지능형 응용, 과학·공학 자동화 에이전트·창의적 콘텐츠 생성·데이터 중심 시스템 구축
TL;DR
대규모 언어/멀티모달 모델 최적화 및 효율화 분야에서는, 모델 중심에서 벗어나 입력 데이터 자체를 압축하는 'Data-Centric Compression' 으로 AI 효율성의 패러다임을 전환하고 있으며, 대형 모델의 정교한 능력을 소형 모델로 효과적으로 이전하는 'Distilling LLM Agent' 기술이 발전하고 있다. 또한, 극히 낮은 정밀도 연산을 활용하는 'Native FP4 Training' 을 통해 LLM의 학습 효율을 극대화하는 한편, 필요에 따라 지능적으로 연산 경로를 조절하여 추론 비용을 절감하는 'Token Routing' 과 같은 혁신적인 접근법들이 연구되고 있다.
AI의 추론 능력 심층 분석 및 강화 분야에서는, 강화학습 과정에서 발생하는 'Entropy Mechanism' 을 규명하여 언어 모델의 꾸준한 탐색과 성능 향상을 지원하고, 멀티모달 모델의 'Logical Reasoning' 능력을 종합적으로 평가하기 위한 MME-Reasoning과 같은 새로운 벤치마크가 제시되고 있다. 더 나아가, 강화학습을 통해 긴 문맥 정보를 효과적으로 처리하는 'Long-Context Reasoning' 모델(예: QwenLong-L1)을 개발하며, 모델이 명시적 지시를 무시하고 기존의 익숙한 패턴으로 회귀하려는 'Instruction Overriding' 현상을 진단하고 해결책을 모색하는 등 추론 과정의 깊이 있는 이해를 추구하고 있다.
AI 에이전트, 응용 시스템 및 데이터 기반 혁신 분야에서는, 특정 목표에 맞춰 의미론적 표현을 학습하는 'Tabular Model' (예: TabSTAR)과 같이 특정 데이터 유형에 최적화된 파운데이션 모델이 개발되고 있으며, 실제 과학 연구 환경에서 멀티모달 'Autonomous Agents' 의 복잡한 문제 해결 능력을 평가하는 ScienceBoard와 같은 플랫폼이 구축되고 있다. 또한, 과학 논문으로부터 자동으로 학술 포스터를 생성하는 'Poster Automation' 기술(예: Paper2Poster), 실제 GitHub 데이터 기반으로 'Software Engineering Agents' 의 작업을 자동화하고 평가하는 SWE-rebench, 그리고 공개 텍스트-이미지 데이터를 고품질 학습 데이터인 'Generative Gold' 로 변환하는 Alchemist와 같은 데이터 중심의 혁신이 두드러진다. 이미지 스타일화 분야에서는 다양한 스타일에 걸쳐 시각적 일관성을 유지하는 'OmniConsistency' 기술 등을 통해 응용 범위를 넓히고 있다.
