2024년 50주차에 공개된 주목할만한 인공지능(AI) 분야의 논문들을 소개합니다. 각 논문별 간단한 요약을 원하시는 분들은 아래의 TL;DR을 참고해주세요.
TL;DR
멀티모달 AI 분야에서는 다양한 형태의 발전이 이루어지고 있습니다. InternVL 2.5는 기존 모델의 성능을 대폭 향상시켰으며, GPT-4와 Claude-3.5-Sonnet과 견줄 만한 성능을 보여주고 있습니다. MAmmoTH-VL은 대규모 instruction tuning을 통해 멀티모달 추론 능력을 향상시켰고, InternLM-XComposer2.5-OmniLive는 장기 스트리밍 환경에서의 상호작용을 가능하게 했습니다. Euclid는 합성 데이터를 활용하여 기하학적 시각 인식 능력을 강화했습니다.
생성형 AI 분야는 특히 비디오와 이미지 생성에서 주목할 만한 발전을 보였습니다. LiFT는 인간 피드백을 활용하여 텍스트-비디오 생성 모델의 정확도를 높였고, STIV는 확장 가능한 텍스트/이미지 기반 비디오 생성 시스템을 제시했습니다. DiffSensei는 멀티모달 LLM과 확산 모델을 결합하여 맞춤형 만화 생성을 가능하게 했으며, SynCamMaster는 다중 카메라 시점에서의 비디오 생성 동기화를 실현했습니다. LAION-SG는 구조적 주석이 포함된 대규모 이미지-텍스트 데이터셋을 제공했습니다.
언어 모델 분야에서는 실용성과 효율성에 초점을 맞춘 연구가 진행되었습니다. EXAONE 3.5는 실제 사용 사례에 최적화된 다양한 크기의 언어 모델을 제시했으며, Phi-4는 데이터 품질에 중점을 둔 140억 파라미터 규모의 언어 모델을 개발했습니다.
최적화 및 학습 방법론 측면에서는 효율성 향상을 위한 새로운 접근법들이 제시되었습니다. APOLLO는 SGD 수준의 메모리 사용량으로 AdamW와 동등한 성능을 달성했으며, Coconut은 연속적 잠재 공간에서의 LLM 추론 학습이라는 새로운 패러다임을 제시했습니다.
평가 및 벤치마크 분야에서는 더욱 정교한 평가 방법들이 개발되었습니다. ProcessBench는 수학적 추론의 프로세스 오류를 식별하는 새로운 벤치마크를 제시했으며, CodeArena는 코드 생성 LLM의 인간 선호도 측면에서의 평가 기준을 제시했습니다.
강화학습 분야에서는 Unraveling the Complexity of Memory in RL Agents 연구를 통해 RL 에이전트의 메모리를 체계적으로 분류하고 평가하는 새로운 방법론이 제시되었습니다.
Expanding Performance Boundaries of Open-Source Multimodal Models with Model, Data, and Test-Time Scaling
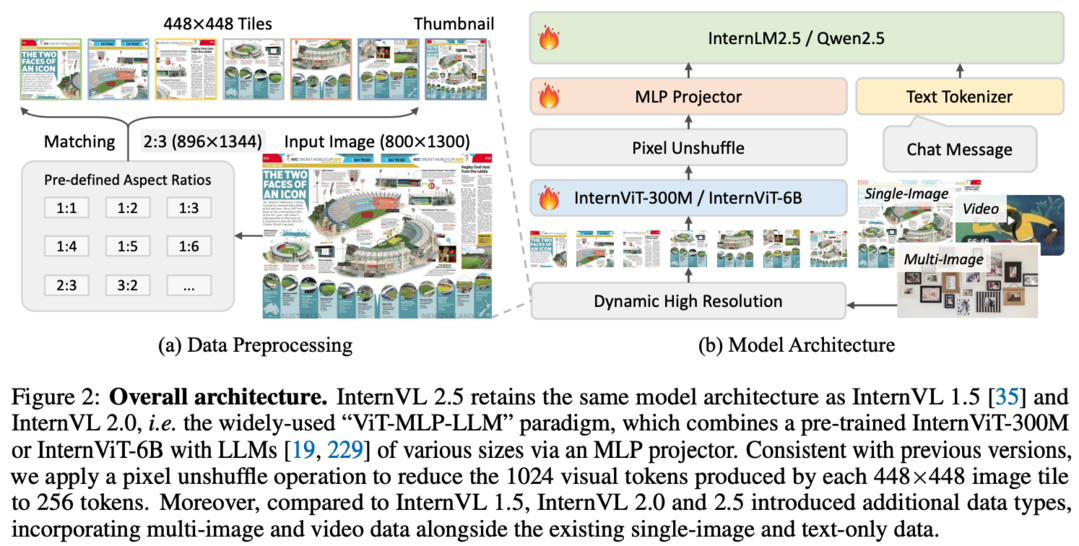
InternVL 2.5는 기존의 InternVL 2.0을 기반으로 한 발전된 다중 모달 대규모 언어 모델(MLLM)로, 기본적인 모델 구조는 유지하면서 훈련 및 테스트 전략과 데이터 품질 면에서 큰 발전을 이룬 시스템입니다. 이 모델은 시각 인코더, 언어 모델, 데이터셋 크기, 테스트 시 구성 등 다양한 측면에서의 성능 추세를 체계적으로 연구했으며, 특히 다분야 추론, 문서 이해, 다중 이미지/비디오 이해, 실제 환경에서의 이해력, 다중 모달 환각 감지, 시각적 접지, 다국어 기능, 순수 언어 처리 등 광범위한 벤치마크 평가에서 GPT-4와 Claude-3.5-Sonnet 같은 상용 모델들과 견줄 만한 성능을 보여주었습니다. 특히 사고의 연쇄(Chain-of-Thought) 추론을 통해 MMMU 벤치마크에서 70%를 넘는 성과를 달성한 최초의 오픈소스 MLLM이 되었으며, 이는 3.7포인트의 성능 향상을 이룬 것으로, 테스트 시 스케일링에서도 큰 잠력을 보여주고 있어 다중 모달 AI 시스템 개발에 있어 새로운 기준을 제시하는 오픈소스 커뮤니티에 큰 기여를 할 것으로 기대됩니다.
