2024년 W43/W44에 공개된 주목할만한 인공지능(AI) 분야의 논문들을 소개합니다. 각 논문별 간단한 요약을 원하시는 분들은 아래의 TL;DR을 참고해주세요.
TL;DR
Hugging Face의 AutoTrain과 메모리 최적화 연구를 통해 AI 모델 개발의 진입 장벽이 낮아졌으며, GPT-4o는 텍스트/오디오/이미지/비디오를 통합 처리하는 새로운 멀티모달 AI의 지평을 열었습니다.
AI 모델의 신뢰성과 평가를 위해 HalluEditBench(환각 현상 교정), CompassJudger-1(모델 평가), CLEAR(machine unlearning), UCFE(금융 분야 특화) 등 다양한 벤치마크가 개발되었습니다.
컴퓨터 비전 분야에서는 SDXL Turbo의 내부 구조 분석, PUMA의 통합 MLLM 프레임워크, SAM2Long의 비디오 처리 개선, FrugalNeRF의 3D 재구성 최적화 등 실용적인 혁신이 이루어졌습니다.
AutoTrain: No-code training for state-of-the-art models
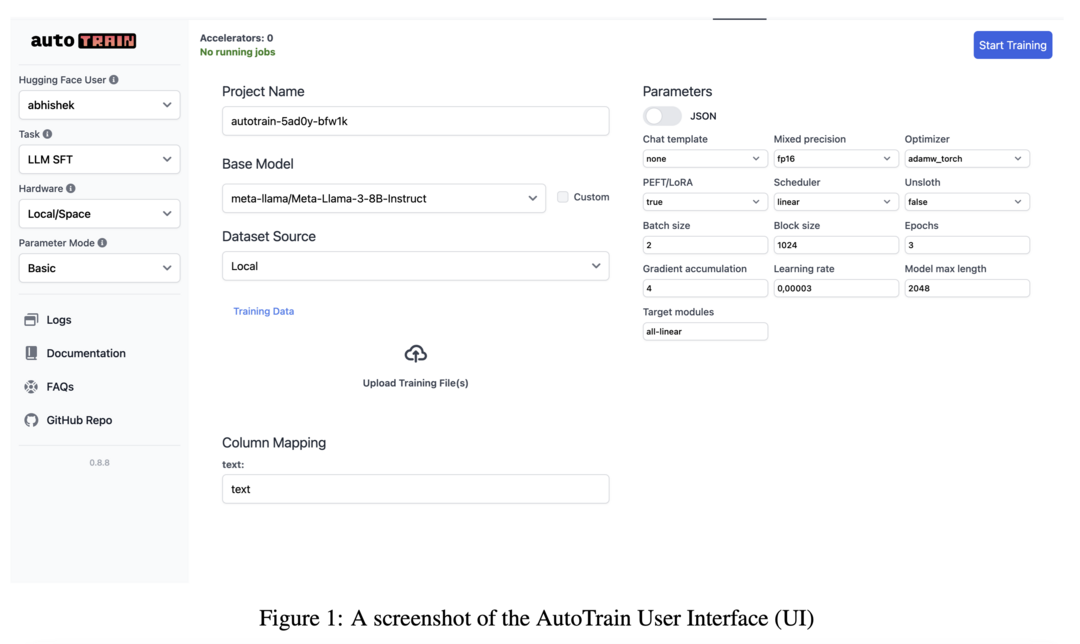
Hugging Face에서 공개한 혁신적인 no-code 기반의 통합 모델 학습/미세조정 도구입니다. LLM, VLM, 텍스트 분류, 토큰 분류, sequence-to-sequence 태스크, sentence transformer 미세조정, 이미지 분류/회귀, 테이블 데이터 분석 등 광범위한 태스크를 지원합니다. 로컬 환경과 클라우드 환경 모두에서 사용 가능하며, Hugging Face Hub의 수만 개 모델과 완벽하게 호환됩니다. 복잡한 코딩 없이도 산업용 또는 오픈소스 애플리케이션을 위한 최적화된 학습을 수행할 수 있어, AI 모델 개발의 진입 장벽을 크게 낮추었습니다.