대규모 언어/멀티모달 모델 최적화 및 효율화 분야
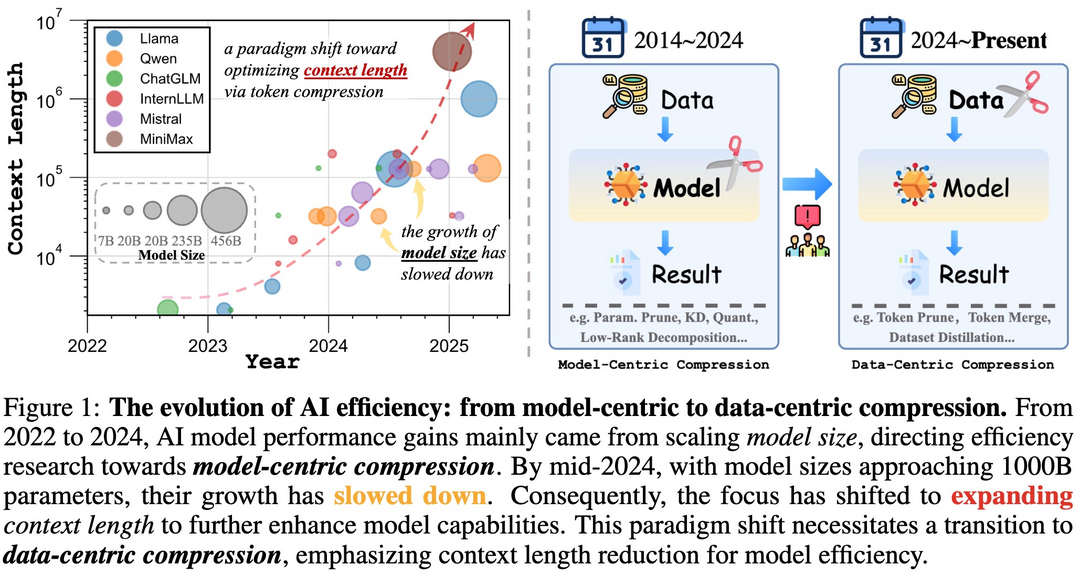
Shifting AI Efficiency From Model-Centric to Data-Centric Compression
https://arxiv.org/abs/2505.19147
대규모 언어 모델(LLM) 및 멀티모달 LLM(MLLM)은 그동안 모델의 파라미터 수를 늘려 성능을 높여왔다. 하지만 하드웨어 한계에 다다르면서, 이제는 긴 토큰 시퀀스에 대한 연산 비용(특히 셀프 어텐션의 제곱 비용)이 주요 병목 지점이 되었다. 이는 초장문 텍스트, 고해상도 이미지, 긴 비디오 등으로 인해 더욱 심화되고 있다. 이 논문은 AI 효율성 연구의 초점이 모델 중심 압축에서 데이터 중심 압축, 즉 토큰 압축으로 이동하고 있다고 주장한다. 토큰 압축은 모델 훈련 또는 추론 시 토큰 수를 줄여 AI 효율성을 높이는 새로운 접근 방식이며, 긴 컨텍스트로 인한 오버헤드를 해결하는 중요한 패러다임 전환임을 강조한다. 또한 토큰 압축 연구의 현황, 이점, 당면 과제 및 미래 방향을 제시한다.
Distilling LLM Agent into Small Models with Retrieval and Code Tools
https://arxiv.org/abs/2505.17612
대규모 언어 모델(LLM)은 복잡한 추론 작업에 뛰어나지만 계산 비용이 많이 들어 실제 배포가 제한적이다. 이를 해결하기 위해 최근 연구들은 교사 LLM의 연쇄적 사고(CoT) 추적을 사용하여 추론 능력을 소형 언어 모델(sLM)로 증류하는 데 초점을 맞추었다. 그러나 이 접근 방식은 희귀한 사실적 지식이나 정밀한 계산이 필요한 시나리오에서 sLM이 제한된 능력으로 인해 환각을 일으키는 문제에 직면한다. 이 논문은 추론 능력뿐만 아니라 LLM 기반 에이전트의 전체 작업 해결 행동을 검색 및 코드 도구를 갖춘 sLM으로 이전하는 에이전트 증류(Agent Distillation) 프레임워크를 제안한다. (1) 교사가 생성한 궤적의 품질을 향상시키기 위한 "첫 생각 접두사(first-thought prefix)" 프롬프팅 방법과 (2) 소형 에이전트의 테스트 시간 강건성을 향상시키기 위한 자기 일관적 행동 생성(self-consistent action generation)을 제안한다. 사실 및 수학 영역에 걸쳐 8가지 추론 작업에서 이 방법을 평가한 결과, 0.5B, 1.5B, 3B 파라미터만큼 작은 sLM도 CoT 증류를 사용하여 미세 조정된 다음 단계의 더 큰 1.5B, 3B, 7B 모델과 경쟁력 있는 성능을 달성할 수 있음을 보여준다.