(Project: https://huggingface.co/spaces/OpenGVLab/InternVL)
MAmmoTH-VL: Eliciting Multimodal Reasoning with Instruction Tuning at Scale

오픈소스 다중 모달 대규모 언어 모델(MLLMs)들이 다양한 다중 모달 작업에서 큰 잠재력을 보여주고 있지만, VQA, AI2D, ChartQA와 같은 학술 데이터셋에서 재활용된 기존의 지시문 튜닝 데이터셋으로 인해 추론 능력에 제한이 있었다는 점에 주목한 연구 내용입니다. 기존 데이터셋들이 단순한 작업만을 대상으로 하고 중간 근거 없이 구절 수준의 답변만 제공했던 한계를 극복하기 위해, 연구진들은 사고의 연쇄(CoT) 추론을 유도하도록 설계된 풍부한 중간 근거를 포함한 대규모 다중 모달 지시문 튜닝 데이터셋을 구축하는 확장 가능하고 비용 효율적인 방법을 제시했습니다. 이들은 오픈 모델만을 사용하여 상세하고 신뢰할 수 있는 근거와 함께 다양한 추론 중심 작업을 포함하는 1,200만 개의 지시문-응답 쌍을 생성했으며, 이 데이터셋으로 훈련된 MLLMs는 MathVerse(8.1% 향상), MMMU-Pro(7% 향상), MuirBench(13.3% 향상)와 같은 벤치마크에서 최고 성능을 달성했고, 추론 기반이 아닌 벤치마크에서도 최대 4%의 주목할 만한 성능 향상을 보여주었으며, 데이터셋 구축 과정에서 재작성과 자체 필터링과 같은 핵심 요소들의 중요성도 입증되었습니다.
InternLM-XComposer2.5-OmniLive: A Comprehensive Multimodal System for Long-term Streaming Video and Audio Interactions
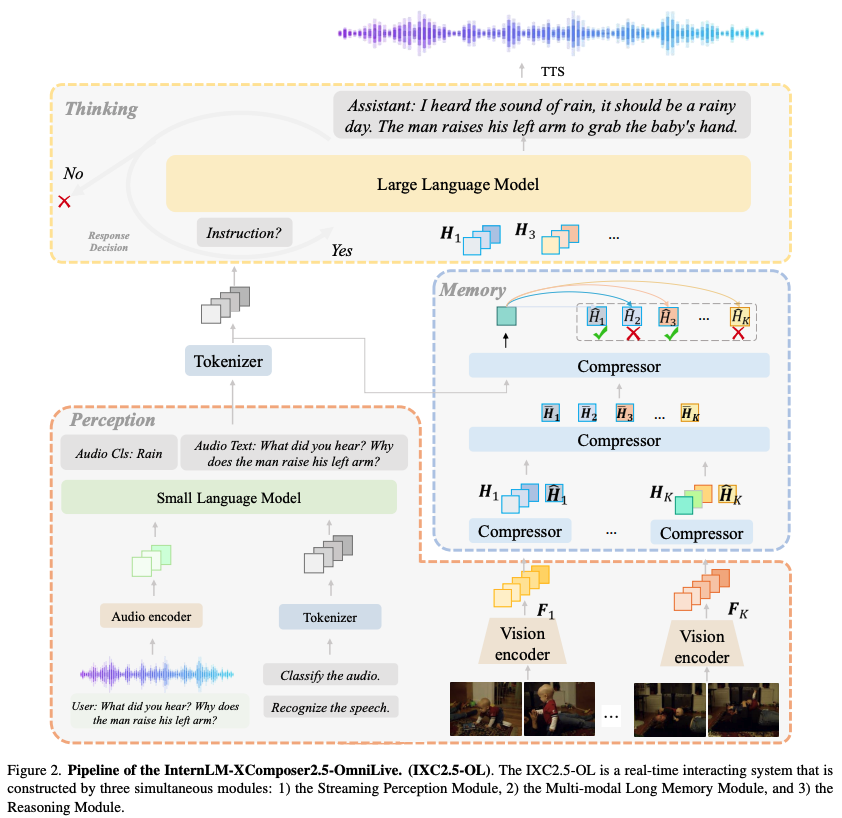
인간의 인지 능력과 유사하게 장시간 동안 환경과 상호작용할 수 있는 AI 시스템을 만드는 것이 오랜 연구 목표였는데, 최근 다중 모달 대규모 언어 모델(MLLMs)의 발전으로 개방형 세계 이해에 큰 진전이 있었지만 연속적이고 동시다발적인 스트리밍 인식, 기억, 추론의 과제는 여전히 미개척 영역으로 남아있었습니다. 이에 InternLM-XComposer2.5-OmniLive(IXC2.5-OL)라는 새로운 프레임워크가 제안되었는데, 이는 실시간으로 다중 모달 정보를 처리하고 핵심 세부사항을 메모리에 저장하며 사용자 쿼리에 대한 추론을 트리거하는 '스트리밍 인식 모듈', 단기 메모리를 장기 메모리로 압축하여 효율적인 검색과 정확도 향상을 가능하게 하는 '다중 모달 장기 메모리 모듈', 그리고 인식 및 메모리 모듈과 협력하여 쿼리에 응답하고 추론 작업을 실행하는 '추론 모듈'이라는 세 가지 핵심 모듈로 구성되어 있습니다. 이 프로젝트는 단일 기초 모델에 의존하지 않고 전문화된 일반주의 AI 개념에서 영감을 받아 분리된 스트리밍 인식, 추론, 메모리 메커니즘을 도입함으로써 스트리밍 비디오와 오디오 입력에 대한 실시간 상호작용을 가능하게 하여 인간과 유사한 인지를 시뮬레이션하고 시간이 지남에 따라 지속적이고 적응적인 서비스를 제공할 수 있게 합니다.