Breaking the Memory Barrier: Near Infinite Batch Size Scaling for Contrastive Loss
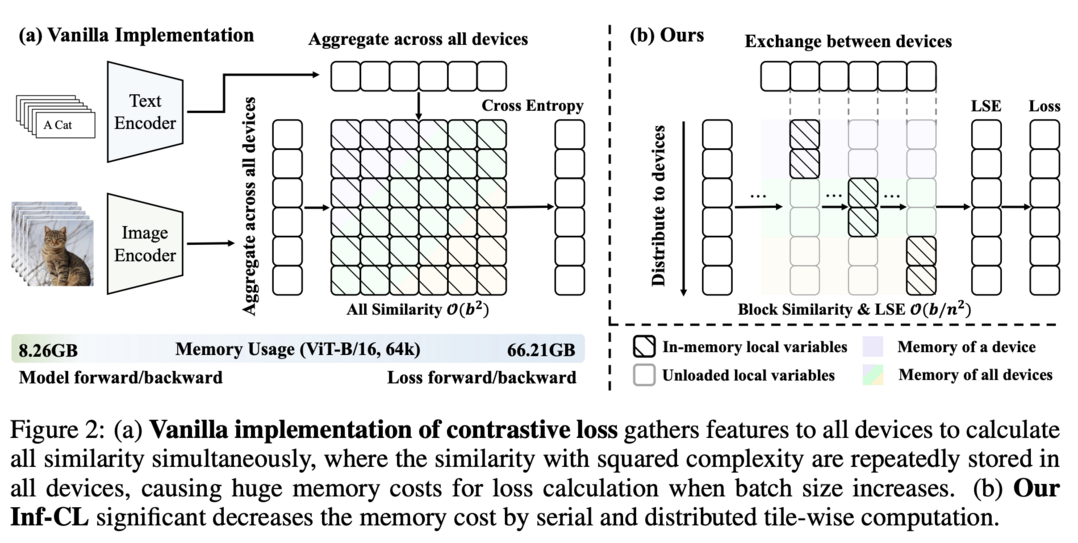
Contrastive learning에서 GPU 메모리 한계를 극복하는 혁신적인 타일 기반 계산 전략을 제시합니다. 기존 방식에서는 유사도 행렬의 완전한 구성이 필요해 GPU 메모리 사용량이 배치 크기에 따라 이차함수적으로 증가했지만, 제안된 방법은 이를 작은 블록으로 나누어 계산합니다. 또한 분산 시스템의 계층 구조를 활용하는 다중 레벨 타일링 전략을 도입하여, GPU 레벨에서는 ring 기반 통신을, CUDA 코어 레벨에서는 fused kernel을 사용해 동기화와 I/O 오버헤드를 최적화했습니다. 그 결과 CLIP-ViT-L/14 모델을 8개의 A800 GPU로 4M 배치 크기까지, 32개 GPU로는 12M 배치 크기까지 학습할 수 있게 되었으며, 기존 메모리 효율화 솔루션 대비 100배 이상의 메모리 절감을 달성하면서도 comparable한 속도를 유지합니다.
Can Knowledge Editing Really Correct Hallucinations?

LLM의 환각 현상을 교정하기 위한 knowledge editing 방법의 실효성을 검증하는 종합적인 벤치마크입니다. 기존의 knowledge editing 평가 데이터셋들은 편집 전 LLM이 실제로 환각을 일으키는지 확인하지 않았다는 한계가 있었습니다. 이를 해결하기 위해 9개 도메인, 26개 주제에 걸친 6,000개 이상의 실제 환각 데이터셋을 엄격한 기준으로 구축했습니다. 이를 통해 효과성(편집의 성공률), 일반화(다른 맥락에서의 적용), 이식성(다른 모델로의 전이), 지역성(의도하지 않은 지식 변경 방지), 견고성(적대적 입력에 대한 저항성) 등 5가지 차원에서 다양한 editing 방법들을 포괄적으로 평가합니다.
