자체 대국을 통한 자율 학습과 뇌 모델 기반 추론으로 현실 세계의 복잡한 과제 해결 능력의 고도화
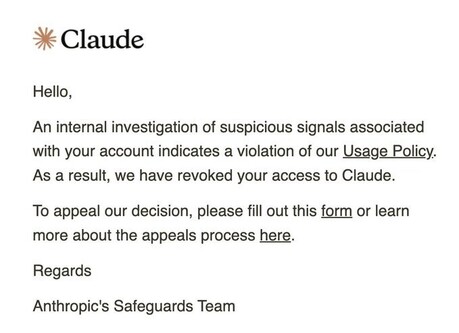
The Dragon Hatchling: The Missing Link between the Transformer and Models of the Brain
https://arxiv.org/abs/2509.26507
'The Dragon Hatchling' 논문은 뇌의 작동 방식에서 영감을 받아 기존 트랜스포머의 한계를 극복하는 새로운 LLM 아키텍처 BDH를 제안한다. 이 모델은 국소적으로 상호작용하는 뉴런 네트워크 구조를 기반으로 하며, 스파이킹 뉴런과 헤브 학습을 통해 작동 기억을 구현하여 시간적 일반화 문제를 해결한다. BDH는 GPT-2와 유사한 파라미터 수로 동등한 성능을 보이면서도, 특정 개념을 처리할 때 관련된 시냅스가 강화되는 현상을 보여주는 등 모델의 작동 방식을 해석하기 용이해 인간의 언어 습득 메커니즘에 대한 새로운 가능성을 제시한다.
LongLive: Real-time Interactive Long Video Generation
https://arxiv.org/abs/2509.22622
'LongLive'는 실시간 상호작용을 통해 긴 동영상을 생성할 때 발생하는 속도 저하와 품질 문제를 해결하는 새로운 프레임워크를 소개한다. 이 기술은 프롬프트가 바뀌어도 KV-recache 메커니즘으로 자연스러운 장면 전환을 구현하고, 스트리밍 튜닝과 단기 윈도우 어텐션을 통해 계산 효율을 높이면서도 영상 전체의 일관성을 유지한다. 그 결과 단일 GPU 환경에서 초당 20.7 프레임의 빠른 속도로 최대 4분 길이의 고품질 영상을 실시간으로 생성하고 편집할 수 있는 강력한 성능을 보인다.

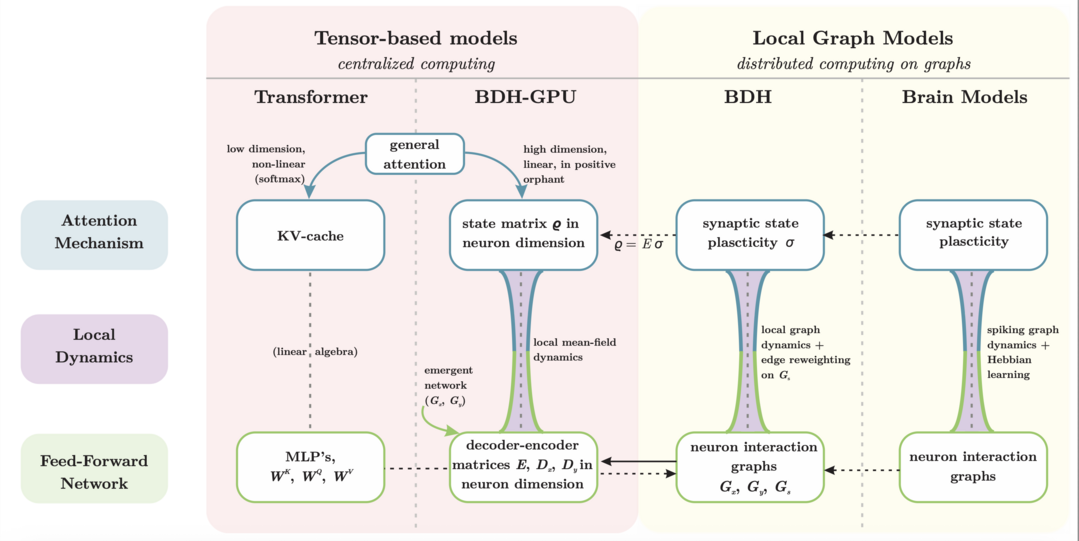
MCPMark: A Benchmark for Stress-Testing Realistic and Comprehensive MCP Use
https://arxiv.org/abs/2509.24002
'MCPMark'는 기존 벤치마크들이 현실 세계의 복잡성을 반영하지 못한다는 문제의식에서 출발하여, LLM 에이전트의 실제 업무 처리 능력을 심도 있게 평가하는 새로운 기준을 제시한다. 이 벤치마크는 단순 정보 조회를 넘어 생성, 수정, 삭제(CRUD)를 포함하는 복합적인 과제들로 구성되어 있으며, gpt-5-medium과 같은 최신 모델조차 50%대의 낮은 성공률을 기록할 만큼 난이도가 높다. 이를 통해 MCPMark는 현재 LLM 에이전트가 가진 명확한 한계를 드러내는 강력한 스트레스 테스트로서의 가치를 입증한다.