(Project: https://github.com/InternLM/InternLM-XComposer/tree/main/InternLM-XComposer-2.5-OmniLive)
Euclid: Supercharging Multimodal LLMs with Synthetic High-Fidelity Visual Descriptions
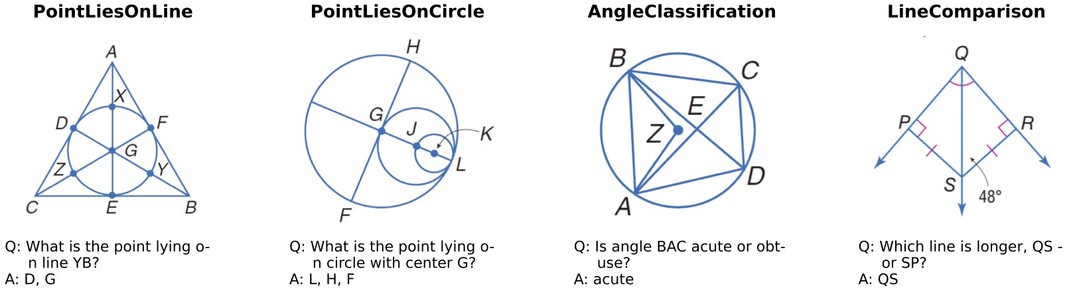
Geoperception이라는 새로운 벤치마크를 통해 다중 모달 대규모 언어 모델(MLLMs)의 낮은 수준의 시각적 인식(LLVP), 특히 이미지의 기하학적 세부사항을 정확하게 설명하는 능력을 평가하고 개선하는 연구가 진행되었습니다. 연구진들은 주요 MLLMs의 한계를 입증한 후, 기하학적 작업에서의 성능 향상을 위한 전략을 탐구하는 포괄적인 실험 연구를 수행했으며, 고품질 합성 데이터의 사용과 데이터 커리큘럼을 통한 다단계 훈련을 포함한 특정 모델 아키텍처, 훈련 기법, 데이터 전략의 이점을 발견했습니다. 특히 데이터 커리큘럼이 모델이 처음부터 학습하기 어려운 복잡한 기하학 이해 작업을 학습할 수 있게 한다는 점이 주목할 만하며, 이러한 통찰을 바탕으로 강력한 저수준 기하학적 인식에 최적화된 Euclid라는 모델군을 개발했는데, 순수하게 합성 다중 모달 데이터로만 훈련되었음에도 새로운 기하학적 형태에 대한 강력한 일반화 능력을 보여주어 특정 Geoperception 벤치마크 작업에서 최고의 비공개 모델인 Gemini-1.5-Pro보다 최대 58.56%, 모든 작업에서 평균 10.65% 더 우수한 성능을 달성했습니다. (Project: https://euclid-multimodal.github.io/)
LiFT: Leveraging Human Feedback for Text-to-Video Model Alignment
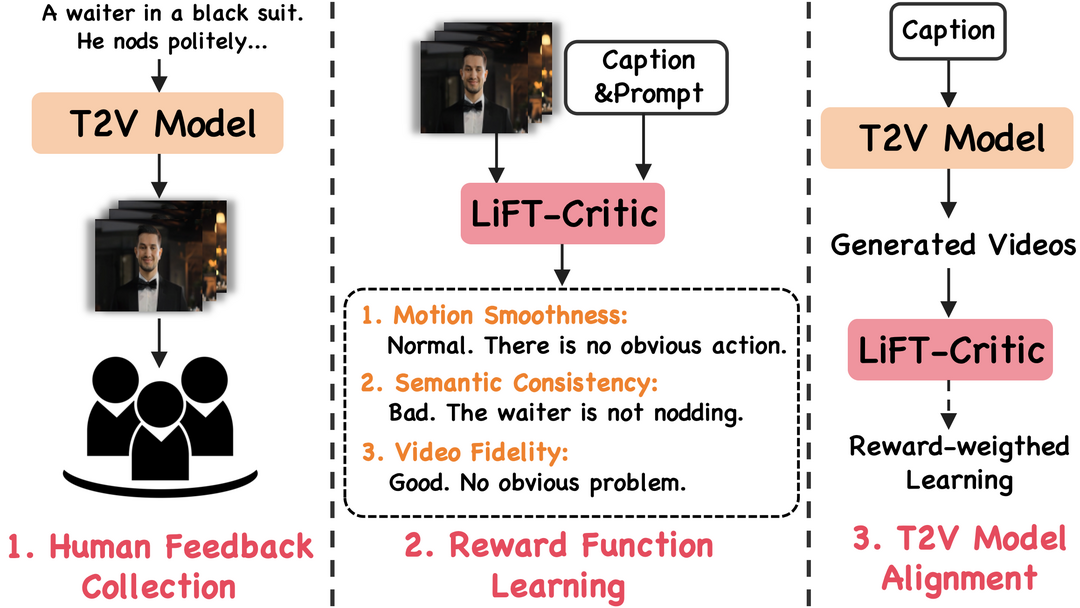
최근 텍스트-투-비디오(T2V) 생성 모델들이 인상적인 성능을 보여주고 있지만, 인간의 선호도(예: 텍스트 설명을 정확하게 반영하는 것)와 생성된 비디오를 일치시키는 데에는 여전히 부족함이 있어, 이를 해결하기 위해 LiFT라는 새로운 미세 조정 방법이 제안되었습니다. 연구진들은 먼저 약 1만 개의 인간 평가 점수와 그에 대한 근거를 포함하는 LiFT-HRA(Human Rating Annotation) 데이터셋을 구축하고, 이를 바탕으로 주어진 비디오와 인간의 기대치 간의 일치도를 측정하는 인간 판단의 대리자 역할을 하는 LiFT-Critic이라는 보상 모델을 학습시켰으며, 최종적으로 이 학습된 보상 함수를 활용하여 보상 가중치가 적용된 가능성을 최대화하는 방식으로 T2V 모델을 조정했습니다. 특히 CogVideoX-2B에 이 파이프라인을 적용한 결과, 미세 조정된 모델이 16개의 모든 메트릭에서 CogVideoX-5B보다 더 나은 성능을 보여주어 합성 비디오의 품질과 일치도 향상에 있어 인간 피드백의 잠재력을 입증했다는 점이 주목할 만합니다. (Project: https://codegoat24.github.io/LiFT/)
STIV: Scalable Text and Image Conditioned Video Generation
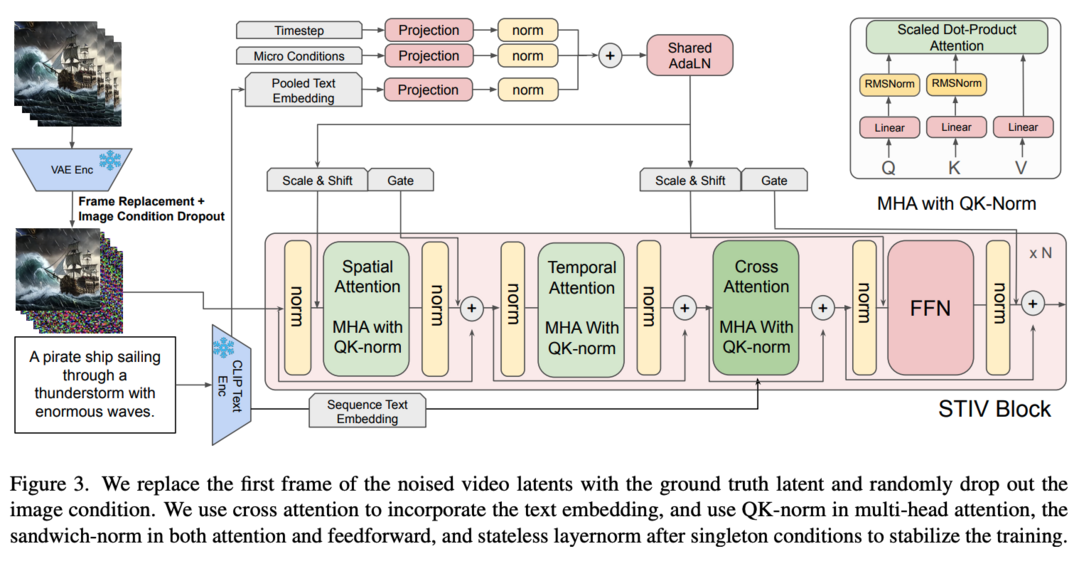