GPT-4o System Card

텍스트, 오디오, 이미지, 비디오를 end-to-end로 처리하는 진정한 의미의 통합 멀티모달 모델입니다. 모든 입력과 출력이 단일 신경망에서 처리되며, 오디오 입력에 대해 인간의 대화 응답 시간과 유사한 평균 320ms(최소 232ms)의 놀라운 처리 속도를 보여줍니다. GPT-4 Turbo와 동등한 영어/코드 성능을 유지하면서도 비영어 언어에서는 더 우수한 성능을 보이며, 특히 시각 및 오디오 이해 능력이 기존 모델들을 크게 앞섭니다. API 비용도 50% 절감되어 실용성도 높았습니다. 또한 White House와의 자발적 약속에 따라 상세한 System Card를 공개하여 모델의 capabilities, limitations, 안전성 평가 결과를 투명하게 공유했습니다.
CompassJudger-1: All-in-one Judge Model Helps Model Evaluation and Evolution
LLM 평가를 위한 최초의 올인원 judge 모델로, 단일 점수 평가부터 모델 간 비교, 지정된 형식의 평가, 비평 생성까지 다양한 평가 기능을 제공합니다. reward model로서의 역할뿐만 아니라 일반적인 LLM처럼 다양한 태스크도 수행할 수 있는 범용성을 갖추었습니다. 또한 통일된 설정에서 다양한 judge 모델들의 평가 능력을 비교할 수 있는 JudgerBench라는 새로운 벤치마크도 함께 구축했습니다. 이는 다양한 주제를 포괄하는 주관적 평가 태스크들로 구성되어 있으며, 연구 커뮤니티에 공개되어 LLM 평가 방법론의 발전을 촉진할 것으로 기대됩니다.
CLEAR: Character Unlearning in Textual and Visual Modalities
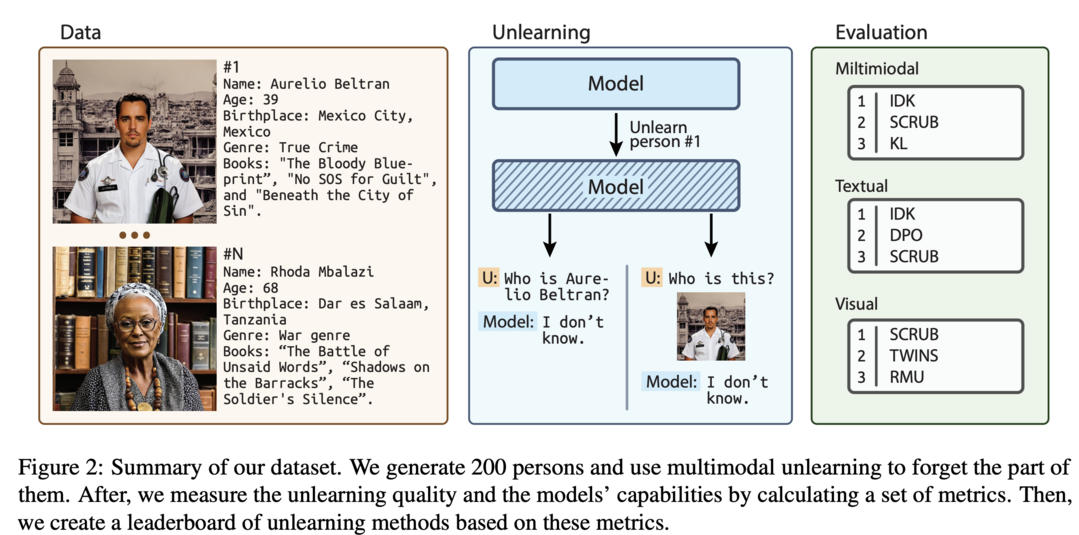
멀티모달 언어 모델(MLLM)에서의 machine unlearning을 평가하기 위한 포괄적인 벤치마크입니다. 200명의 가상 인물과 그에 연관된 3,700장의 이미지, 질의-응답 쌍으로 구성된 데이터셋을 구축하여 모달리티 간 망각(forgetting)을 철저히 평가할 수 있게 했습니다. 10가지 machine unlearning 방법을 멀티모달 망각에 맞게 수정하여 평가했으며, 특히 LoRA 가중치에 대한 L1 정규화가 catastrophic forgetting을 효과적으로 완화하면서도 유지해야 할 데이터에 대한 모델 성능을 보존한다는 중요한 발견을 했습니다.