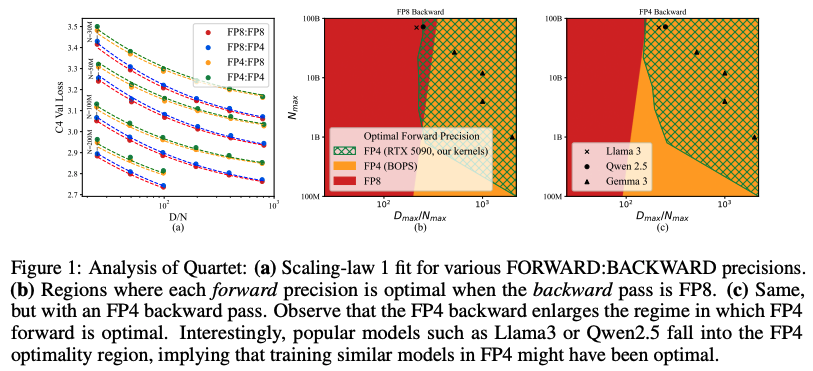
Quartet: Native FP4 Training Can Be Optimal for Large Language Models
https://arxiv.org/abs/2505.14669
대형 언어 모델(LLM)의 급속한 발전은 전례 없는 계산 요구량 증가와 함께 이루어졌으며, 최첨단 모델의 학습 비용은 몇 달마다 두 배로 증가하고 있다. 모델을 저정밀도 산술로 직접 학습하면 계산 처리량과 에너지 효율성을 모두 향상시켜 해결책을 제공할 수 있다. 특히 NVIDIA의 최신 Blackwell 아키텍처는 FP4 변형과 같은 극히 낮은 정밀도 연산을 용이하게 하여 상당한 효율성 향상을 약속한다. 그러나 FP4 정밀도로 LLM을 학습하기 위한 현재 알고리즘은 상당한 정확도 저하에 직면하고 종종 혼합 정밀도 대체에 의존한다. 이 논문은 하드웨어 지원 FP4 학습을 체계적으로 조사하고, 모든 주요 계산(예: 선형 계층)이 저정밀도로 수행되는 정확한 엔드투엔드 FP4 학습을 가능하게 하는 새로운 접근 방식인 Quartet을 소개한다. Llama 유형 모델에 대한 광범위한 평가를 통해 다양한 비트 폭에 걸쳐 성능 절충안을 정량화하는 새로운 저정밀도 스케일링 법칙을 밝혀내고, 정확도 대 계산 측면에서 "거의 최적"인 저정밀도 학습 기술인 Quartet을 식별한다. NVIDIA Blackwell GPU에 맞춤화된 최적화된 CUDA 커널을 사용하여 Quartet을 구현하고, FP4 정밀도에 대한 최첨단 정확도를 달성하여 수십억 규모 모델을 성공적으로 학습할 수 있음을 보여준다. 이 방법은 완전 FP4 기반 학습이 표준 정밀도 및 FP8 학습에 대한 경쟁력 있는 대안임을 입증한다.
R2R: Efficiently Navigating Divergent Reasoning Paths with Small-Large Model Token Routing
https://arxiv.org/abs/2505.21600
대규모 언어 모델(LLM)은 상당한 추론 오버헤드를 대가로 인상적인 추론 능력을 달성하여 상당한 배포 문제를 야기한다. 증류된 소형 언어 모델(SLM)은 효율성을 크게 향상시키지만, LLM의 추론 경로를 따르지 못해 성능이 저하된다. 다행히도, 이 논문은 LLM과 SLM 간의 추론 경로를 실제로 분기시키는 토큰은 극소수에 불과하다는 사실을 밝혀냈다. 대부분의 생성된 토큰은 동일하거나 약어 또는 표현의 사소한 차이와 같은 중립적인 차이를 보인다. 이러한 통찰을 활용하여, Roads to Rome (R2R)이라는 신경망 토큰 라우팅 방법을 소개한다. R2R은 이러한 중요하고 경로가 분기되는 토큰에 대해서만 선택적으로 LLM을 사용하고, 대부분의 토큰 생성은 SLM에 맡긴다. 또한 분기 토큰을 식별하고 가벼운 라우터를 훈련시키기 위해 토큰 수준 라우팅 레이블을 생성하는 자동 데이터 생성 파이프라인도 개발했다. R2R을 DeepSeek 제품군의 R1-1.5B 및 R1-32B 모델 결합에 적용하고, 어려운 수학, 코딩 및 QA 벤치마크에서 평가했다. 평균 활성화 파라미터 크기가 5.6B인 R2R은 R1-7B의 평균 정확도를 1.6배 능가하며 R1-14B 모델보다도 우수한 성능을 보였다. R1-32B에 비해 유사한 성능으로 2.8배의 실제 시간 속도 향상을 제공하여 테스트 시간 확장 효율성의 파레토 프론티어를 발전시킨다.

