2024년 49주차에 공개된 주목할만한 인공지능(AI) 분야의 논문들을 소개합니다. 각 논문별 간단한 요약을 원하시는 분들은 아래의 TL;DR을 참고해주세요.
TL;DR
로보틱스/자동화 분야에서는 실제 환경에서의 적용과 자동화에 초점을 맞춘 연구들이 진행되었습니다. GRAPE는 VLA 모델의 일반화 성능을 개선하여 로봇의 다양한 작업 수행 능력을 향상시켰으며, CaM은 VLM을 활용한 실시간 모니터링과 오류 감지 시스템을 제안하여 로봇의 안전성과 신뢰성을 높였습니다. 특히 Aguvis는 순수 비전 기반의 접근 방식으로 GUI 자동화를 구현하여, 플랫폼에 구애받지 않는 자율적인 인터페이스 상호작용을 가능하게 했습니다.
이미지/비디오 생성 분야에서는 생성 모델의 효율성과 품질 향상에 주목할 만한 발전이 있었습니다. X-Prompt는 in-context learning을 통해 다양한 이미지 생성 작업을 수행할 수 있는 능력을 보여주었고, VGoT는 영화와 같은 다중 샷 비디오 생성을 위한 체계적인 프레임워크를 제시했습니다. SNOOPI는 one-step diffusion 모델의 성능을 개선하여 생성 속도와 품질의 균형을 맞추었으며, VisionZip은 시각 토큰의 중복성을 효과적으로 줄이면서도 모델의 성능을 유지하는 혁신적인 방법을 제안했습니다.
Vision-Language Models 분야에서는 기존 모델의 한계를 극복하고 성능을 향상시키는 연구가 진행되었습니다. PaliGemma 2는 Gemma 2를 기반으로 다양한 크기와 해상도를 지원하는 VLM 모델군을 확장했으며, Florence-VL은 Florence-2의 생성적 비전 인코더를 활용하여 더욱 풍부한 시각적 특징을 포착하고 이를 언어 모델과 효과적으로 결합하는 방법을 제시했습니다.
LLM 추론/성능 개선 분야에서는 모델의 추론 능력과 협력 학습에 초점을 맞춘 연구들이 진행되었습니다. O1-CODER는 MCTS와 RL을 결합하여 코딩 특화된 System-2 추론 능력을 향상시켰으며, cDPO는 critical token을 식별하고 활용하여 모델의 추론 성능을 개선했습니다. MALT는 다중 에이전트 협력 학습을 통해 수학적 추론 능력을 향상시키는 새로운 방법론을 제시했으며, 이는 복잡한 문제 해결에 있어 LLM들의 협력적 추론 가능성을 보여주었습니다.
