2025년 2주차에 공개된 주목할만한 인공지능(AI) 분야의 논문들을 소개합니다. 각 논문별 간단한 요약을 원하시는 분들은 아래의 TL;DR을 참고해주세요.
TL;DR
로보틱스/물리적 AI 분야에서는 로봇 조작을 위한 embodied future space 생성 프레임워크인 EnerVerse가 제안되었고, 물리적 AI 시스템 개발을 위한 Cosmos World Foundation Model Platform이 소개되었습니다. 이 연구들은 실제 물리 세계에서 AI 시스템의 성능을 향상시키는 것에 초점을 맞추고 있습니다.
컴퓨터 비전/생성 모델 분야에서는 실제 비디오의 해상도 향상을 위한 시공간 증강 기법 STAR가 제시되었으며, 단일 비전 토큰으로 효율적인 이미지/비디오 처리가 가능한 LLaVA-Mini가 개발되었습니다. 또한 GAN 아키텍처를 현대화한 새로운 베이스라인 연구 "The GAN is dead; long live the GAN!"이 발표되었습니다.
LLM 추론 및 최적화 영역에서는 인간 선호도에 맞춘 REINFORCE++, 검색 기능이 강화된 Search-o1이 제안되었습니다. 또한 System 2 추론을 위한 Meta Chain-of-Thought 프레임워크가 개발되었고, LLM 에이전트를 연구 보조자로 활용하는 Agent Laboratory가 소개되었습니다. 이러한 연구들은 LLM의 기본적인 추론 능력과 활용성을 향상시키는데 기여했습니다.
AI 응용 시스템 분야에서는 작은 규모 LLM의 수학적 추론 능력을 향상시킨 rStar-Math와 멀티모달 수학에서의 Chain-of-thought 추론을 검증하는 URSA가 개발되었습니다. 이러한 연구들은 AI 시스템의 실제 응용 사례를 보여주며, 특히 수학적 추론 능력 향상에 중점을 두었습니다.
로보틱스/물리적 AI 분야
EnerVerse: Envisioning Embodied Future Space for Robotics Manipulation
로봇 조작을 위한 포괄적인 embodied future space 생성 프레임워크를 제안하여 로봇의 예측 및 조작 능력을 향상시킴
EnerVerse는 로봇 조작 작업을 위해 특별히 설계된 포괄적인 embodied future space 생성 프레임워크입니다. 이 프레임워크는 내부 청크 공간 모델링을 위해 컨볼루션과 양방향 어텐션 메커니즘을 통합하여 저수준의 일관성과 연속성을 보장합니다. 또한 비디오 데이터의 중복성을 고려하여 희소 메모리 컨텍스트와 청크 단위 단방향 생성 패러다임을 제안하여 무한히 긴 시퀀스 생성을 가능하게 합니다. 로봇의 능력을 더욱 향상시키기 위해 Free Anchor View (FAV) 공간을 도입하여 유연한 관찰 및 분석 관점을 제공합니다. 또한, 다중 카메라 관찰 획득의 비용과 노동 집약성 문제를 해결하기 위해 생성 모델과 4D Gaussian Splatting (4DGS)을 통합한 데이터 엔진 파이프라인을 제시합니다. 이 파이프라인은 데이터의 품질과 다양성을 반복적으로 향상시켜 sim-to-real 격차를 효과적으로 줄입니다. 실험 결과, embodied future space 생성 사전 학습이 정책의 예측 능력을 크게 향상시켜 특히 장거리 로봇 조작 작업에서 전반적인 성능 향상을 가져옴을 보여줍니다.