비디오 생성 분야가 눈부신 발전을 이루었지만, 견고하고 확장 가능한 모델 개발을 안내할 수 있는 명확하고 체계적인 방법론이 필요한 상황에서 STIV라는 새로운 텍스트-이미지 조건부 비디오 생성 방법이 제안되었습니다. 이 프레임워크는 프레임 교체를 통해 이미지 조건을 확산 트랜스포머(DiT)에 통합하고, 이미지-텍스트 결합 조건부 분류기 없는 가이던스를 통해 텍스트 조건을 통합함으로써 텍스트-투-비디오(T2V)와 텍스트-이미지-투-비디오(TI2V) 작업을 동시에 수행할 수 있으며, 비디오 예측, 프레임 보간, 다중 시점 생성, 긴 비디오 생성 등 다양한 응용 분야로도 쉽게 확장될 수 있습니다. 특히 512 해상도의 8.7B 모델은 VBench T2V에서 83.1점을 달성하여 CogVideoX-5B, Pika, Kling, Gen-3와 같은 주요 오픈소스 및 비공개 모델들을 능가했으며, 같은 크기의 모델이 512 해상도에서 VBench I2V 작업에서도 90.1점이라는 최고 성능을 달성했다는 점에서, 이 연구는 최첨단 비디오 생성 모델을 구축하기 위한 투명하고 확장 가능한 방법론을 제공함으로써 더 다재다능하고 신뢰할 수 있는 비디오 생성 솔루션을 향한 발전을 가속화할 것으로 기대됩니다.
DiffSensei: Bridging Multi-Modal LLMs and Diffusion Models for Customized Manga Generation
텍스트-이미지 생성 모델들의 발전으로 스토리 시각화 기술이 발전해왔지만, 특히 여러 캐릭터가 등장하는 장면에서 캐릭터의 외모와 상호작용을 효과적으로 제어하는 데 한계가 있었다는 점에 착안하여, 연구진들은 맞춤형 망가 생성이라는 새로운 과제를 제안하고 다중 캐릭터 제어가 가능한 DiffSensei라는 혁신적인 프레임워크를 개발했습니다. 이 프레임워크는 확산 기반 이미지 생성기와 텍스트 호환 신원 어댑터 역할을 하는 다중 모달 대규모 언어 모델(MLLM)을 통합하여, 마스크된 교차 주의 메커니즘을 사용해 직접적인 픽셀 전송 없이도 정확한 레이아웃 제어가 가능하게 하고, MLLM 기반 어댑터를 통해 패널별 텍스트 신호에 맞춰 캐릭터의 표정, 포즈, 행동을 유연하게 조정할 수 있게 합니다. 또한 43,264페이지의 망가와 427,147개의 주석이 달린 패널을 포함하는 대규모 데이터셋 MangaZero를 구축하여 연속된 프레임에서 다양한 캐릭터 상호작용과 움직임의 시각화를 지원하며, 광범위한 실험을 통해 DiffSensei가 기존 모델들보다 우수한 성능을 보여주어 텍스트 적응형 캐릭터 커스터마이징을 가능하게 하는 망가 생성 기술의 중요한 진전을 이루었음을 입증했습니다.(Project: https://jianzongwu.github.io/projects/diffsensei/)
SynCamMaster: Synchronizing Multi-Camera Video Generation from Diverse Viewpoints
최근 비디오 확산 모델들이 실제 세계의 동적 특성을 시뮬레이션하고 3D 일관성을 유지하는 데 탁월한 능력을 보여주면서, 연구진들은 가상 촬영과 같은 응용 분야에서 매우 중요한 다양한 시점 간의 동적 일관성을 보장하는 잠재력을 연구하게 되었습니다. 이들은 4D 재구성을 위한 단일 객체의 다중 시점 생성에 초점을 맞춘 기존 방법들과 달리, 6 자유도 카메라 포즈를 포함하여 임의의 시점에서 개방형 세계 비디오를 생성하는 데 관심을 두고, 사전 훈련된 텍스트-투-비디오 모델을 다중 카메라 비디오 생성용으로 강화하는 플러그 앤 플레이 모듈을 제안했습니다. 특히 다중 시점 동기화 모듈을 도입하여 서로 다른 시점 간의 외관과 기하학적 일관성을 유지하고, 고품질 훈련 데이터의 부족 문제를 해결하기 위해 언리얼 엔진으로 렌더링된 다중 카메라 비디오를 보완하는 다중 카메라 이미지와 단안 비디오를 활용하는 하이브리드 훈련 방식을 설계했으며, 새로운 시점에서 비디오를 재렌더링하는 등의 흥미로운 확장도 가능하게 하고 SynCamVideo-Dataset이라는 다중 시점 동기화 비디오 데이터셋도 공개했습니다.(Project: https://jianhongbai.github.io/SynCamMaster/)