GRAPE: Generalizing Robot Policy via Preference Alignment
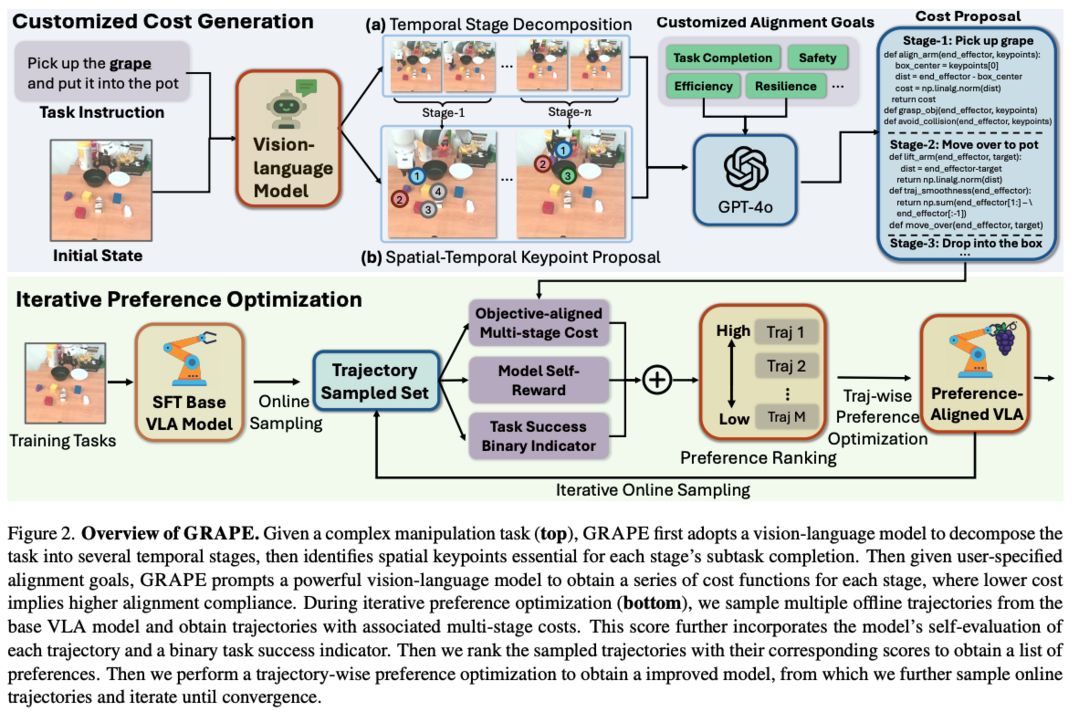
GRAPE는 VLA(Vision-Language-Action) 모델의 일반화 성능 향상을 위한 새로운 접근법을 제시합니다. 기존 VLA 모델들이 성공적인 시연 데이터만을 학습하여 새로운 작업에 대한 일반화 성능이 부족했던 문제를 해결하기 위해, 성공과 실패 사례 모두를 활용하여 보상을 모델링하고, 복잡한 작업을 독립적인 단계로 분해하여 처리합니다. 실험 결과 새로운 작업에서 60.36%의 성공률 향상을 보였으며, 모든 코드와 모델은 https://grape-vla.github.io/ 에서 확인할 수 있습니다.
Code-as-Monitor: Constraint-aware Visual Programming for Reactive and Proactive Robotic Failure Detection
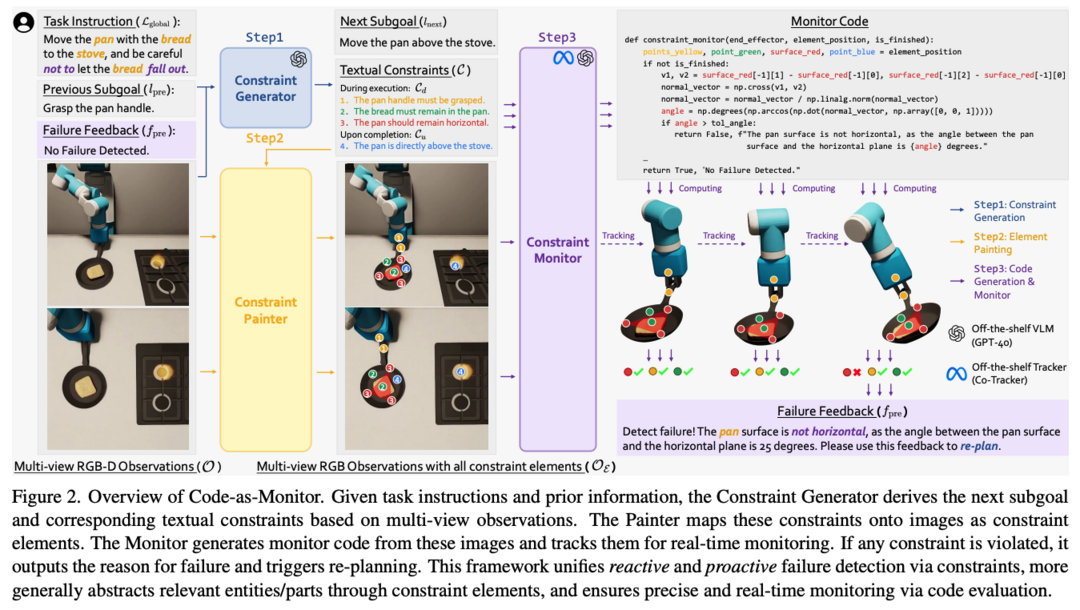
CaM(Code-as-Monitor)은 로봇 시스템의 실패 감지를 위한 혁신적인 패러다임을 제시합니다. 기존 연구들이 예기치 않은 실패를 사후에 식별하고 예측 가능한 실패를 사전에 방지하는 것을 동시에 처리하는 데 어려움을 겪었던 것에 비해, CaM은 VLM을 활용하여 두 작업을 통합된 시공간적 제약 조건 만족 문제로 정형화하고 실시간 모니터링을 위한 VLM 생성 코드를 사용합니다. 또한 제약 관련 엔티티나 그 부분들을 컴팩트한 기하학적 요소로 추상화하는 제약 요소를 도입하여 모니터링의 정확성과 효율성을 향상시켰습니다. 실험 결과 심각한 외란 상황에서도 기준선 대비 28.7% 높은 성공률과 31.8% 낮은 실행 시간을 달성했으며, 복잡한 장면과 동적 환경에서의 장기 작업을 가능하게 하는 closed-loop 시스템 구성도 가능함을 보여주었습니다.