Cosmos World Foundation Model Platform for Physical AI
Physical AI 개발을 위한 월드 모델 플랫폼을 소개하여 다양한 물리적 AI 시스템 구축을 지
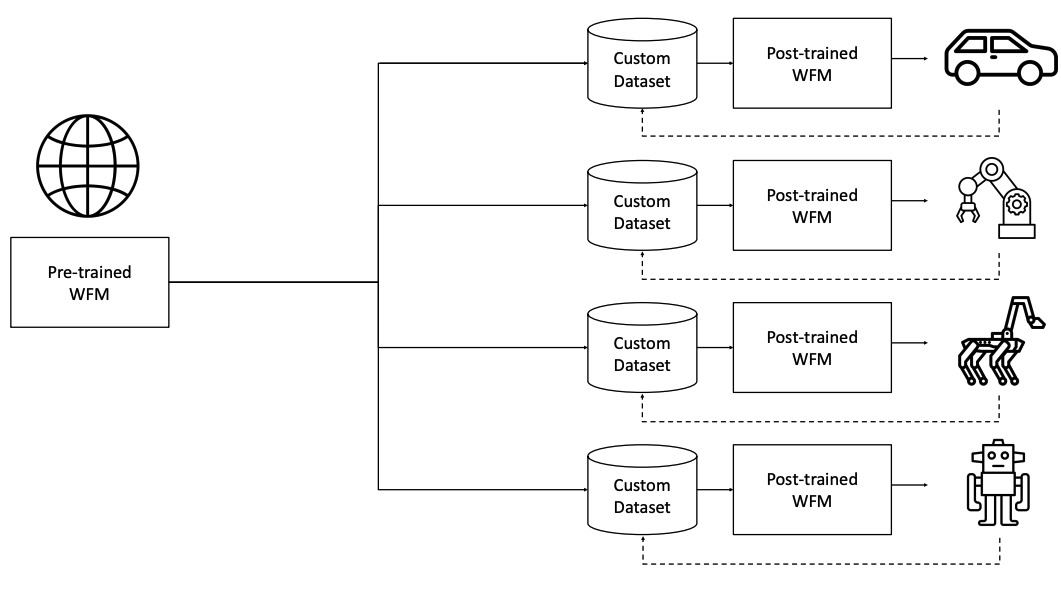
이 논문은 Physical AI 개발을 위한 Cosmos World Foundation Model Platform을 소개합니다. Physical AI는 디지털 환경에서 먼저 훈련되어야 하며, 이를 위해 AI 자체의 디지털 트윈인 정책 모델과 세계의 디지털 트윈인 월드 모델이 필요합니다. 이 플랫폼은 개발자들이 자신들의 Physical AI 설정에 맞는 맞춤형 월드 모델을 구축할 수 있도록 지원합니다. 논문에서는 월드 파운데이션 모델을 다양한 하위 응용 프로그램에 맞게 미세 조정할 수 있는 범용 월드 모델로 제시합니다. 이 플랫폼은 비디오 큐레이션 파이프라인, 사전 훈련된 월드 파운데이션 모델, 사전 훈련된 모델의 후처리 예시, 그리고 비디오 토크나이저를 포함합니다. 저자들은 Physical AI 개발자들이 사회의 가장 중요한 문제들을 해결할 수 있도록 이 플랫폼을 오픈 소스로 공개합니다.
컴퓨터 비전/생성 모델 분야
STAR: Spatial-Temporal Augmentation with Text-to-Video Models for Real-World Video Super-Resolution
텍스트-투-비디오 모델을 활용한 실제 비디오 초해상도 기법을 제안하여 시공간적 품질을 향상시킴
이 논문은 실제 세계의 비디오 초해상도 문제를 해결하기 위해 이미지 확산 모델을 적용한 새로운 접근 방식인 STAR를 소개합니다. STAR는 텍스트-투-비디오(T2V) 모델을 활용하여 시공간적 품질을 향상시키는데, 이는 기존 GAN 기반 방법들의 과도한 평활화 문제를 해결하고 시간적 일관성을 개선하는 것을 목표로 합니다. 이 방법은 Local Information Enhancement Module (LIEM)을 도입하여 로컬 디테일을 강화하고 열화 아티팩트를 완화하며, Dynamic Frequency (DF) Loss를 제안하여 모델의 충실도를 높입니다. 실험 결과, STAR는 합성 및 실제 데이터셋에서 최신 방법들을 능가하는 성능을 보여주었습니다. 이 접근 방식은 복잡한 실제 시나리오에서 발생하는 아티팩트 문제와 강력한 T2V 모델의 과도한 생성 능력으로 인한 충실도 저하 문제를 해결하는 데 중점을 두고 있습니다.