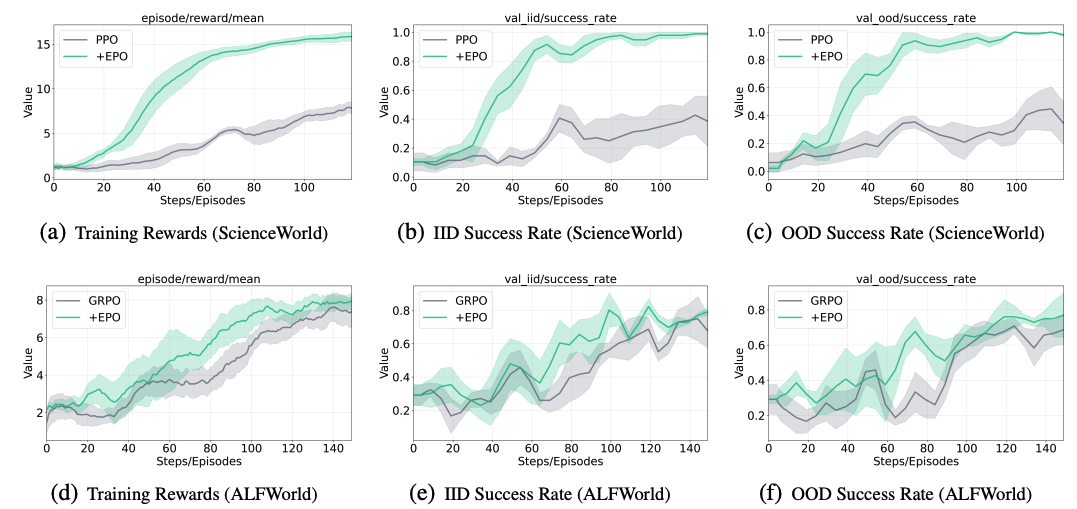
EPO: Entropy-regularized Policy Optimization for LLM Agents Reinforcement Learning
https://arxiv.org/abs/2509.22576
'EPO(엔트로피 정규화 정책 최적화)'는 보상이 드물고 상호작용이 긴 복잡한 환경에서 LLM 에이전트가 학습에 실패하는 '연쇄 실패' 문제를 해결하기 위한 프레임워크다. 학습 초기에 섣불리 잘못된 전략에 고착되거나 후반에 불안정한 탐색으로 붕괴하는 현상을 막기 위해, EPO는 엔트로피를 안정적으로 제어하며 학습 단계에 따라 탐험과 활용의 균형을 동적으로 조절한다. 이 접근법을 통해 기존 방식보다 최대 152% 높은 성능 향상을 달성하며 복잡한 환경에서의 에이전트 훈련에 대한 근본적으로 다른 제어 방식이 필요함을 보인다.
Vision-Zero: Scalable VLM Self-Improvement via Strategic Gamified Self-Play
https://arxiv.org/abs/2509.25541
'Vision-Zero'는 막대한 비용이 드는 인간의 데이터 생성 및 검증 과정 없이, 비전-언어 모델(VLM)이 스스로의 능력을 향상시킬 수 있는 혁신적인 프레임워크를 제안한다. 이 시스템 안에서 모델들은 '스파이 찾기'와 같은 경쟁적인 시각 게임을 서로 진행하며, 이 과정에서 스스로 학습 데이터를 생성하고 전략적 추론 능력을 발전시킨다. 특히 '자체 대국'과 강화학습을 주기적으로 번갈아 수행하는 방식을 통해 성능 정체 없이 지속적인 성장을 이뤄내며, 라벨링된 데이터 없이도 기존 최고 수준의 모델들을 뛰어넘는 결과를 달성한다.