Aguvis: Unified Pure Vision Agents for Autonomous GUI Interaction
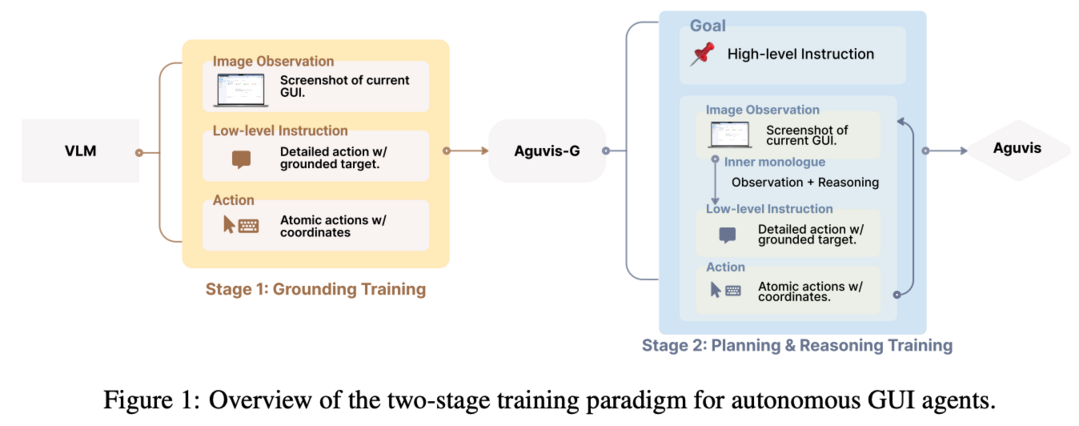
Aguvis는 순수 비전 기반의 자율적 GUI 상호작용을 위한 통합 프레임워크입니다. GUI의 복잡성과 가변성으로 인해 GUI 작업의 자동화가 어려웠던 문제를 해결하기 위해, 텍스트 표현에 의존하던 기존 접근법과 달리 이미지 기반 관찰과 자연어 명령어를 시각적 요소에 연결하는 방식을 사용합니다. 명시적 계획과 추론을 모델에 통합하여 복잡한 디지털 환경에서의 자율적 탐색과 상호작용 능력을 향상시켰으며, 다단계 훈련 파이프라인을 통해 일반적인 GUI 그라운딩부터 계획과 추론까지 수행합니다. 모든 데이터셋, 모델, 훈련 레시피는 https://aguvis-project.github.io/ 에서 확인할 수 있습니다.
X-Prompt: Towards Universal In-Context Image Generation in Auto-Regressive Vision Language Foundation Models

X-Prompt는 auto-regressive vision-language 기초 모델에서 보편적인 in-context 이미지 생성을 위한 새로운 접근법을 제시합니다. In-context 생성은 LLM의 개방형 작업 일반화 능력의 핵심 요소로, 몇 가지 예시를 문맥으로 활용하여 도메인 내외의 작업을 수행할 수 있게 합니다. LLM을 기반으로 한 auto-regressive VLM이 텍스트-이미지 생성에서 인상적인 성능을 보여주었지만, 일반적인 이미지 생성 작업에서 in-context learning의 잠재력은 아직 충분히 탐구되지 않았습니다. X-Prompt는 통합된 in-context learning 프레임워크 내에서 다양한 이미지 생성 작업에서 경쟁력 있는 성능을 제공하도록 설계되었습니다. in-context 예시에서 가치 있는 특징을 효율적으로 압축하는 특별한 설계를 통해 더 긴 문맥 토큰 시퀀스를 지원하고 새로운 작업에 대한 일반화 능력을 향상시켰으며, 텍스트와 이미지 예측을 위한 통합 훈련 작업을 통해 in-context 예시로부터 향상된 작업 인식으로 일반적인 이미지 생성을 처리할 수 있습니다.