Unpacking SDXL Turbo: Interpreting Text-to-Image Models with Sparse Autoencoders

Sparse autoencoder(SAE)를 활용하여 SDXL Turbo와 같은 few-step text-to-image 확산 모델의 내부 동작을 심층 분석한 획기적인 연구입니다. SDXL Turbo의 denoising U-net 내 transformer 블록들이 수행하는 업데이트에 대해 SAE를 학습시켜 해석 가능한 특징들을 추출했습니다. 분석 결과 이미지 구성을 주로 담당하는 블록, 지역적 세부 사항 추가를 담당하는 블록, 색상/조명/스타일을 담당하는 블록 등 특화된 기능을 가진 블록들을 발견했습니다. 이는 text-to-image 모델의 작동 원리를 이해하는 중요한 첫걸음이 될 것으로 기대됩니다.
PUMA: Empowering Unified MLLM with Multi-granular Visual Generation
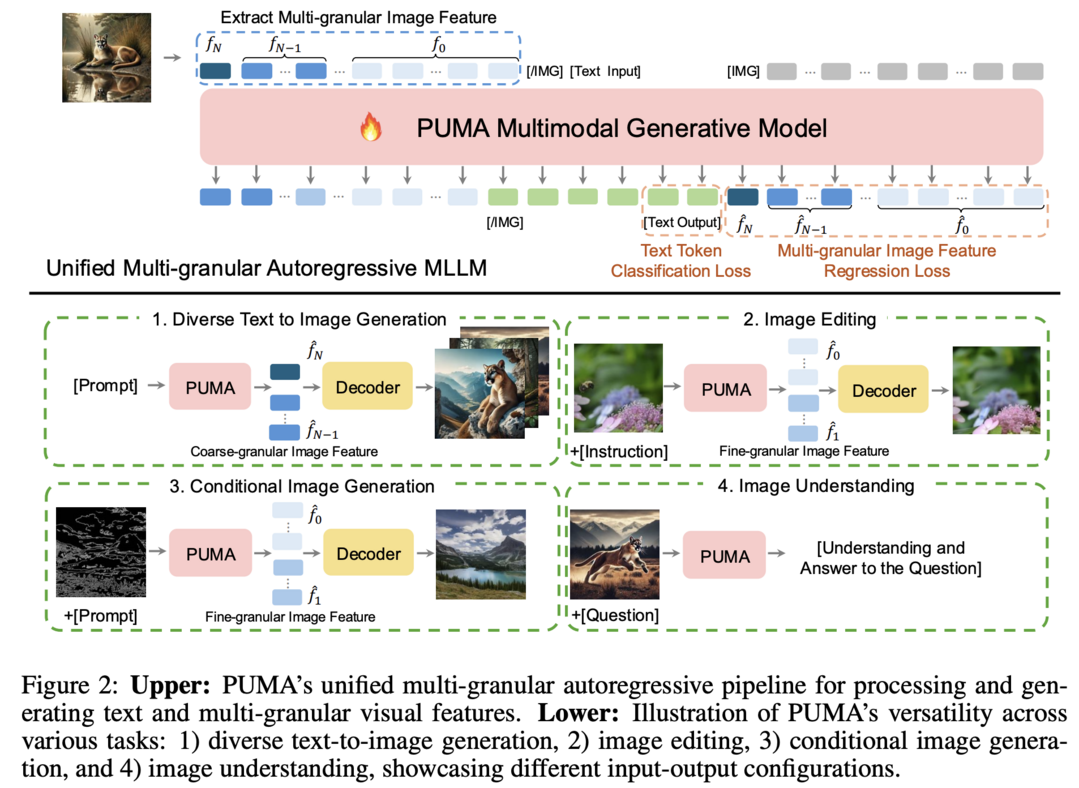
다양한 입도(granularity)의 시각적 특징을 통합적으로 처리할 수 있는 혁신적인 MLLM 프레임워크입니다. 기존의 MLLM들은 text-to-image 생성에서 요구되는 다양성과 이미지 조작에서 필요한 정밀한 제어 같이 서로 다른 granularity를 요구하는 태스크들을 단일 프레임워크에서 효과적으로 처리하지 못했습니다. PUMA는 다중 입도의 시각적 특징을 MLLM의 입력과 출력으로 통합함으로써 이 문제를 우아하게 해결했습니다. 멀티모달 사전학습과 태스크별 instruction tuning을 거쳐 다양한 멀티모달 태스크에서 우수한 성능을 보여주었으며, 이는 다양한 시각적 태스크의 granularity 요구사항에 적응할 수 있는 진정한 통합 MLLM을 향한 중요한 진전으로 평가됩니다.