LAION-SG: An Enhanced Large-Scale Dataset for Training Complex Image-Text Models with Structural Annotations
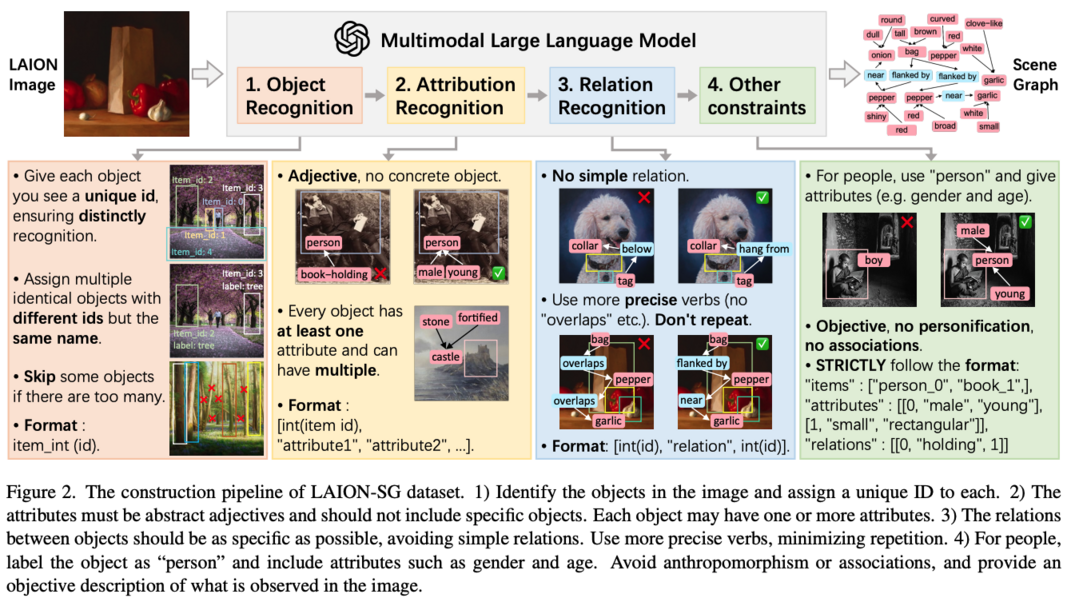
텍스트-투-이미지(T2I) 생성 기술이 텍스트로부터 고품질 이미지를 생성하는 데 놀라운 성공을 보여주었지만, 기존 T2I 모델들이 여러 객체와 복잡한 관계가 포함된 구성적 이미지 생성에서는 성능이 저하되는 문제를 보여왔는데, 연구진들은 이를 프롬프트만으로는 객체 간 관계를 정확하게 주석 처리하지 못하는 기존 이미지-텍스트 쌍 데이터셋의 한계로 보고, 복잡한 장면의 의미 구조를 효과적으로 표현하기 위해 여러 객체의 속성과 관계를 정확하게 설명하는 고품질 장면 그래프(SG) 구조 주석이 포함된 대규모 데이터셋 LAION-SG를 구축했습니다. 이를 기반으로 구조적 주석 정보를 생성 과정에 통합하는 새로운 기초 모델 SDXL-SG를 훈련시켰으며, 광범위한 실험을 통해 LAION-SG로 훈련된 고급 모델들이 기존 데이터셋으로 훈련된 모델들보다 복잡한 장면 생성에서 큰 성능 향상을 보여주었고, 구성적 이미지 생성에 대한 모델을 평가하는 CompSG-Bench라는 새로운 벤치마크도 도입하여 이 분야의 새로운 기준을 수립했습니다.
EXAONE 3.5: Series of Large Language Models for Real-world Use Cases
LG AI Research에서 개발하고 공개한 EXAONE 3.5 언어 모델은 32B, 7.8B, 2.4B 세 가지 규모로 제공되는 지시문 기반 언어 모델로, 특히 실제 상황에서의 지시 수행 능력에서 7개의 벤치마크에서 최고 점수를 달성했으며, 긴 문맥 이해 능력에서도 4개의 벤치마크에서 최상위 성능을 보여주었고, 9개의 일반 벤치마크에서도 비슷한 규모의 최신 공개 모델들과 견줄 만한 경쟁력 있는 결과를 보여주었다는 점이 주목할 만한 특징입니다. 이 모델은 연구 목적으로는 누구나 허깅페이스(HuggingFace)를 통해 자유롭게 다운로드하여 사용할 수 있으며, 상업적 사용을 원하는 경우에는 LG AI Research의 공식 연락처를 통해 문의할 수 있도록 하고 있어, 연구와 상업적 활용 모두를 고려한 접근성 있는 모델임을 알 수 있습니다.
(Project: https://huggingface.co/LGAI-EXAONE)
Phi-4 Technical Report
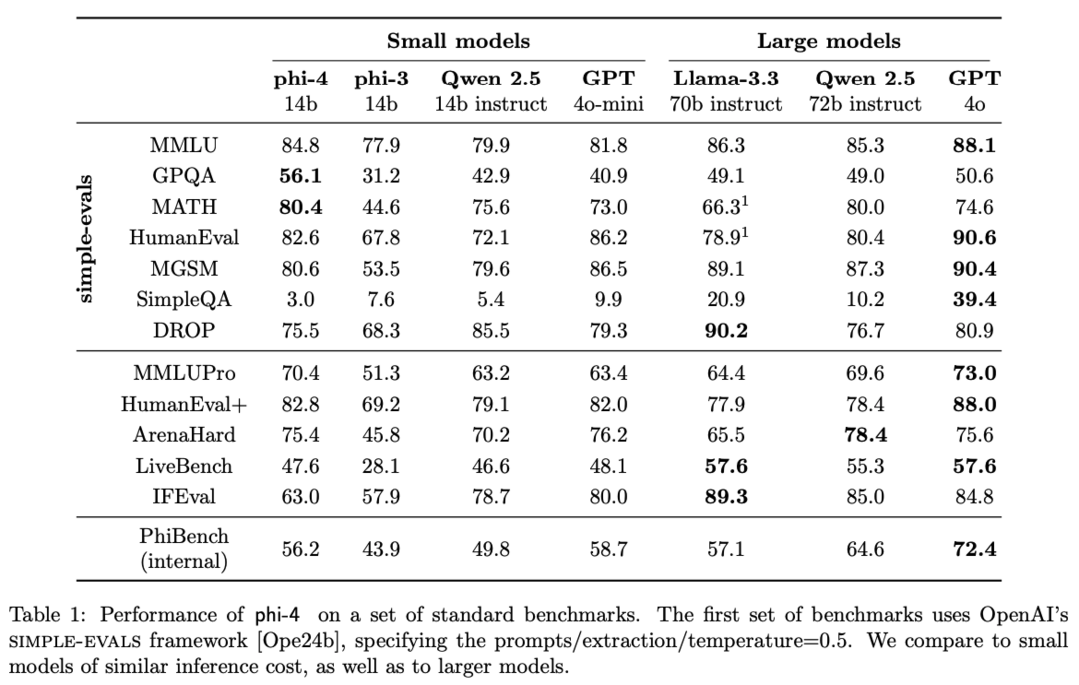
Microsoft의 14B 파라미터 규모의 언어 모델인 phi-4는 데이터 품질에 중점을 둔 훈련 방식으로 개발되었는데, 웹 콘텐츠나 코드와 같은 유기적 데이터 소스를 주로 사용하는 대부분의 언어 모델들과 달리 훈련 과정 전반에 걸쳐 합성 데이터를 전략적으로 통합했다는 점이 특징적입니다. 특히 이전 Phi 계열의 모델들이 주로 GPT-4와 같은 교사 모델의 능력을 증류하는 데 중점을 두었던 것과 달리, phi-4는 STEM 중심의 질의응답 능력에서 교사 모델을 상당히 뛰어넘는 성과를 보여줌으로써 데이터 생성과 사후 훈련 기법이 단순한 증류를 넘어선다는 것을 입증했으며, phi-3의 아키텍처를 최소한으로만 변경했음에도 개선된 데이터, 훈련 커리큘럼, 그리고 사후 훈련 방식의 혁신을 통해 특히 추론 중심의 벤치마크에서 모델 크기 대비 강력한 성능을 달성했습니다.