VideoGen-of-Thought: A Collaborative Framework for Multi-Shot Video Generation
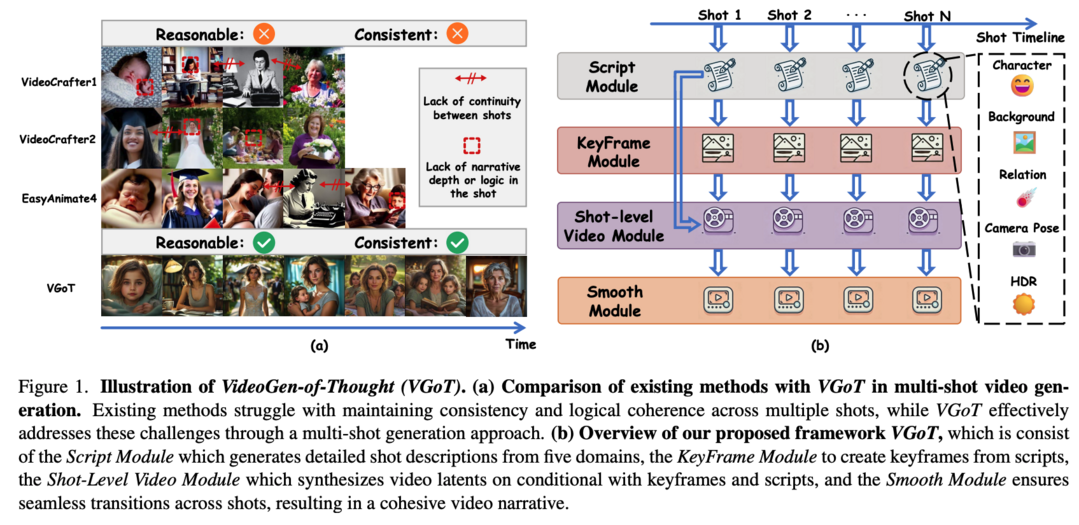
VGoT(VideoGen-of-Thought)는 다중 샷 비디오 생성을 위한 혁신적인 협업 프레임워크를 제시합니다. 현재의 비디오 생성 모델들은 짧은 클립 생성에는 탁월하지만, 영화와 같은 다중 샷 비디오 생성에는 어려움을 겪고 있습니다. 이는 대규모 데이터로 훈련된 기존 모델들이 단일 샷 목표로 훈련되어 일관된 스크립트의 여러 샷에 걸친 논리적 스토리라인과 시각적 일관성 유지가 부족하기 때문입니다. VGoT는 세 가지 주요 목표를 가지고 설계되었습니다. 첫째, 다중 샷 비디오 생성을 위해 프로세스를 (1) 간단한 이야기를 각 샷의 상세한 프롬프트로 변환하는 스크립트 생성, (2) 캐릭터 묘사에 충실한 시각적 일관성 있는 키프레임 생성, (3) 스크립트와 키프레임 정보를 샷으로 변환하는 샷 레벨 비디오 생성, (4) 일관된 다중 샷 출력을 보장하는 스무딩 메커니즘으로 구조화했습니다. 둘째, 영화 시나리오 작성에서 영감을 받은 합리적인 내러티브 디자인을 통해 전체 비디오에 걸친 논리적 일관성, 캐릭터 발전, 내러티브 흐름을 보장합니다. 셋째, identity-preserving(IP) 임베딩과 크로스 샷 스무딩 메커니즘을 통해 시간적, 정체성 일관성을 보장합니다.
SNOOPI: Supercharged One-step Diffusion Distillation with Proper Guidance

SNOOPI는 one-step diffusion 모델의 성능 향상을 위한 혁신적인 프레임워크입니다. 최근 multi-step text-to-image diffusion 모델을 one-step으로 증류하는 접근법들이 유망한 결과를 보여주고 있으며, 특히 SwiftBrushv2(SBv2)는 제한된 자원으로도 교사 모델의 성능을 뛰어넘었습니다. 그러나 Variational Score Distillation(VSD) 손실 내에서 고정된 가이던스 스케일을 사용하여 서로 다른 diffusion 모델 백본을 처리할 때 불안정성이 발생하고, 실제 이미지 생성에서 중요한 negative prompt guidance 지원이 부족한 문제가 있었습니다. SNOOPI는 이러한 한계를 해결하기 위해 훈련과 추론 과정에서 가이던스를 강화하는 새로운 방법을 제시합니다. Proper Guidance-SwiftBrush(PG-SB)를 통해 랜덤 스케일 classifier-free 가이던스 접근법을 도입하여 훈련 안정성을 향상시켰으며, Negative-Away Steer Attention(NASA)이라는 훈련이 필요 없는 방법을 통해 cross-attention을 통한 부정적 프롬프트를 통합하여 생성된 이미지에서 원하지 않는 요소를 제거합니다. HPSv2 점수 31.08을 달성하여 one-step diffusion 모델의 새로운 최고 성능을 기록했습니다.