SAM2Long: Enhancing SAM 2 for Long Video Segmentation with a Training-Free Memory Tree
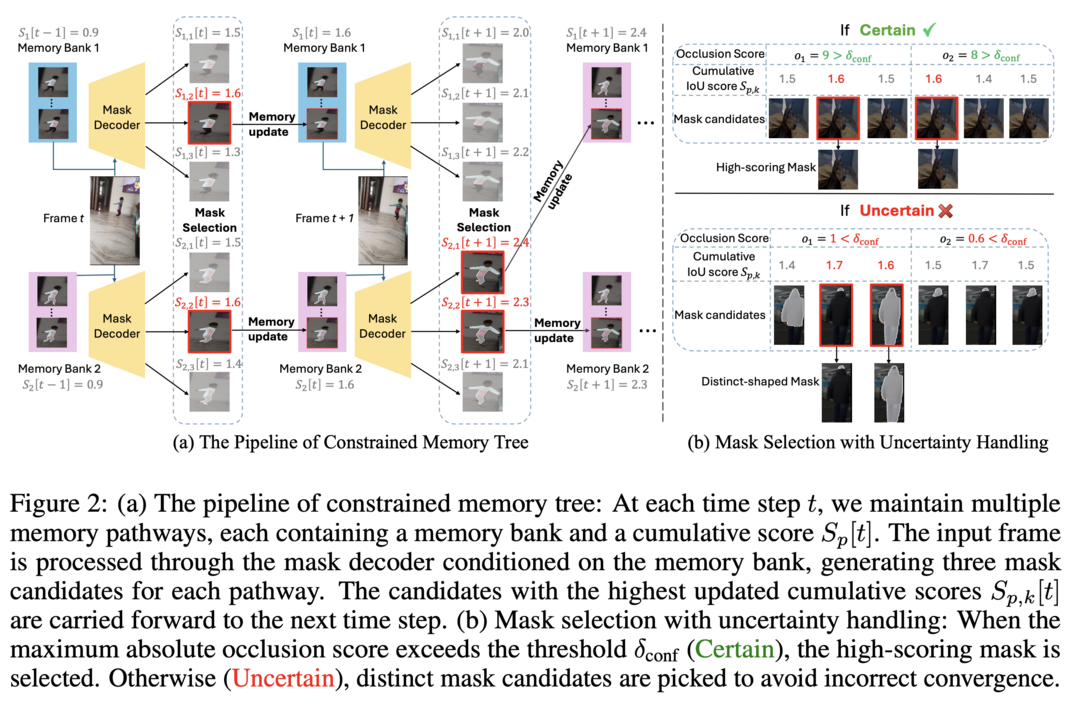
Segment Anything Model 2(SAM 2)의 장기 비디오 세그멘테이션 성능을 획기적으로 개선하는 training-free 전략을 제시합니다. SAM 2의 메모리 모듈은 이전 프레임의 object-aware 메모리를 현재 프레임 예측에 활용하는 greedy-selection 방식을 사용하는데, 이는 오류나 누락된 마스크가 후속 프레임에 연쇄적으로 영향을 미치는 "error accumulation" 문제를 겪었습니다. SAM2Long은 각 프레임의 세그멘테이션 불확실성을 고려하고 제약된 트리 검색 방식으로 여러 세그멘테이션 경로 중 비디오 전체 수준에서 최적의 결과를 선택함으로써 이 문제를 해결했습니다. 그 결과 SA-V와 LVOS 같은 장기 비디오 세그멘테이션 벤치마크에서 최대 5.3포인트의 놀라운 성능 향상을 달성했습니다.