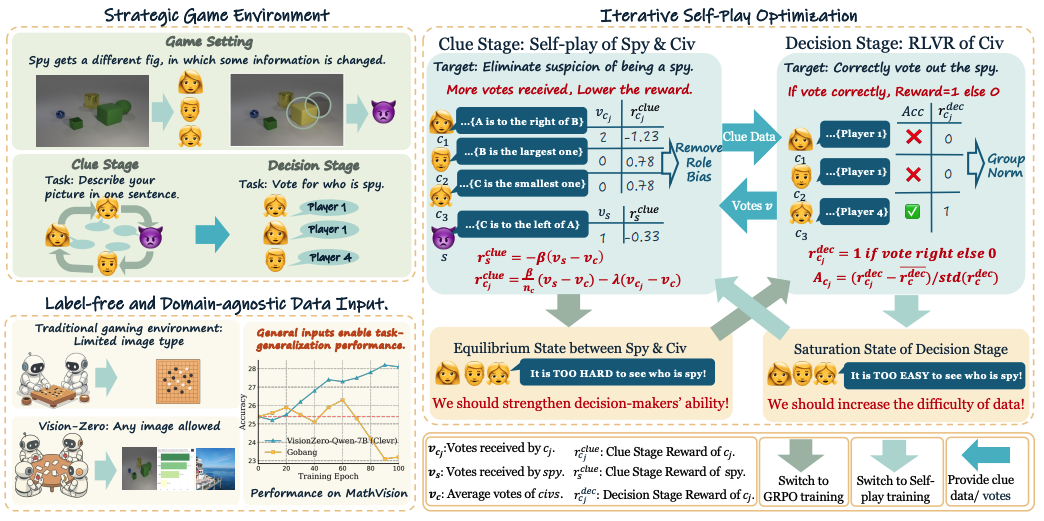
Quantile Advantage Estimation for Entropy-Safe Reasoning
https://arxiv.org/abs/2509.22611
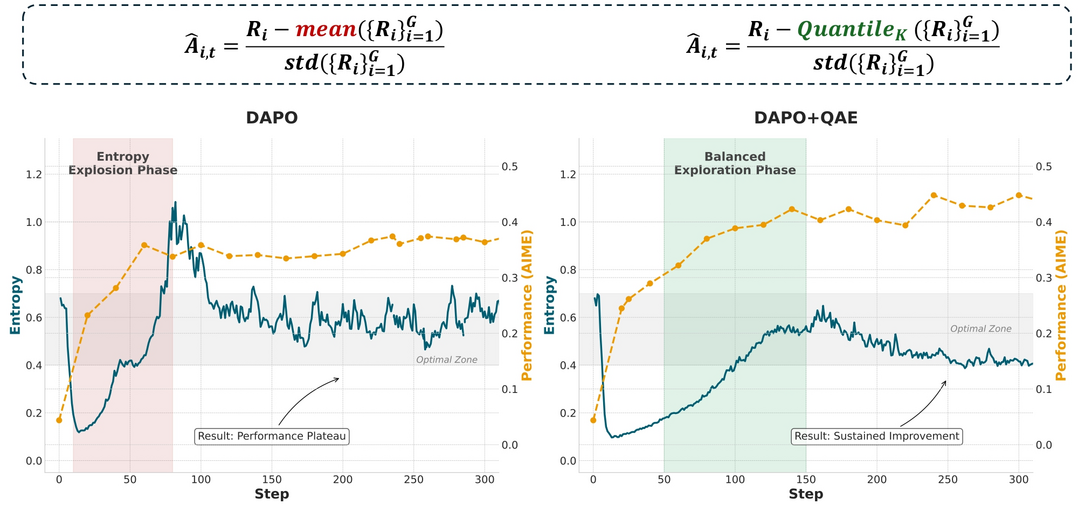
'Quantile Advantage Estimation(QAE)'은 강화학습(RLVR)으로 LLM의 추론 능력을 훈련할 때 발생하는 '엔트로피 붕괴'와 '폭발' 현상으로 인한 학습 불안정성 문제를 해결하는 기술이다. 기존의 평균 기반 평가 방식이 아닌 K-분위수를 기준으로 답변의 가치를 평가함으로써, 어려운 문제에 대한 드문 성공 사례는 강화하고 쉬운 문제의 실패 사례에 집중하는 효율적인 학습을 유도한다. 이 간단하지만 핵심적인 변경을 통해 학습 과정의 엔트로피를 안정시키고, 수학 추론 벤치마크에서 지속적인 성능 향상을 이끌어내는 데 성공한다.