AI의 추론 능력 심층 분석 및 강화 분야
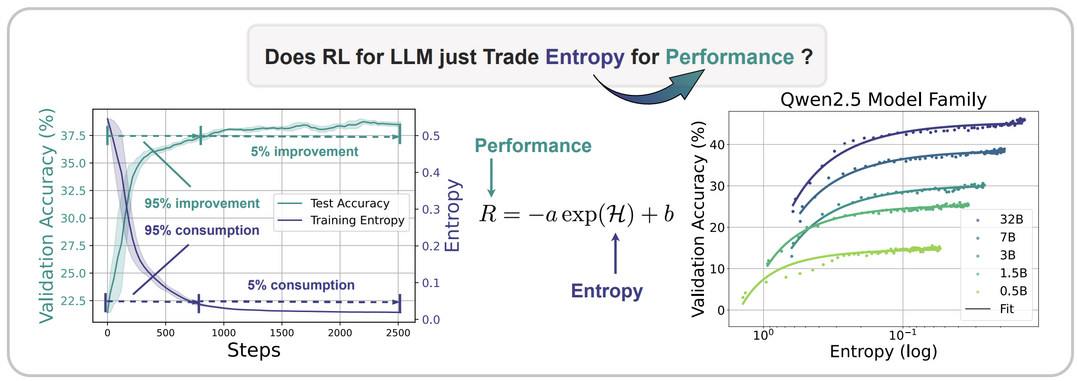
The Entropy Mechanism of Reinforcement Learning for Reasoning Language Models
https://arxiv.org/abs/2505.22617
대규모 언어 모델(LLM)을 사용한 추론에 강화학습(RL)을 적용할 때 주요 장애물은 정책 엔트로피의 붕괴이다. 엔트로피 개입 없이 강화학습을 실행하면 정책 엔트로피가 훈련 초기에 급격히 감소하여 탐색 능력이 저하되고 정책 성능이 정체되는 현상이 일관되게 관찰된다. 이 논문은 엔트로피(H)와 다운스트림 성능(R) 사이에 R=−a⋅e^H+b 라는 경험적 관계식을 정립한다. 이는 정책 성능이 정책 엔트로피를 소모하여 얻어지며, 엔트로피 고갈로 인해 병목 현상이 발생함을 시사한다. 연구진은 엔트로피 역학을 이론적, 경험적으로 조사하여 정책 엔트로피 변화가 행동 확률과 로짓 변화 간의 공분산에 의해 주도됨을 밝혀냈다. 이러한 이해를 바탕으로, 공분산이 높은 토큰의 업데이트를 제한하는 Clip-Cov와 KL-Cov라는 두 가지 간단하면서도 효과적인 기법을 제안하여 엔트로피 붕괴를 막고 더 나은 성능을 달성하도록 돕는다.
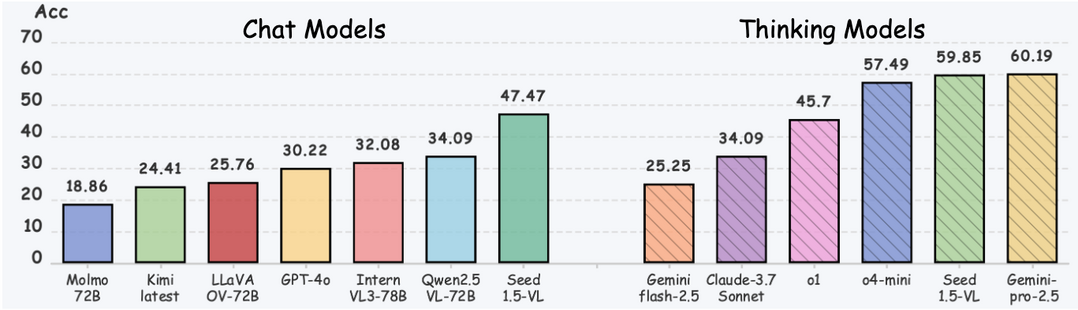
MME-Reasoning: A Comprehensive Benchmark for Logical Reasoning in MLLMs
https://arxiv.org/abs/2505.21327
논리적 추론은 인간 지능의 기본이며 멀티모달 대형 언어 모델(MLLM)의 필수 기능이다. 멀티모달 추론이 크게 발전했음에도 불구하고, 기존 벤치마크는 논리적 추론 유형에 대한 명확한 분류 부족과 추론에 대한 불분명한 이해로 인해 추론 능력을 종합적으로 평가하지 못한다. 이러한 문제를 해결하기 위해, 이 논문은 MME-Reasoning이라는 MLLM의 추론 능력 평가를 위한 포괄적인 벤치마크를 소개한다. 이 벤치마크는 귀납적, 연역적, 귀추적 추론의 세 가지 유형을 모두 포함한다. 각 질문이 지각 능력이나 지식의 폭이 아닌 추론 능력을 효과적으로 평가하도록 데이터를 신중하게 선별했으며, 다양한 질문 평가를 포괄하도록 평가 프로토콜을 확장했다. 평가 결과, 최첨단 MLLM조차도 종합적인 논리적 추론 능력에서 상당한 한계를 보였으며, 추론 유형에 따라 성능 불균형이 두드러졌다. 또한, "사고 모드"나 규칙 기반 RL과 같이 추론 능력을 향상시킨다고 일반적으로 알려진 접근 방식에 대한 심층 분석도 수행했다.