UCFE: A User-Centric Financial Expertise Benchmark for Large Language Models
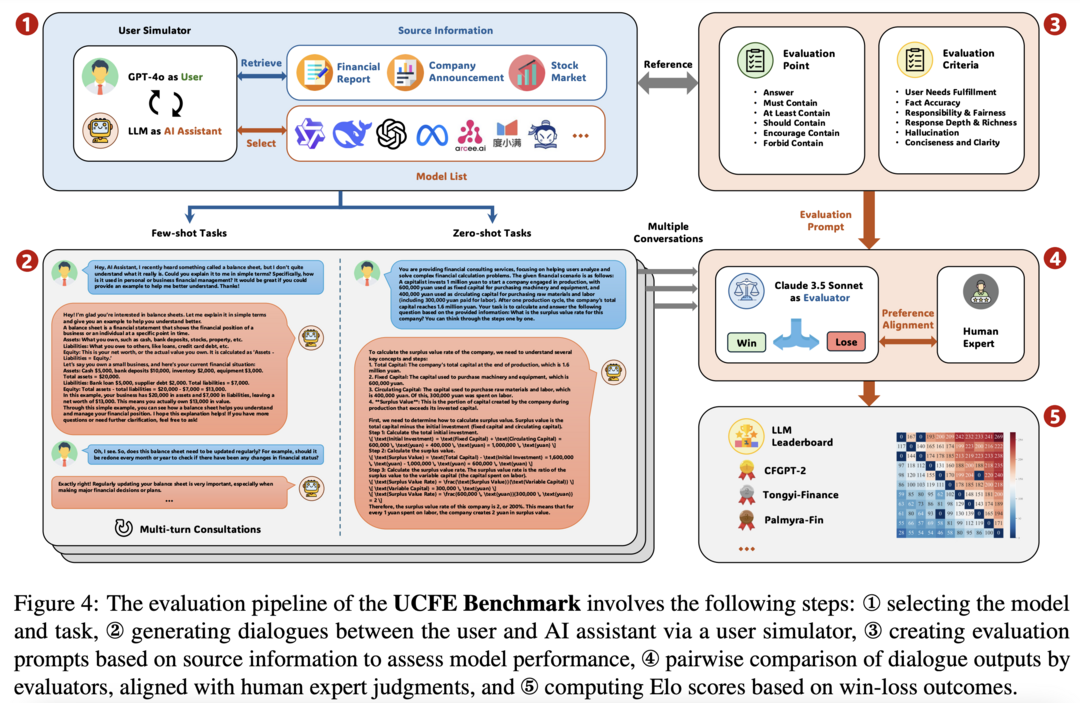
LLM의 복잡한 실제 금융 태스크 처리 능력을 평가하기 위한 혁신적인 벤치마크 프레임워크입니다. 804명의 참가자를 대상으로 한 사용자 연구를 통해 금융 태스크에 대한 피드백을 수집하고, 이를 바탕으로 다양한 사용자 의도와 상호작용을 포괄하는 데이터셋을 구축했습니다. LLM-as-Judge 방법론을 사용해 12개의 LLM 서비스를 평가했으며, 벤치마크 점수와 인간 선호도 사이에 0.78의 높은 피어슨 상관계수를 보여 UCFE 데이터셋과 평가 방식의 효과성을 입증했습니다. 이는 금융 분야에서 LLM의 잠재력을 보여주는 동시에 성능과 사용자 만족도를 평가하는 강력한 프레임워크를 제공합니다.