VisionZip: Longer is Better but Not Necessary in Vision Language Models
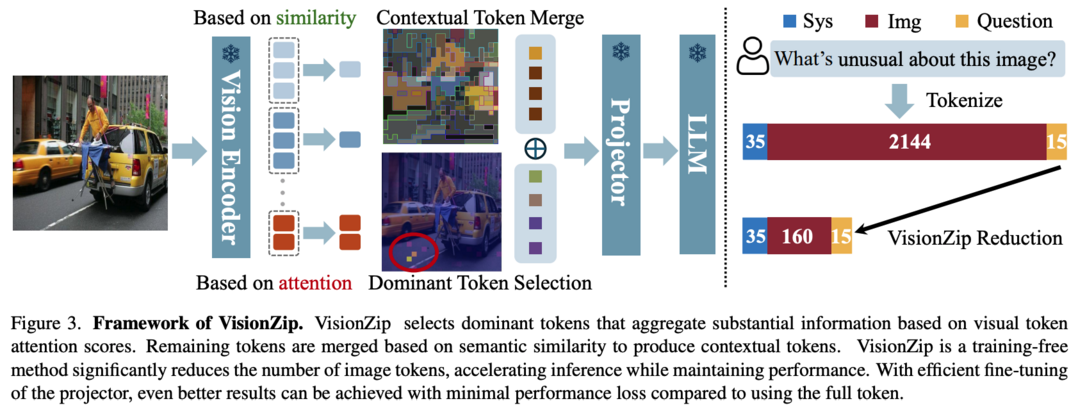
VisionZip은 VLM에서 시각 토큰의 중복성 문제를 해결하는 혁신적인 방법을 제시합니다. 최근 VLM의 성능 향상을 위해 시각 토큰의 길이를 텍스트 토큰보다 훨씬 길게 증가시키는 추세가 있었으나, 이는 계산 비용을 크게 증가시키는 문제가 있었습니다. CLIP과 SigLIP과 같은 인기 있는 비전 인코더가 생성하는 시각 토큰에 상당한 중복성이 있다는 관찰을 바탕으로, VisionZip은 언어 모델 입력을 위한 정보성 높은 토큰 집합을 선택하여 시각 토큰의 중복성을 줄이고 효율성을 개선하면서도 모델의 성능을 유지하는 방법을 제안합니다. 실험 결과 거의 모든 설정에서 기존 최신 방법 대비 최소 5%의 성능 향상을 달성했으며, prefilling 시간을 8배 개선하여 LLaVA-Next 13B 모델이 7B 모델보다 더 빠르게 추론하면서도 더 나은 결과를 얻을 수 있게 했습니다. https://github.com/dvlab-research/VisionZip 에서 코드를 확인할 수 있습니다.
PaliGemma 2: A Family of Versatile VLMs for Transfer

PaliGemma 2는 Gemma 2 언어 모델 기반의 PaliGemma 오픈 VLM을 업그레이드한 다목적 VLM 모델군입니다. PaliGemma에서도 사용된 SigLIP-So400m 비전 인코더를 2B부터 27B까지의 다양한 크기의 Gemma 2 모델과 결합했으며, 세 가지 해상도(224px, 448px, 896px)에서 다단계 훈련을 통해 fine-tuning을 통한 폭넓은 지식 전이가 가능하도록 설계되었습니다. 다양한 모델 크기와 해상도를 커버하는 기본 모델군을 통해 학습률과 같은 전이 학습 성능에 영향을 미치는 요소들을 조사하고, 작업 유형, 모델 크기, 해상도 간의 상호작용을 분석할 수 있습니다. 또한 테이블 구조 인식, 분자 구조 인식, 악보 인식과 같은 다양한 OCR 관련 작업과 상세한 이미지 캡션 생성, 방사선 보고서 생성 등 PaliGemma의 범위를 넘어선 전이 학습 작업에서 최신 성능을 달성했습니다.