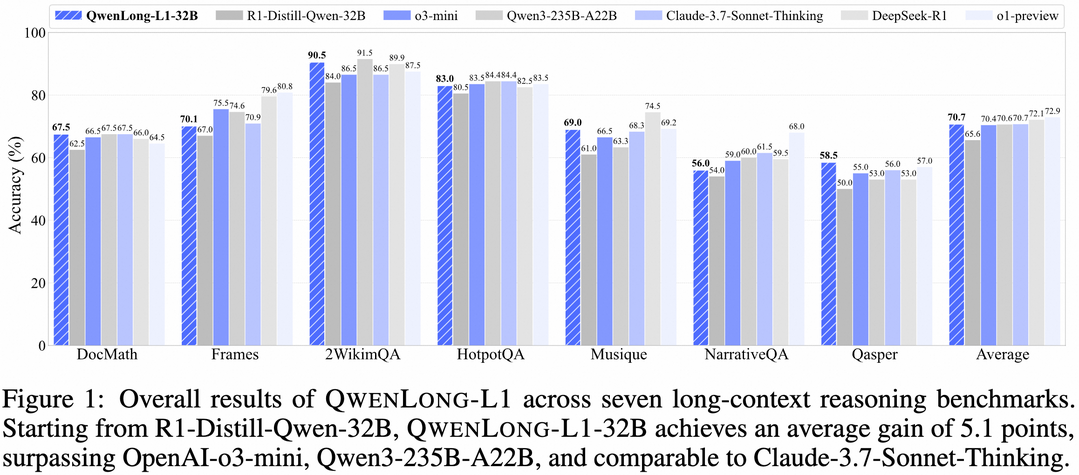
QwenLong-L1: Towards Long-Context Large Reasoning Models with Reinforcement Learning
https://arxiv.org/abs/2505.17667
최근 대형 추론 모델(LRM)은 강화학습(RL)을 통해 강력한 추론 능력을 보여주었지만, 이는 주로 짧은 컨텍스트의 추론 작업에서 관찰되었다. 반면, RL을 통해 LRM이 긴 컨텍스트 입력을 효과적으로 처리하고 추론하도록 확장하는 것은 여전히 중요한 미해결 과제이다. 이 논문은 먼저 장문 컨텍스트 추론 RL의 패러다임을 공식화하고, 비최적 훈련 효율성 및 불안정한 최적화 과정이라는 주요 과제를 식별한다. 이러한 문제를 해결하기 위해, QwenLong-L1이라는 프레임워크를 제안하여 점진적인 컨텍스트 확장을 통해 짧은 컨텍스트 LRM을 장문 컨텍스트 시나리오에 적용한다. 구체적으로, 강력한 초기 정책을 구축하기 위한 준비 지도 미세 조정(SFT) 단계를 사용하고, 정책 진화를 안정화하기 위한 커리큘럼 기반 단계적 RL 기법, 그리고 정책 탐색을 장려하기 위한 난이도 인식 회고적 샘플링 전략으로 강화한다. 7개의 장문 문서 질의응답 벤치마크 실험에서 QwenLong-L1-32B는 OpenAI-o3-mini 및 Qwen3-235B-A22B와 같은 대표적인 LRM을 능가하고 Claude-3.7-Sonnet-Thinking과 동등한 성능을 달성하여 최첨단 LRM 중 최고의 성능을 보여준다.
Reasoning Model is Stubborn: Diagnosing Instruction Overriding in Reasoning Models
https://arxiv.org/abs/2505.17225
대규모 언어 모델은 길고 복잡한 추론 작업에서 놀라운 능숙함을 보여주었지만, 익숙한 추론 패턴에 문제가 될 정도로 의존하는 경향을 자주 보이는데, 이를 추론 경직성(reasoning rigidity)이라고 명명한다. 사용자의 명시적인 지시에도 불구하고 이러한 모델은 명확하게 명시된 조건을 무시하고 습관적인 추론 경로로 기본 설정되어 잘못된 결론을 내린다. 이러한 행동은 특히 수학 및 논리 퍼즐과 같이 지정된 제약 조건에 대한 정확한 준수가 중요한 영역에서 심각한 문제를 야기한다. 이전 연구에서 거의 탐구되지 않은 행동인 추론 경직성을 체계적으로 조사하기 위해, 전문가가 선별한 진단 세트를 소개한다. 이 데이터셋에는 기존 수학 벤치마크인 AIME 및 MATH500의 특별히 수정된 변형과 익숙한 추론 전략에서 벗어나도록 의도적으로 재설계된 잘 알려진 퍼즐이 포함된다. 이 데이터셋을 사용하여 모델이 내재된 추론으로 기본 설정될 때 발생하는 반복적인 오염 패턴을 식별한다. 구체적으로, 이 오염을 (1) 해석 과부하(Interpretation Overload), (2) 입력 불신(Input Distrust), (3) 부분적 지시 주의(Partial Instruction Attention)의 세 가지 독특한 모드로 분류하며, 각 모드는 모델이 제공된 지시를 무시하거나 왜곡하도록 유발한다. 언어 모델의 추론 경직성을 완화하기 위한 향후 연구를 촉진하기 위해 진단 세트를 공개한다.