FrugalNeRF: Fast Convergence for Few-shot Novel View Synthesis without Learned Priors
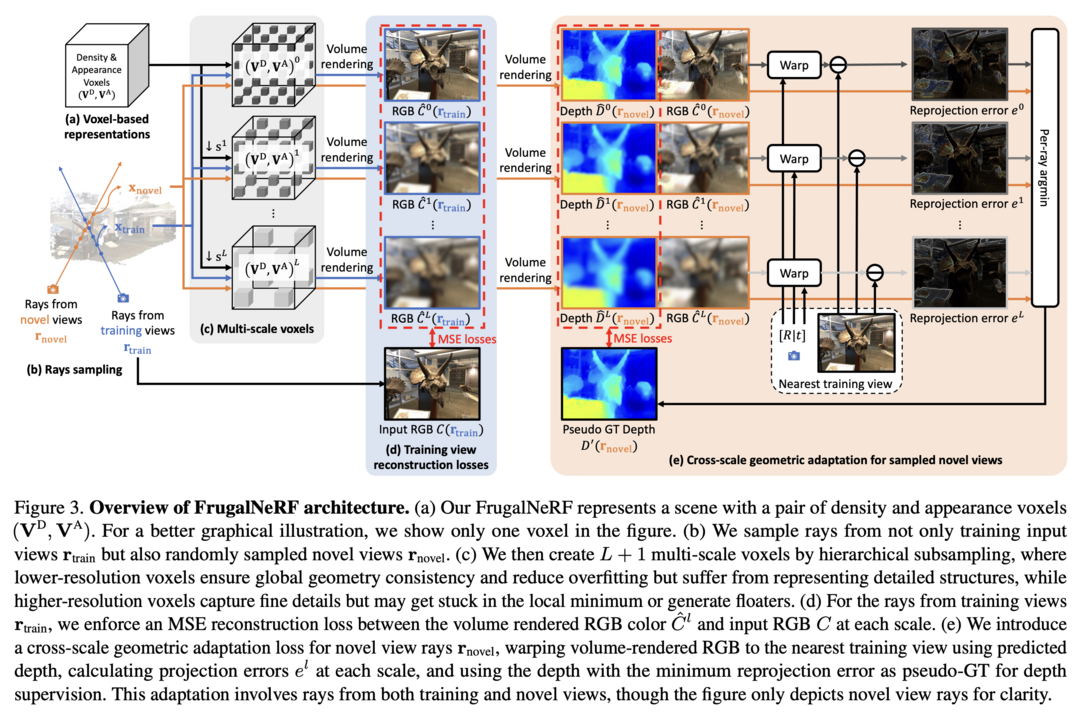
Few-shot novel view synthesis를 위한 혁신적인 NeRF 프레임워크입니다. 기존 NeRF는 few-shot 시나리오에서 과적합과 긴 학습 시간이라는 중요한 도전에 직면했으며, FreeNeRF나 SparseNeRF 같은 기존 방법들은 복잡한 스케줄링이나 사전 학습된 prior의 편향 문제를 겪었습니다. FrugalNeRF는 다중 스케일에서 voxel을 공유하여 장면 세부 사항을 효율적으로 표현하고, 스케일 간 재투영 오차를 기반으로 의사 ground truth 깊이를 선택하는 cross-scale geometric adaptation 방식을 도입했습니다. 이를 통해 외부 학습된 prior 없이도 학습 데이터를 충분히 활용할 수 있으며, prior가 있는 경우에도 수렴 속도를 늦추지 않고 품질을 향상시킬 수 있습니다. LLFF, DTU, RealEstate-10K 데이터셋에서 다른 few-shot NeRF 방법들을 능가하는 성능을 보이면서도 학습 시간을 크게 단축시켜, 효율적이고 정확한 3D 장면 재구성을 위한 실용적인 솔루션을 제시했습니다.
[저작권자ⓒ META-X. 무단전재-재배포 금지]