APOLLO: SGD-like Memory, AdamW-level Performance
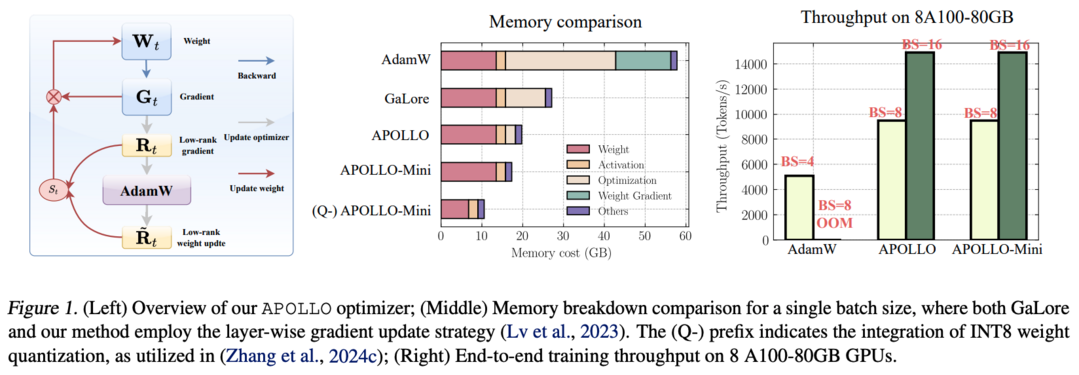
대규모 언어 모델(LLMs)은 특히 널리 사용되는 AdamW 옵티마이저를 사용할 때 훈련 과정에서 많은 메모리를 필요로 하는 것으로 알려져 있어, 더 많거나 고성능 GPU를 사용하거나 배치 크기를 줄여야 하는 문제가 있었는데, 이를 해결하기 위해 APOLLO라는 새로운 접근 방식이 제안되었습니다. 이 방식은 AdamW의 학습률 적응 규칙이 구조화된 학습률 업데이트로 효과적으로 단순화될 수 있다는 통찰을 바탕으로, 순수 무작위 투영을 기반으로 한 보조 저차원 옵티마이저 상태를 사용하여 학습률 스케일링을 근사화합니다. 특히 랭크-1 변형인 APOLLO-Mini는 SGD 수준의 메모리 비용으로도 AdamW보다 우수한 사전 훈련 성능을 달성했으며, 광범위한 실험을 통해 APOLLO 시리즈가 AdamW의 최적화 상태를 거의 제거하면서도 동등하거나 더 나은 성능을 보여주어, 8xA100-80GB 설정에서 4배 큰 배치 크기를 지원함으로써 AdamW 대비 3배의 처리량 향상, 시스템 수준 최적화 없이 A100-80GB GPU에서 LLaMA-13B의 사전 훈련 가능, 가중치 양자화를 통해 12GB 미만의 메모리로 단일 GPU에서 LLaMA-7B 사전 훈련 가능 등의 중요한 시스템 수준 이점을 제공한다는 것이 입증되었습니다.
Training Large Language Models to Reason in a Continuous Latent Space
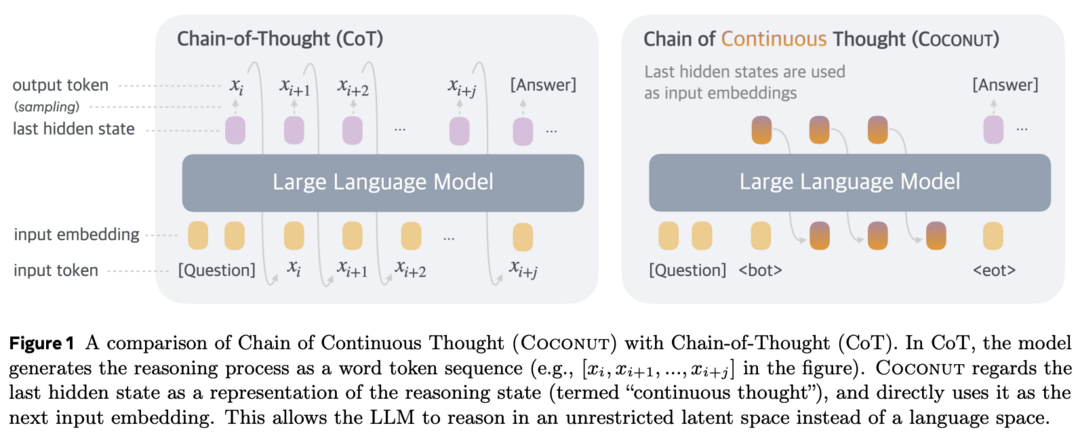
대규모 언어 모델(LLMs)이 복잡한 추론 문제를 해결하기 위해 일반적으로 사고의 연쇄(CoT)를 사용하여 '언어 공간'에서만 추론하는 것의 한계를 극복하고자, 연구진들은 Coconut(Chain of Continuous Thought)이라는 새로운 패러다임을 제안했습니다. 이들은 LLM의 마지막 은닉 상태를 추론 상태('연속적 사고')의 표현으로 활용하여, 이를 단어 토큰으로 디코딩하는 대신 연속 공간에서 직접 후속 입력 임베딩으로 LLM에 피드백하는 방식을 도입했는데, 실험을 통해 Coconut이 여러 추론 작업에서 LLM을 효과적으로 보강할 수 있음이 입증되었습니다. 특히 이 새로운 잠재 추론 패러다임은 연속적 사고가 여러 대안적 다음 추론 단계를 인코딩할 수 있어, CoT처럼 단일 결정적 경로를 조기에 선택하는 대신 너비 우선 탐색(BFS)을 수행할 수 있게 하는 고급 추론 패턴을 보여주었으며, 계획 과정에서 상당한 백트래킹이 필요한 특정 논리 추론 작업에서 더 적은 사고 토큰으로도 CoT보다 우수한 성능을 달성하여 잠재 추론의 가능성과 향후 연구를 위한 귀중한 통찰을 제공했습니다.