AI 에이전트, 응용 시스템 및 데이터 기반 혁신 분야
TabSTAR: A Foundation Tabular Model With Semantically Target-Aware Representations
https://arxiv.org/abs/2505.18125
딥러닝은 여러 분야에서 성공했지만, 테이블 형식 데이터 학습에서는 여전히 그래디언트 부스팅 결정 트리(GBDT)에 비해 성능이 낮았다. 최근 텍스트 데이터가 포함된 경우, 실제 지식을 활용하고 다양한 데이터셋에 일반화할 수 있는 '테이블 형식 파운데이션 모델'의 가능성이 열리고 있다. 이 논문은 TabSTAR라는 새로운 테이블 형식 파운데이션 모델을 제안한다. TabSTAR는 텍스트 특징이 있는 테이블 데이터에 전이 학습을 가능하게 하며, 데이터셋별 파라미터 없이 사전 훈련된 텍스트 인코더를 사용한다. 특히, 입력으로 '목표 토큰'을 받아 모델이 작업별 임베딩을 학습하도록 한다. TabSTAR는 텍스트 특징을 가진 분류 작업에서 중간 및 대규모 데이터셋 모두 최고 수준의 성능을 보였으며, 데이터셋 수에 따른 확장 가능성도 확인되어 추가 성능 향상의 길을 제시한다.

ScienceBoard: Evaluating Multimodal Autonomous Agents in Realistic Scientific Workflows
https://arxiv.org/abs/2505.19897
대규모 언어 모델(LLM) 기반 에이전트들이 과학적 발견을 돕는 도구로 발전하고 있다. 특히 운영체제와 상호작용하며 연구자의 작업을 자동화하는 컴퓨터 사용 에이전트의 잠재력이 크다. 이 논문은 이러한 에이전트의 능력을 평가하기 위해 ScienceBoard를 제안한다. ScienceBoard는 두 가지 주요 기여를 한다: (1) 에이전트가 복잡한 연구 작업과 실험을 가속화하기 위해 다양한 인터페이스를 통해 자율적으로 상호작용할 수 있는, 전문 소프트웨어가 통합된 현실적이고 시각적으로 풍부한 다분야 환경을 제공한다. (2) 생화학, 천문학, 지리정보학 등 과학적 발견 워크플로우를 포괄하는, 인간이 검증한 169개의 고품질 실제 작업으로 구성된 도전적인 벤치마크를 제공한다. GPT-4o, Claude 3.7과 같은 최첨단 모델을 사용한 에이전트 평가 결과, 복잡한 워크플로우에서 과학자를 안정적으로 지원하는 데는 아직 미흡하며 전반적인 성공률은 15%에 그쳤다. 이를 통해 현재 에이전트의 한계와 더 효과적인 설계 원칙에 대한 통찰을 제공한다.