Florence-VL: Enhancing Vision-Language Models with Generative Vision Encoder and Depth-Breadth Fusion
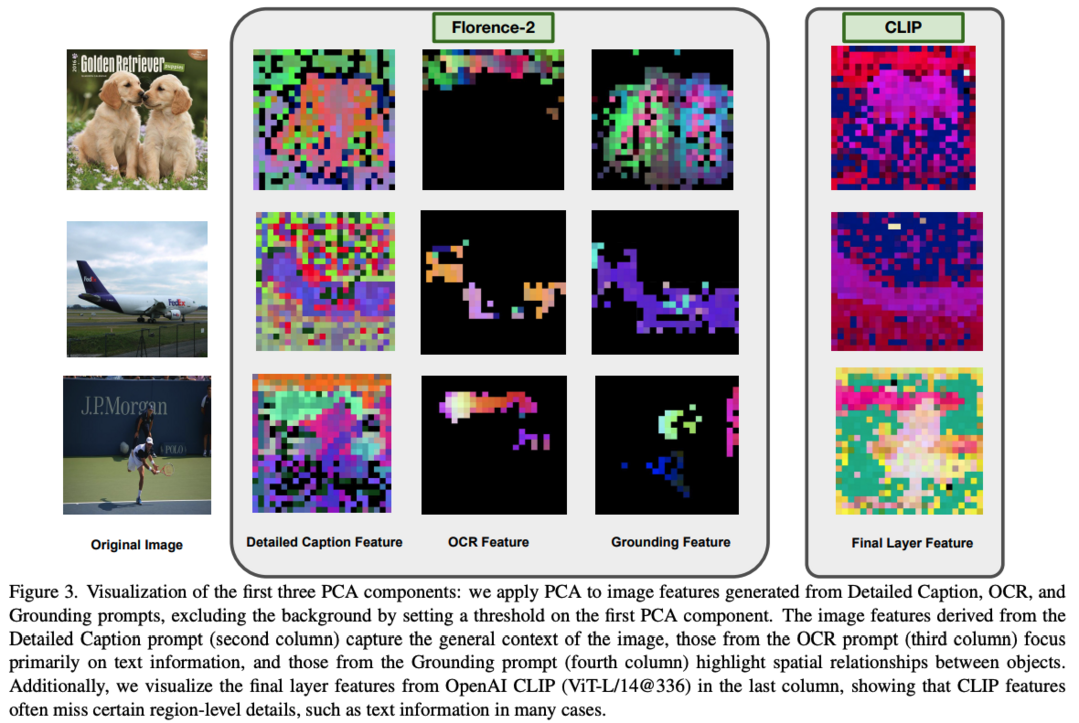
Florence-VL은 Florence-2 생성적 비전 기초 모델의 풍부한 시각적 표현을 활용한 새로운 multimodal large language models(MLLMs) 모델군을 제시합니다. 대조 학습으로 훈련된 CLIP 스타일의 vision transformer와 달리, Florence-2는 다양한 수준과 측면의 시각적 특징을 포착할 수 있어 다양한 downstream 작업에 더욱 유연하게 적용될 수 있습니다. 특히 "depth-breath fusion(DBFusion)"이라는 새로운 특징 융합 아키텍처를 제안하여 서로 다른 깊이와 다중 프롬프트에서 추출된 시각적 특징을 융합합니다. 훈련 과정은 전체 모델의 end-to-end 사전 훈련 후 projection layer와 LLM의 미세 조정으로 구성되며, 고품질 이미지 캡션과 instruction-tuning 쌍을 포함하는 다양한 오픈소스 데이터셋을 신중하게 설계된 레시피로 활용합니다. Florence-VL은 VQA, 지각, 환각, OCR, 차트, 지식 집약적 이해 등 다양한 멀티모달 및 비전 중심 벤치마크에서 기존 최신 MLLM들을 크게 개선했습니다. 모든 모델과 훈련 방법은 https://github.com/JiuhaiChen/Florence-VL 에서 공개되어 있습니다.