LLaVA-Mini: Efficient Image and Video Large Multimodal Models with One Vision Token
단일 비전 토큰으로 효율적인 이미지 및 비디오 처리가 가능한 대규모 멀티모달 모델을 개발
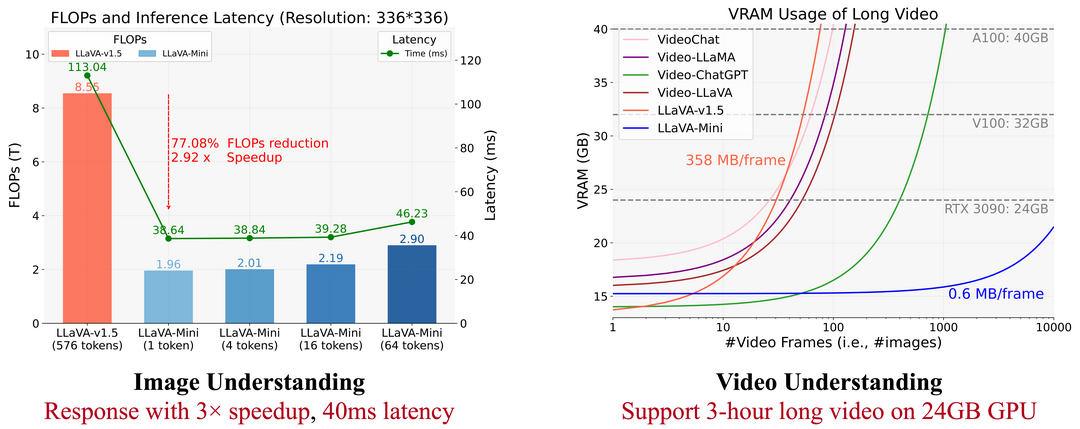
이 논문은 실시간 대규모 멀티모달 모델(LMMs)의 효율성 향상에 초점을 맞추고 있습니다. 연구진은 LLaVA-Mini라는 새로운 효율적인 LMM을 소개하며, 이 모델은 최소한의 비전 토큰을 사용합니다. LLaVA-Mini는 모달리티 사전 융합 기술을 도입하여 시각 정보를 텍스트 토큰에 미리 융합함으로써 LLM 백본에 공급되는 비전 토큰을 단 하나로 극도로 압축할 수 있게 합니다. 이 모델은 이미지, 고해상도 이미지, 비디오를 효율적으로 이해할 수 있는 통합된 대규모 멀티모달 모델입니다. 11개의 이미지 기반 및 7개의 비디오 기반 벤치마크에서의 실험 결과, LLaVA-Mini는 576개 대신 단 1개의 비전 토큰만으로 LLaVA-v1.5의 성능을 뛰어넘었습니다. 효율성 분석 결과, LLaVA-Mini는 FLOPs를 77% 감소시키고, 40밀리초 내의 저지연 응답을 제공하며, 24GB 메모리의 GPU 하드웨어에서 10,000프레임 이상의 비디오를 처리할 수 있음을 보여줍니다.
The GAN is dead; long live the GAN! A Modern GAN Baseline
GAN 아키텍처를 현대화한 새로운 베이스라인 R3GAN을 제시하여 기존 모델들의 성능을 뛰어넘음
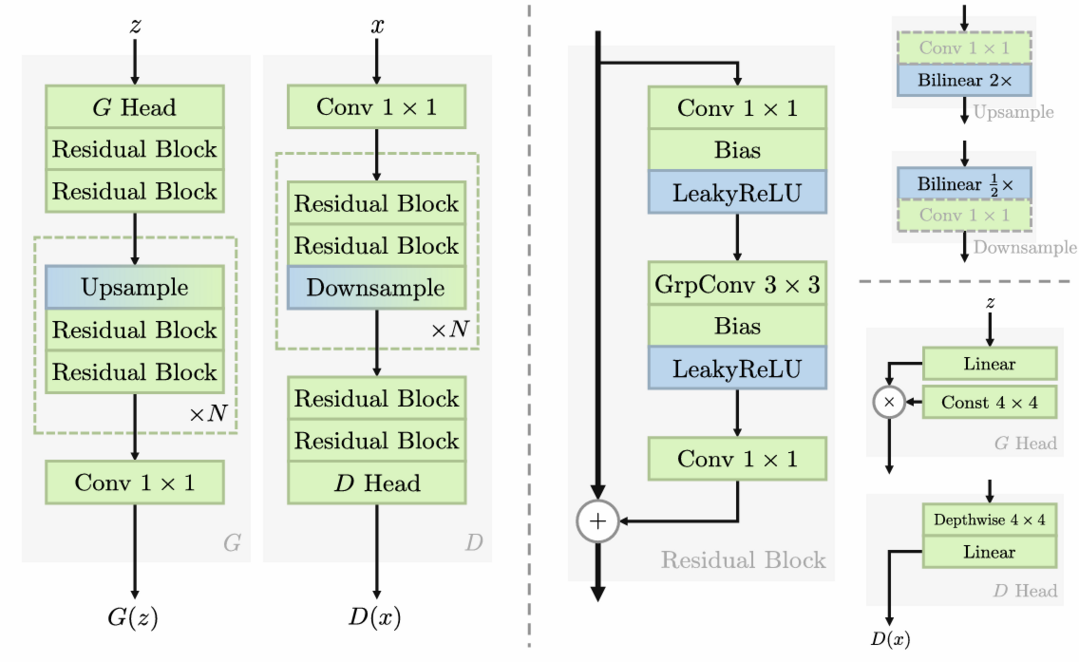