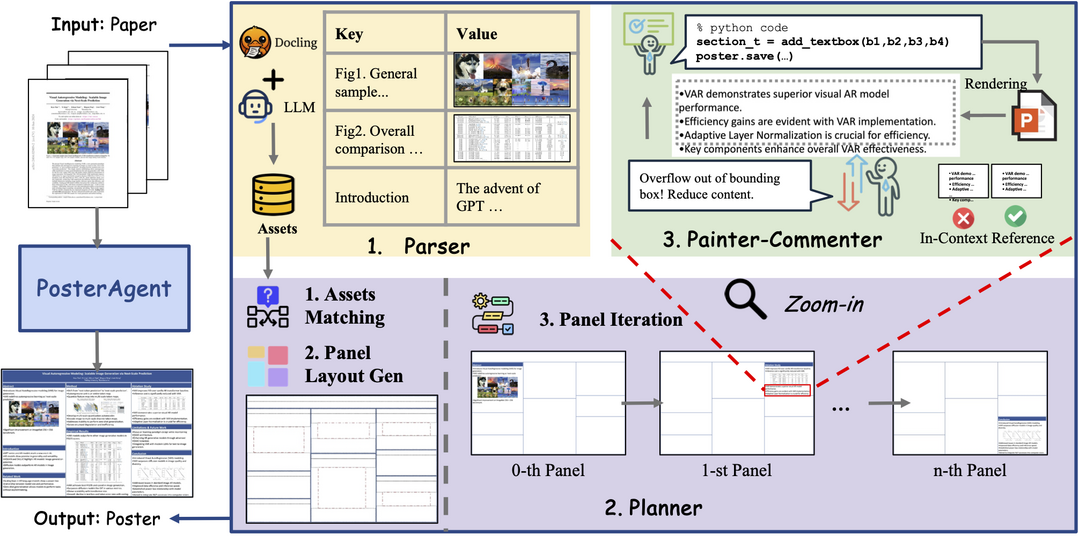
Paper2Poster: Towards Multimodal Poster Automation from Scientific Papers
https://arxiv.org/abs/2505.21497
학술 포스터 제작은 긴 내용의 문서를 시각적으로 일관성 있는 한 페이지로 압축해야 하는 중요한 작업이다. 이 논문은 포스터 생성을 위한 최초의 벤치마크 및 평가 지표 제품군을 소개한다. 이는 최근 학회 논문과 저자가 디자인한 포스터를 쌍으로 구성하며, (1)시각적 품질, (2)텍스트 일관성, (3)VLM(시각 언어 모델) 심사위원이 평가하는 6가지 세부 미학 및 정보 기준, (4)생성된 퀴즈에 VLM이 답하여 포스터가 논문 핵심 내용을 전달하는 능력을 측정하는 PaperQuiz로 결과물을 평가한다. 또한 PosterAgent라는 하향식, 시각적 피드백 루프를 갖춘 다중 에이전트 파이프라인을 제안한다. PosterAgent는 (a)파서가 논문을 구조화된 자산 라이브러리로 추출하고, (b)플래너가 텍스트-시각 쌍을 이진 트리 레이아웃으로 정렬하며, (c)페인터-코멘터 루프가 렌더링 코드를 실행하고 VLM 피드백을 사용하여 각 패널을 개선한다. 평가 결과, GPT-4o 결과물은 시각적으로는 매력적이나 텍스트 노이즈와 낮은 PaperQuiz 점수를 보였으며, 인간 디자인 포스터는 시각적 의미 전달에 크게 의존하므로 독자 참여가 주요 미적 병목 지점임이 밝혀졌다. Qwen-2.5 시리즈 기반의 완전 오픈소스 변형 모델은 토큰 사용량을 87% 줄이면서도 거의 모든 지표에서 기존 4o 기반 다중 에이전트 시스템을 능가하며, 22페이지 논문을 편집 가능한 .pptx 포스터로 단돈 $0.005에 변환한다.
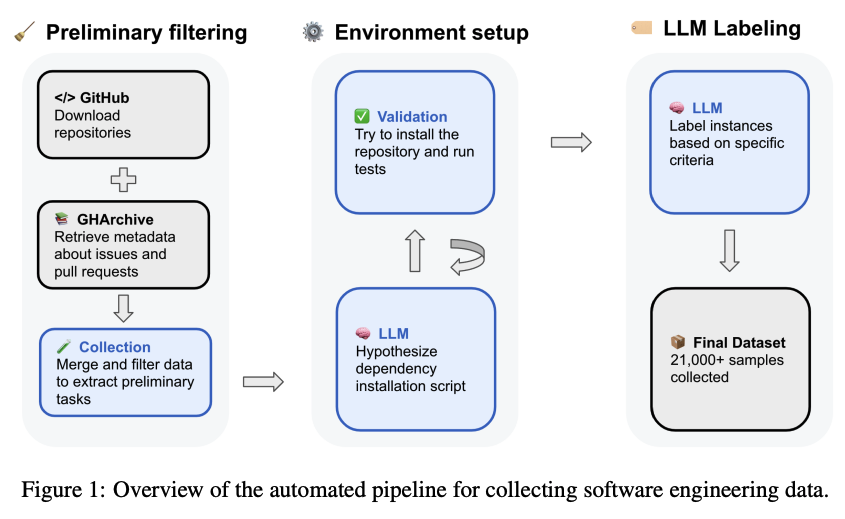
SWE-rebench: An Automated Pipeline for Task Collection and Decontaminated Evaluation of Software Engineering Agents
https://arxiv.org/abs/2505.20411
LLM 기반 에이전트는 소프트웨어 공학(SWE) 작업에서 유망한 능력을 보여주고 있지만, 이 분야의 발전에는 두 가지 중요한 과제가 있다. 첫째, 고품질 훈련 데이터, 특히 에이전트가 개발 환경과 상호작용하고 코드를 실행하며 행동 결과를 기반으로 행동을 조정해야 하는 실제 SWE 시나리오를 반영하는 데이터가 부족하다. 둘째, 새로운 대화형 SWE 작업의 부족은 정적 벤치마크가 오염 문제로 인해 빠르게 구식이 되면서 빠르게 개선되는 모델의 평가에 영향을 미친다. 이러한 한계를 해결하기 위해, 이 논문은 다양한 GitHub 저장소에서 실제 대화형 SWE 작업을 지속적으로 추출하는 새롭고 자동화되었으며 확장 가능한 파이프라인을 소개한다. 이 파이프라인을 사용하여 대규모 SWE 에이전트의 강화 학습에 적합한 21,000개 이상의 대화형 Python 기반 SWE 작업으로 구성된 공개 데이터셋인 SWE-rebench를 구축한다. 또한, SWE-rebench 방법론을 사용하여 수집된 새로운 작업의 지속적인 공급을 통해 에이전트 기반 소프트웨어 공학을 위한 오염 없는 벤치마크를 구축한다. 이 벤치마크에서 다양한 LLM의 결과를 SWE-bench Verified의 결과와 비교하여 일부 언어 모델의 성능이 오염 문제로 인해 부풀려졌을 수 있음을 보여준다.
