확인했습니다. 기존 모델 및 조직의 순위를 다시 매기는 포괄적인 순위표를 제공하고, 멀티 모달 평가에 대한 이해를 높이기 위한 통찰력을 제공합니다. 이 연구는 실제 세계의 복잡한 멀티 모달 작업에 대한 AI 모델의 성능을 더 정확하게 평가하는 데 기여할 것으로 기대됩니다.
Movie Gen: A Cast of Media Foundation Models

Movie Gen은 다양한 종횡비와 동기화된 오디오로 1080p HD 비디오를 생성하는 기초 모델 모음입니다. 텍스트-비디오 합성, 비디오 개인화, 비디오 편집, 비디오-오디오 생성, 텍스트-오디오 생성 등 여러 작업에서 새로운 최첨단 기술을 제시합니다. 가장 큰 비디오 생성 모델은 300억 매개변수의 변환기로, 최대 73,000개의 비디오 토큰의 context length로 학습되었습니다. 사용자 이미지 기반 개인화 및 명령 기반 비디오 편집 기능도 제공합니다. 아키텍처, 잠재 공간, 훈련 목표, 데이터 큐레이션, 평가 프로토콜 등에 대한 여러 기술적 혁신을 통해 대규모 미디어 생성 모델의 성능을 향상시켰습니다. 이 연구는 고품질 비디오 생성 및 편집 분야에서 중요한 진전을 보여줍니다.
[저작권자ⓒ META-X. 무단전재-재배포 금지]