이 논문은 GAN(Generative Adversarial Networks)의 훈련이 어렵다는 일반적인 인식에 대해 의문을 제기하고, 더 체계적인 방식으로 현대적인 GAN 베이스라인을 구축하는 내용을 다루고 있습니다. 연구진은 먼저 모드 드롭핑과 비수렴 문제를 해결하는 잘 정의된 정규화된 relativistic GAN 손실 함수를 도출했습니다. 이 손실 함수는 수학적으로 분석되어 로컬 수렴 보장을 제공하며, 이를 통해 기존의 임시방편적인 기법들을 제거하고 구식 백본을 현대적인 아키텍처로 대체할 수 있게 되었습니다. StyleGAN2를 예로 들어, 연구진은 단순화와 현대화 과정을 거쳐 새로운 미니멀리스트 베이스라인인 R3GAN을 개발했습니다. 이 간단한 접근법은 FFHQ, ImageNet, CIFAR, Stacked MNIST 데이터셋에서 StyleGAN2를 능가하며, 최신 GAN 및 diffusion 모델들과 비교해도 우수한 성능을 보여주었습니다.
LLM 추론 및 최적화 영역
REINFORCE++: A Simple and Efficient Approach for Aligning Large Language Models
인간 선호도에 맞춘 간단하고 효율적인 대규모 언어 모델 정렬 접근법을 제안
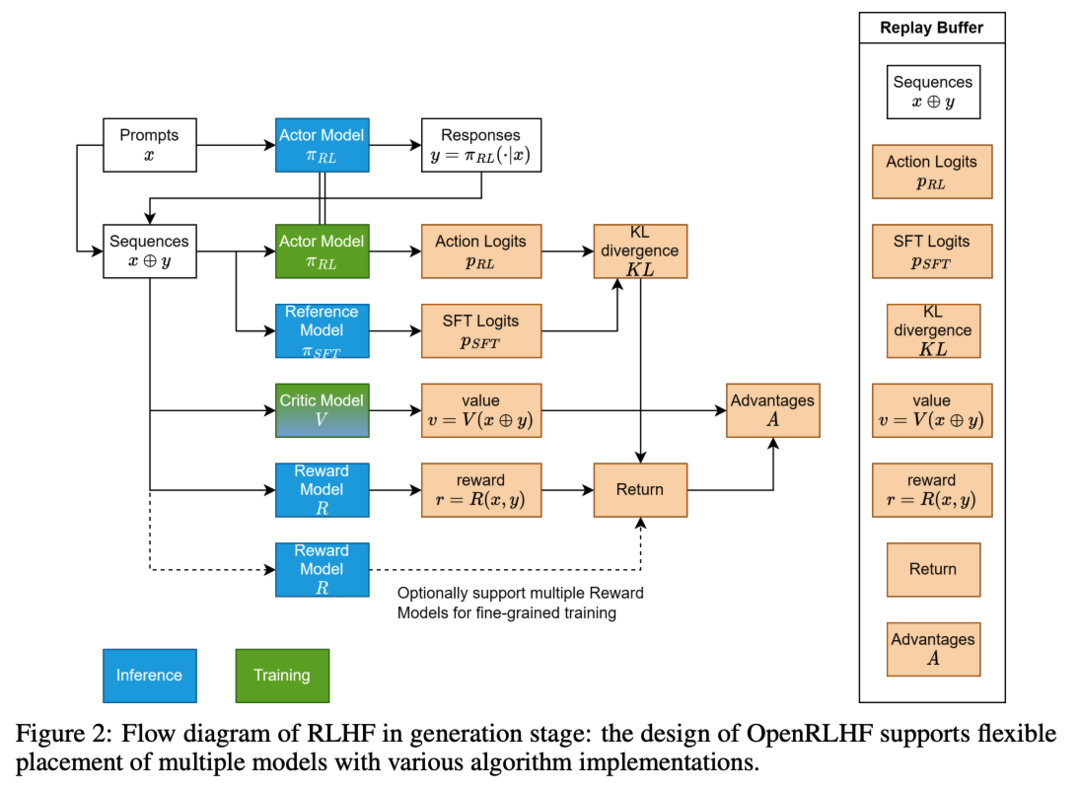
인간의 피드백을 통한 강화학습(RLHF)은 대규모 언어 모델을 인간의 선호도에 맞추는 중요한 접근 방식으로 부상했으며, PPO, DPO, RLOO, ReMax, GRPO 등의 방법을 통해 빠르게 진화하고 있습니다. 