o1-Coder: an o1 Replication for Coding
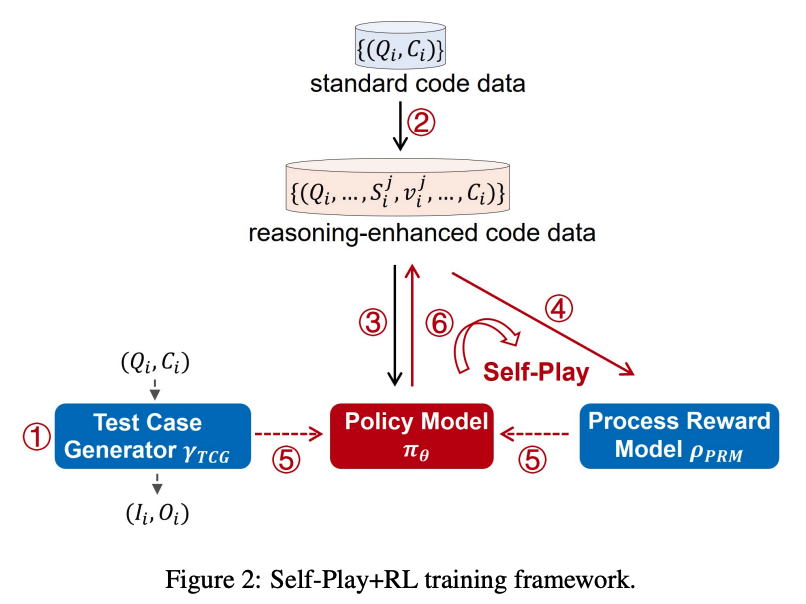
O1-CODER는 OpenAI의 o1 모델을 코딩 작업에 특화하여 복제한 시도입니다. System-2 사고 능력을 강화하기 위해 강화학습(RL)과 Monte Carlo Tree Search(MCTS)를 통합했으며, 표준화된 코드 테스팅을 위한 Test Case Generator(TCG) 훈련, 추론 과정이 포함된 코드 데이터 생성을 위한 MCTS 활용, 그리고 초기에 의사코드를 생성한 후 전체 코드를 생성하는 반복적인 정책 모델 미세 조정을 포함합니다. 이 보고서는 실제 응용에서 o1 유형 모델 배포의 기회와 도전 과제를 다루며, System-2 패러다임으로의 전환과 환경 상태 업데이트의 필요성을 강조합니다. 모든 소스 코드, 데이터셋, 파생 모델은 https://github.com/ADaM-BJTU/O1-CODER 에서 공개될 예정입니다.
Critical Tokens Matter: Token-Level Contrastive Estimation Enhence LLM's Reasoning Capability
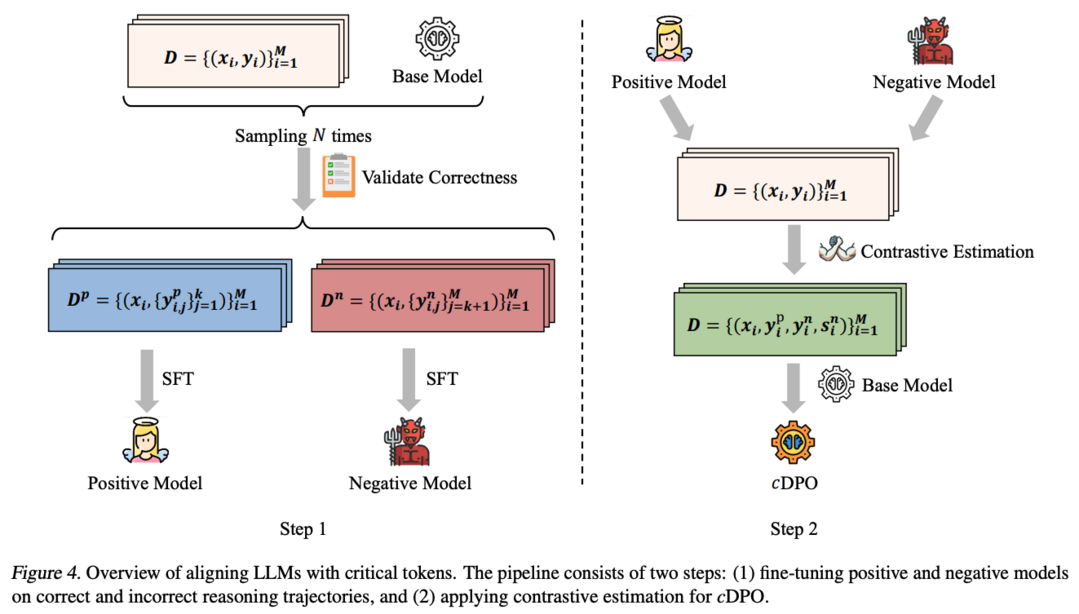
cDPO는 LLM의 추론 능력 향상을 위해 토큰 레벨의 대조적 추정을 제안하는 연구입니다. LLM이 autoregressive 토큰 생성을 통해 추론 궤적을 구성하고 일관된 사고의 흐름을 개발할 수 있게 하는데, 이 연구는 개별 토큰이 추론 작업의 최종 결과에 미치는 영향을 탐구합니다. 특히 LLM에서 잘못된 추론 궤적으로 이어지는 'critical token'의 존재를 식별하고, 이러한 토큰 대신 다른 토큰을 디코딩하도록 강제할 때 긍정적인 결과가 나타남을 발견했습니다. 이러한 관찰을 바탕으로, alignment 과정에서 critical token을 자동으로 인식하고 토큰 레벨의 보상을 수행하도록 설계된 cDPO를 제안합니다. GSM8K와 MATH500 벤치마크에서 Llama-3(8B, 70B)와 deepseek-math(7B) 모델을 사용한 실험을 통해 제안된 접근법의 효과성을 입증했습니다.