Alchemist: Turning Public Text-to-Image Data into Generative Gold
https://arxiv.org/abs/2505.19297
사전 훈련은 텍스트-이미지(T2I) 모델에 광범위한 세계 지식을 제공하지만, 이것만으로는 높은 미적 품질과 정렬을 달성하기에 충분하지 않은 경우가 많다. 따라서 지도 미세 조정(SFT)은 추가 개선에 매우 중요하다. 그러나 그 효과는 미세 조정 데이터셋의 품질에 크게 좌우된다. 기존 공개 SFT 데이터셋은 종종 좁은 영역(예: 애니메이션 또는 특정 아트 스타일)을 대상으로 하며, 고품질의 범용 SFT 데이터셋 생성은 여전히 중요한 과제이다. 현재 큐레이션 방법은 비용이 많이 들고 진정으로 영향력 있는 샘플을 식별하는 데 어려움을 겪는다. 이 논문은 사전 훈련된 생성 모델을 영향력 있는 훈련 샘플 추정기로 활용하여 범용 SFT 데이터셋을 생성하는 새로운 방법론을 소개한다. 이 방법론을 적용하여 작지만(3,350개 샘플) 매우 효과적인 SFT 데이터셋인 Alchemist를 구축하고 공개한다. 실험 결과, Alchemist는 다양성과 스타일을 보존하면서 5개의 공개 T2I 모델의 생성 품질을 크게 향상시키는 것으로 나타났다. 또한 미세 조정된 모델의 가중치도 공개한다.

OmniConsistency: Learning Style-Agnostic Consistency from Paired Stylization Data
https://arxiv.org/abs/2505.18445
확산 모델은 이미지 스타일화를 크게 발전시켰지만, 두 가지 핵심 과제가 남아 있다: (1) 복잡한 장면, 특히 정체성, 구성 및 미세한 세부 사항에서 일관된 스타일화 유지, (2) 스타일 LoRA를 사용하는 이미지 대 이미지 파이프라인에서 스타일 저하 방지. GPT-4o의 뛰어난 스타일화 일관성은 오픈소스 방법과 독점 모델 간의 성능 격차를 강조한다. 이러한 격차를 해소하기 위해, 이 논문은 대규모 확산 트랜스포머(DiT)를 활용하는 보편적인 일관성 플러그인인 OmniConsistency를 제안한다. OmniConsistency는 다음을 기여한다: (1) 강력한 일반화를 위해 정렬된 이미지 쌍에 대해 훈련된 컨텍스트 내 일관성 학습 프레임워크, (2) 스타일 저하를 완화하기 위해 스타일 학습과 일관성 보존을 분리하는 2단계 점진적 학습 전략, (3) Flux 프레임워크 하에서 임의의 스타일 LoRA와 호환되는 완전한 플러그 앤 플레이 설계. 광범위한 실험을 통해 OmniConsistency는 시각적 일관성과 미적 품질을 크게 향상시켜 상용 최첨단 모델인 GPT-4o와 유사한 성능을 달성함을 보여준다.

[METAX = 김한얼 기자]
[저작권자ⓒ META-X. 무단전재-재배포 금지]