ProcessBench: Identifying Process Errors in Mathematical Reasoning
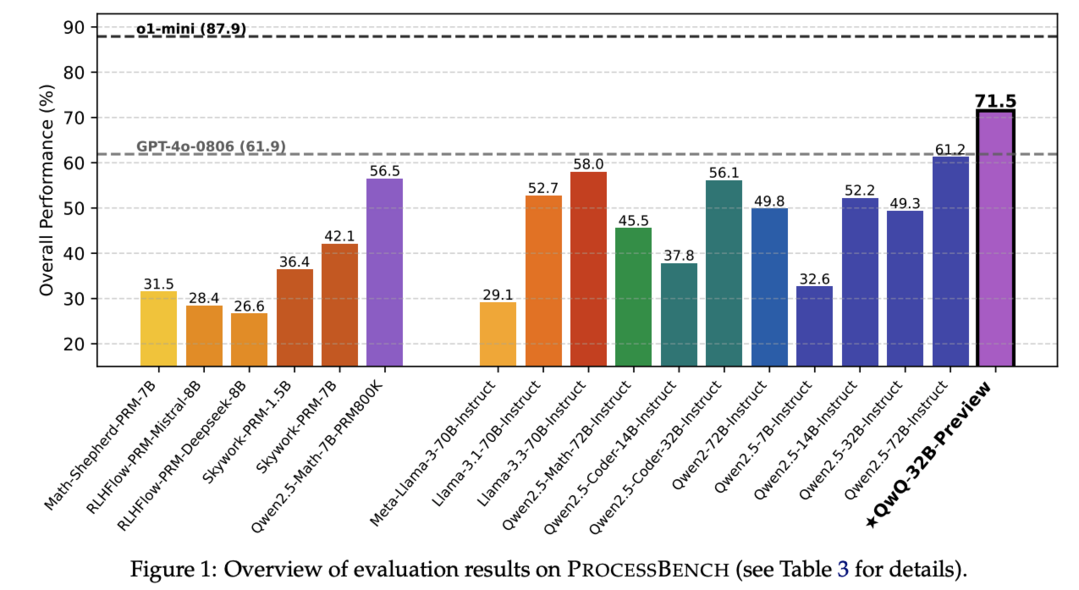
언어 모델이 수학 문제를 해결할 때 자주 실수를 하기 때문에 추론 과정에서의 오류를 자동으로 식별하는 것이 모델의 확장 가능한 감독을 위해 점점 더 중요해지고 있는 상황에서, 연구진들은 수학적 추론에서 잘못된 단계를 식별하는 능력을 측정하기 위한 ProcessBench를 소개했습니다. 이는 주로 경쟁 및 올림피아드 수준의 수학 문제에 초점을 맞춘 3,400개의 테스트 케이스로 구성되어 있으며, 각 테스트 케이스는 전문가가 오류 위치를 주석으로 표시한 단계별 해결책을 포함하고 있어 모델이 오류가 포함된 가장 이른 단계를 식별하거나 모든 단계가 정확하다고 결론 내려야 합니다. 프로세스 보상 모델(PRMs)과 일반 언어 모델을 단계별로 해결책을 비평하도록 프롬프트하는 비평 모델 두 가지 유형에 대한 광범위한 평가를 통해, 기존 PRMs가 GSM8K와 MATH를 넘어선 더 어려운 수학 문제로의 일반화에 실패하여 비평 모델들과 PRM800K 데이터셋에서 직접적으로 미세 조정된 자체 훈련된 PRM보다 성능이 떨어진다는 점과, 오픈소스 모델인 QwQ-32B-Preview가 여전히 추론 특화 모델인 o1-mini에는 미치지 못하지만 GPT-4와 경쟁력 있는 비평 능력을 보여주었다는 점이 주요한 발견으로 나타났습니다.