이 논문에서는 고전적인 REINFORCE 알고리즘을 개선한 REINFORCE++를 소개합니다. 이 방법은 PPO의 주요 최적화 기술을 통합하면서도 critic 네트워크의 필요성을 제거했습니다. REINFORCE++는 단순성, 향상된 훈련 안정성, 그리고 계산 오버헤드 감소라는 세 가지 주요 목표를 달성합니다. 광범위한 실증적 평가를 통해, REINFORCE++가 GRPO보다 우수한 안정성을 보이며 PPO와 비슷한 성능을 유지하면서도 더 높은 계산 효율성을 달성한다는 것을 입증했습니다.
Search-o1: Agentic Search-Enhanced Large Reasoning Models
에이전트 기반 검색 워크플로우를 통해 대규모 추론 모델의 장기적 단계별 추론 능력을 향상시킴
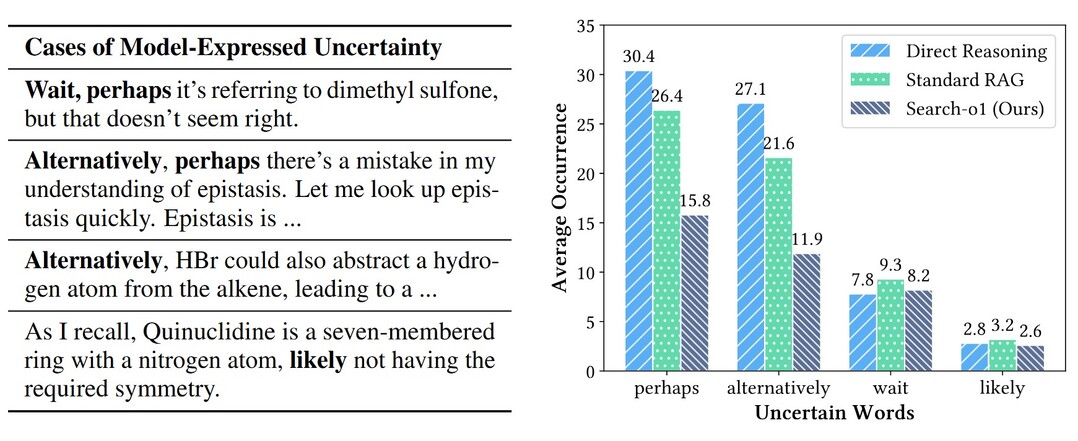
이 논문은 OpenAI-o1과 같은 대규모 추론 모델(LRMs)의 장기적 단계별 추론 능력을 개선하기 위한 'Search-o1' 프레임워크를 소개합니다. LRMs가 지식 부족으로 인한 불확실성과 오류에 직면할 때, Search-o1은 에이전트 기반 검색 워크플로우를 통해 외부 지식을 동적으로 검색하고 활용합니다. 또한 검색된 문서의 상세한 분석을 위해 'Reason-in-Documents' 모듈을 도입하여 추론 과정의 일관성을 유지합니다. 이 접근 방식은 과학, 수학, 코딩 분야의 복잡한 추론 작업과 여러 오픈 도메인 QA 벤치마크에서 뛰어난 성능을 보여주었습니다. Search-o1은 LRMs의 신뢰성과 적용 가능성을 높여, 복잡한 추론 작업에서 더 안정적이고 다재다능한 지능형 시스템의 발전을 위한 길을 열어줍니다.