MALT: Improving Reasoning with Multi-Agent LLM Training
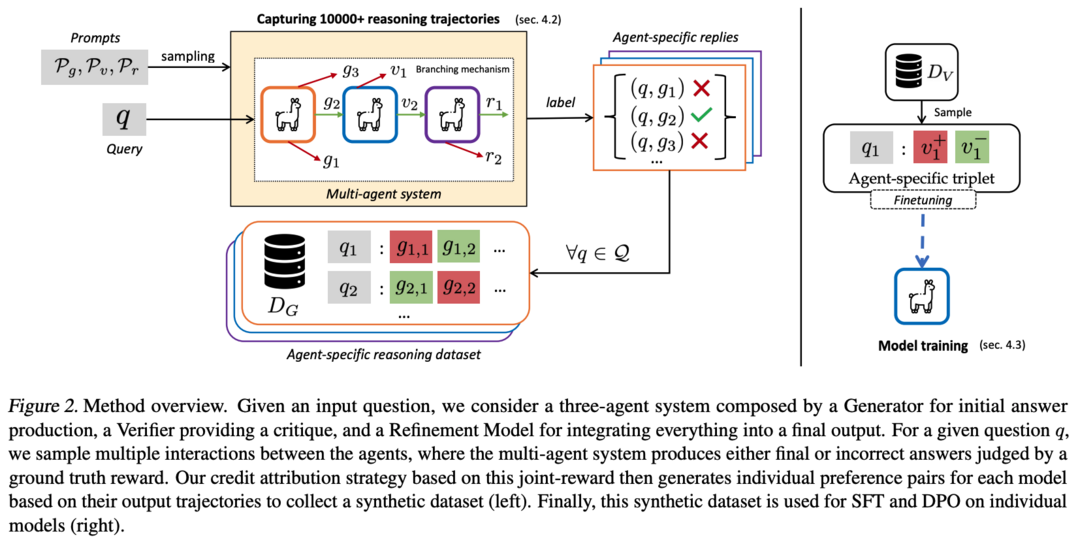
MALT는 복잡한 문제 해결을 위한 LLM 간의 효과적인 협력을 가능하게 하는 "Multi-agent LLM training" 접근법을 제시합니다. LLM이 일반적으로 단일 모델 생성기로 사용되고 인간이 출력을 비평하고 개선하는 방식이었다면, MALT는 생성기, 검증기, 개선 모델이라는 특화된 역할을 가진 이종 LLM들이 순차적으로 협력하여 문제를 해결하는 방식을 제안합니다. 궤적 확장 기반의 합성 데이터 생성 프로세스와 공동 결과 기반 보상에 의한 credit assignment 전략을 통해, 훈련 후 설정에서 긍정적 및 부정적 궤적을 모두 활용하여 각 모델의 특화된 능력을 자율적으로 개선합니다. MATH, GSM8k, CQA에서의 실험 결과, Llama 3.1 8B 모델을 사용한 MALT는 동일한 기준 모델 대비 각각 14.14%, 7.12%, 9.40%의 상대적 성능 향상을 달성했습니다.
[저작권자ⓒ META-X. 무단전재-재배포 금지]