Evaluating and Aligning CodeLLMs on Human Preference
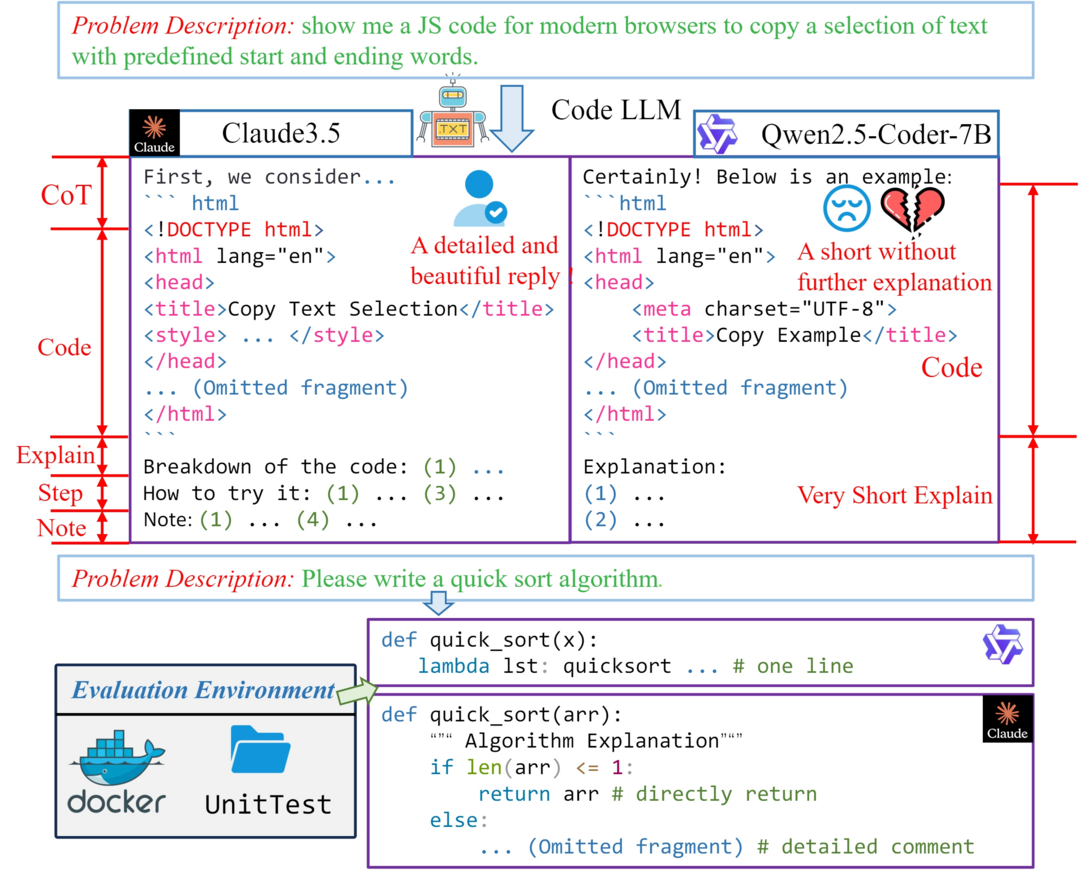
코드 대규모 언어 모델(codeLLMs)이 코드 생성에서 큰 진전을 이루었지만, 기존의 코드 관련 벤치마크들이 주로 프로그래밍 연습과 해당 테스트 케이스로 구성되어 코드 LLMs의 성능과 기능을 평가하는 데 중점을 두고 있어, 실제 응용 시나리오에서의 쿼리 샘플링과 인간의 선호도를 만족시키는 모델 생성 응답의 중요성이 간과되어 왔다는 점에 주목한 연구가 진행되었습니다. 연구진들은 모델이 생성한 응답과 인간의 선호도 간의 격차를 해소하기 위해 실제 코딩 작업의 복잡성과 다양성을 모방하는 엄격한 인간 큐레이션 벤치마크인 CodeArena를 제시했는데, 이는 사용자 쿼리에서 신중하게 선별된 40개 카테고리와 44개 프로그래밍 언어에 걸친 397개의 고품질 샘플을 포함하고 있습니다. 또한 대규모 합성 명령어 미세 조정의 효과를 검증하기 위해 웹사이트의 명령어를 확장한 약 200억 토큰 규모의 다양한 합성 명령어 말뭉치 SynCode-Instruct를 제안했으며, 순수하게 합성 명령어 데이터로만 훈련된 Qwen2.5-SynCoder가 오픈소스 코드 LLMs 중 최고 수준의 성능을 달성할 수 있음을 보여주었고, 실행 기반 벤치마크와 CodeArena 간의 성능 차이를 발견하여 인간의 선호도 조정의 중요성을 강조했습니다.(Project: https://codearenaeval.github.io)
Unraveling the Complexity of Memory in RL Agents: an Approach for Classification and Evaluation
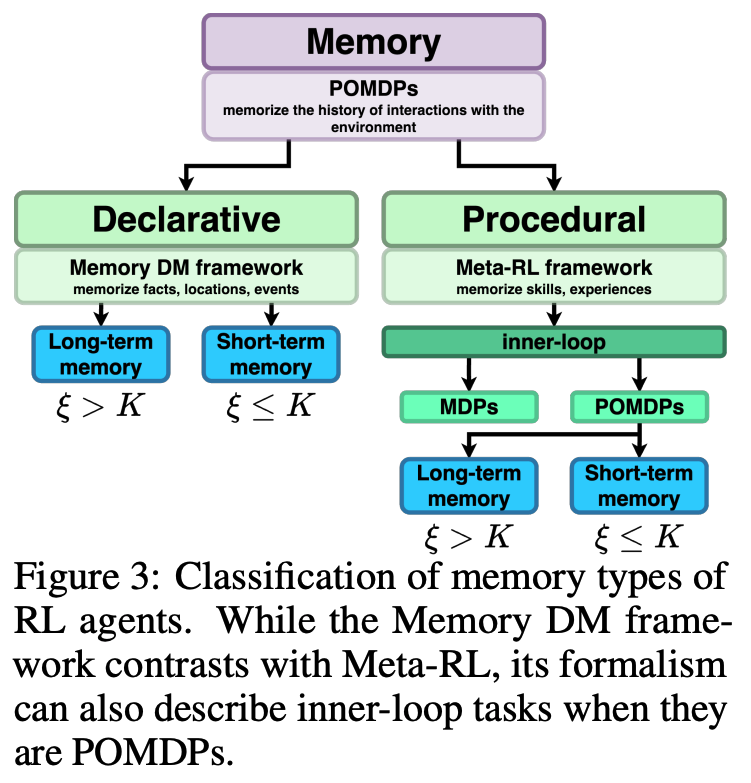
강화학습(RL) 영역에서 에이전트에 메모리를 통합하는 것이 과거 정보의 활용, 새로운 환경에 대한 적응, 향상된 샘플 효율성이 요구되는 많은 작업에서 필수적이지만, '메모리'라는 용어가 광범위한 개념을 포함하고 있고 에이전트의 메모리를 검증하는 통일된 방법론이 부족하여 에이전트의 메모리 능력에 대한 잘못된 판단과 다른 메모리 강화 에이전트들과의 객관적인 비교가 어려웠던 상황에서, 연구진들은 인지과학에서 영감을 받아 장기 대 단기 메모리, 선언적 대 절차적 메모리와 같은 에이전트 메모리 유형에 대한 실용적이고 정확한 정의를 제공하여 RL에서의 메모리 개념을 체계화했습니다. 이러한 정의를 바탕으로 다양한 에이전트 메모리 클래스를 분류하고, RL 에이전트의 메모리 능력을 평가하기 위한 견고한 실험 방법론을 제안하고 평가를 표준화했으며, 다양한 RL 에이전트들을 대상으로 한 실험을 통해 서로 다른 유형의 에이전트 메모리를 평가할 때 제안된 방법론을 준수하는 것의 중요성과 이를 위반했을 때의 결과를 실증적으로 입증했습니다.
[저작권자ⓒ META-X. 무단전재-재배포 금지]