Towards System 2 Reasoning in LLMs: Learning How to Think With Meta Chain-of-Though
대규모 언어 모델의 System 2 추론 능력 향상을 위한 새로운 프레임워크를 제안
[Paper]
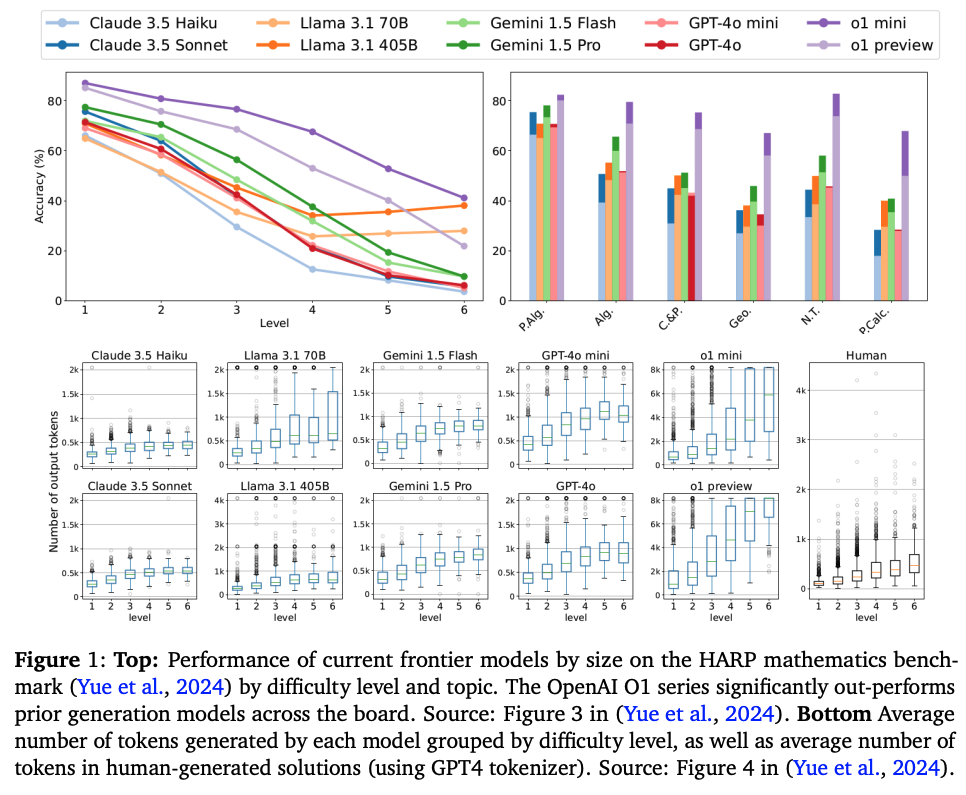
이 논문은 기존의 Chain-of-Thought (CoT) 방식을 확장한 새로운 프레임워크인 Meta Chain-of-Thought (Meta-CoT)를 제안합니다. Meta-CoT는 특정 CoT에 도달하는 데 필요한 기저 추론 과정을 명시적으로 모델링합니다. 저자들은 최신 모델들이 in-context search와 일치하는 행동을 보인다는 실증적 증거를 제시하고, 프로세스 감독, 합성 데이터 생성, 검색 알고리즘 등을 통해 Meta-CoT를 생성하는 방법을 탐구합니다. 또한 선형화된 검색 추적과 instruction tuning, 그리고 사후 강화학습을 포함하는 Meta-CoT 생성 모델 훈련을 위한 구체적인 파이프라인을 설명합니다. 마지막으로 scaling laws, verifier 역할, 새로운 추론 알고리즘 발견 가능성 등의 향후 연구 과제를 논의합니다. 이 연구는 대규모 언어 모델(LLM)에서 Meta-CoT를 구현하기 위한 이론적, 실용적 로드맵을 제공하여 인공지능의 더 강력하고 인간다운 추론 능력 발전에 기여합니다.
Agent Laboratory: Using LLM Agents as Research Assistants
LLM 에이전트를 활용한 자율적 연구 보조 시스템을 개발하여 과학적 발견 과정을 가속화

Agent Laboratory는 과학적 발견 과정을 가속화하고 연구 비용을 절감하며 품질을 향상시키기 위해 개발된 자율적인 LLM 기반 프레임워크입니다. 이 시스템은 인간이 제공한 연구 아이디어를 바탕으로 문헌 검토, 실험, 보고서 작성의 세 단계를 거쳐 전체 연구 과정을 완료합니다. 사용자는 각 단계에서 피드백과 지침을 제공할 수 있으며, 최종 결과물로 코드 저장소와 연구 보고서를 생성합니다. 다양한 최신 LLM을 사용하여 테스트한 결과, o1-preview가 가장 우수한 연구 결과를 생성했으며, 생성된 머신 러닝 코드는 기존 방법들과 비교해 최고 수준의 성능을 달성했습니다. 또한 각 단계에서의 인간의 피드백이 전반적인 연구 품질을 크게 향상시키는 것으로 나타났습니다. Agent Laboratory는 기존의 자율 연구 방법들에 비해 연구 비용을 84% 절감하는 효과를 보였습니다. 이 프레임워크를 통해 연구자들이 단순 코딩이나 글쓰기보다는 창의적인 아이디어 발상에 더 많은 노력을 기울일 수 있게 되어 과학적 발견을 가속화할 수 있을 것으로 기대됩니다.
AI 응용 시스템 분야
rStar-Math: Small LLMs Can Master Math Reasoning with Self-Evolved Deep Thinking
작은 언어 모델의 수학적 추론 능력을 대폭 향상시키는 자기 진화 방식의 프레임워크를 제안
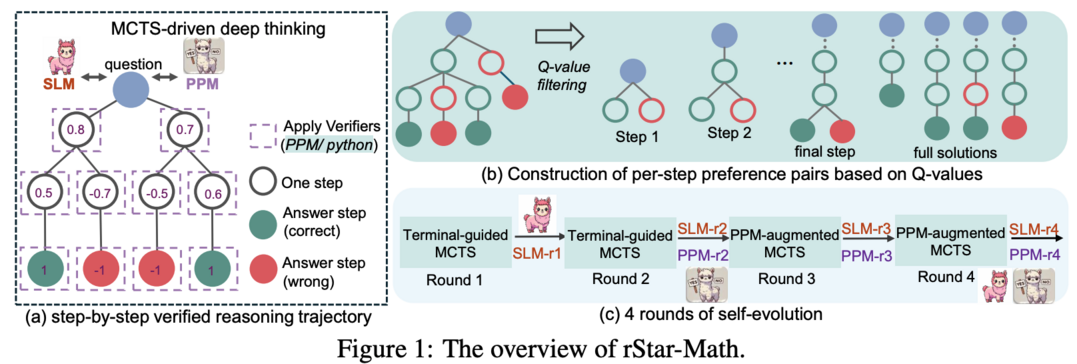
rStar-Math는 작은 언어 모델(SLM)이 OpenAI의 o1과 견줄 만한, 심지어 더 뛰어난 수학적 추론 능력을 보일 수 있음을 증명합니다. 이는 상위 모델로부터의 지식 증류 없이 달성되었습니다. rStar-Math는 몬테카를로 트리 탐색(MCTS)을 통한 "깊은 사고"를 활용하여 이를 실현합니다. 여기서 수학 정책 SLM은 SLM 기반 프로세스 보상 모델의 안내를 받아 테스트 시 탐색을 수행합니다. 두 SLM을 훈련시키는 과정의 도전 과제를 해결하기 위해 rStar-Math는 세 가지 혁신을 도입했습니다: (1) 코드 증강 CoT 데이터 합성 방법, (2) 새로운 프로세스 보상 모델 훈련 방법, (3) 정책 SLM과 PPM을 처음부터 구축하고 반복적으로 진화시키는 자기 진화 레시피. 747k개의 수학 문제에 대한 수백만 개의 합성 솔루션을 통한 4라운드의 자기 진화를 거쳐, rStar-Math는 SLM의 수학적 추론 능력을 최첨단 수준으로 끌어올렸습니다. MATH 벤치마크에서 Qwen2.5-Math-7B를 58.8%에서 90.0%로, Phi3-mini-3.8B를 41.4%에서 86.4%로 향상시켜 o1-preview를 각각 4.5%와 0.9% 앞섰습니다. 미국 수학 올림피아드(AIME)에서는 평균 53.3%(15문제 중 8문제)를 해결하여 상위 20% 수준의 우수한 고등학생 수학 실력을 보여주었습니다.
URSA: Understanding and Verifying Chain-of-thought Reasoning in Multimodal Mathematics
멀티모달 수학 문제에서 Chain-of-thought 추론을 이해하고 검증하는 새로운 접근 방식을 개발
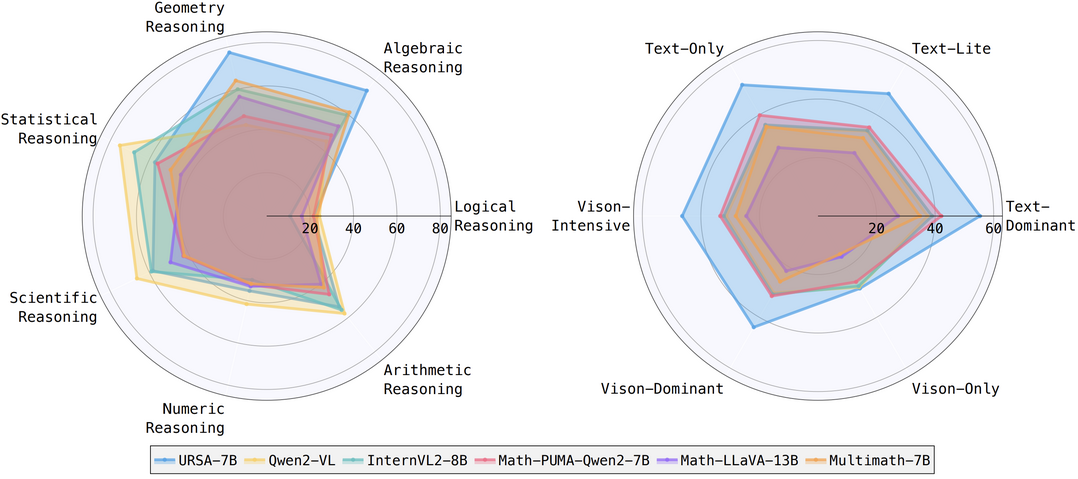
이 논문은 대규모 언어 모델(LLM)의 수학적 추론 능력을 향상시키기 위한 새로운 접근 방식을 제안합니다. 연구진은 Chain-of-thought (CoT) 추론을 멀티모달 수학 문제에 적용하기 위해 세 가지 모듈로 구성된 전략을 개발했습니다. 이를 통해 MMathCoT-1M이라는 고품질 CoT 추론 데이터셋을 생성했고, URSA-7B 모델을 훈련시켜 여러 멀티모달 수학 벤치마크에서 최고 성능을 달성했습니다. 또한, 테스트 시 성능 향상을 위해 DualMath-1.1M이라는 자동 생성된 프로세스 주석 데이터셋을 도입했습니다. 이를 바탕으로 훈련된 URSA-RM-7B 모델은 검증자 역할을 수행하며, URSA-7B의 테스트 시 성능을 효과적으로 개선하고 뛰어난 일반화 능력을 보여주었습니다. 이 연구는 LLM의 수학적 추론 능력을 크게 향상시키는 동시에, 멀티모달 환경에서의 CoT 추론의 가능성을 확장했습니다.
[저작권자ⓒ META-X. 무단전재-재배포 금지]