DeepSearch: Overcome the Bottleneck of Reinforcement Learning with Verifiable Rewards via Monte Carlo Tree Search
https://arxiv.org/abs/2509.25454
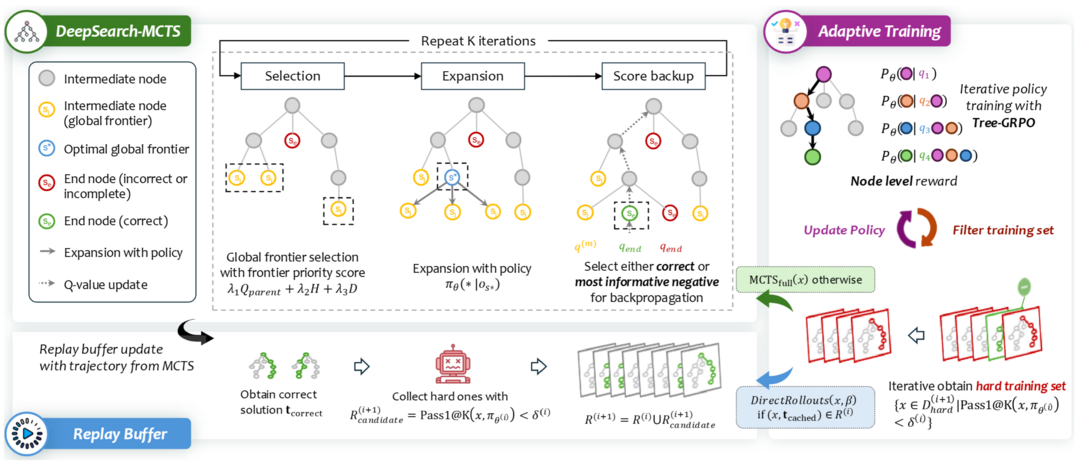
'DeepSearch'는 LLM의 추론 능력 강화학습(RLVR)이 일정 수준에서 성능이 정체되는 한계를 극복하기 위해, 몬테카를로 트리 탐색(MCTS)을 훈련 과정에 직접 통합하는 새로운 프레임워크를 제시한다. 기존 방식의 부족한 탐색 문제를 해결하고자 훈련 단계에서부터 체계적으로 해답 공간을 탐색하며 유망한 추론 경로를 발견하고 집중적으로 학습시킨다. 그 결과, 무작정 계산량을 늘리는 방식보다 5.7배나 적은 GPU 자원을 사용하고도 1.5B 모델 기준 수학 추론 벤치마크에서 새로운 최고 성능을 달성하며, 알고리즘 혁신의 중요성을 강조한다.
SLA: Beyond Sparsity in Diffusion Transformers via Fine-Tunable Sparse-Linear Attention
https://arxiv.org/abs/2509.24006
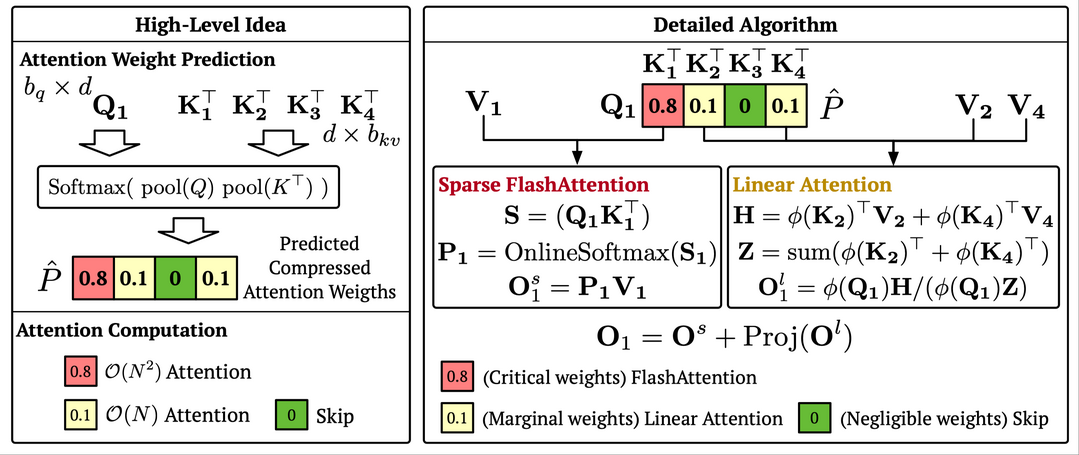
'SLA(희소-선형 어텐션)'는 동영상 생성 모델(DiT)의 가장 큰 속도 저하 원인인 어텐션 연산의 병목 현상을 해결하는 효율적인 기술이다. 이 방법은 어텐션 가중치의 중요도를 분석하여 '핵심', '주변부', '무시 가능'으로 분류하고, 각각에 차등적인 계산(복잡한 연산, 선형 연산, 생략)을 적용하여 전체 연산량을 극적으로 줄인다. 이 접근법을 통해 약간의 파인튜닝만으로 동영상 품질의 저하 없이 어텐션 연산량을 95% 감소시키고, 전체 생성 속도를 2.2배가량 향상시키는 데 성공한다.
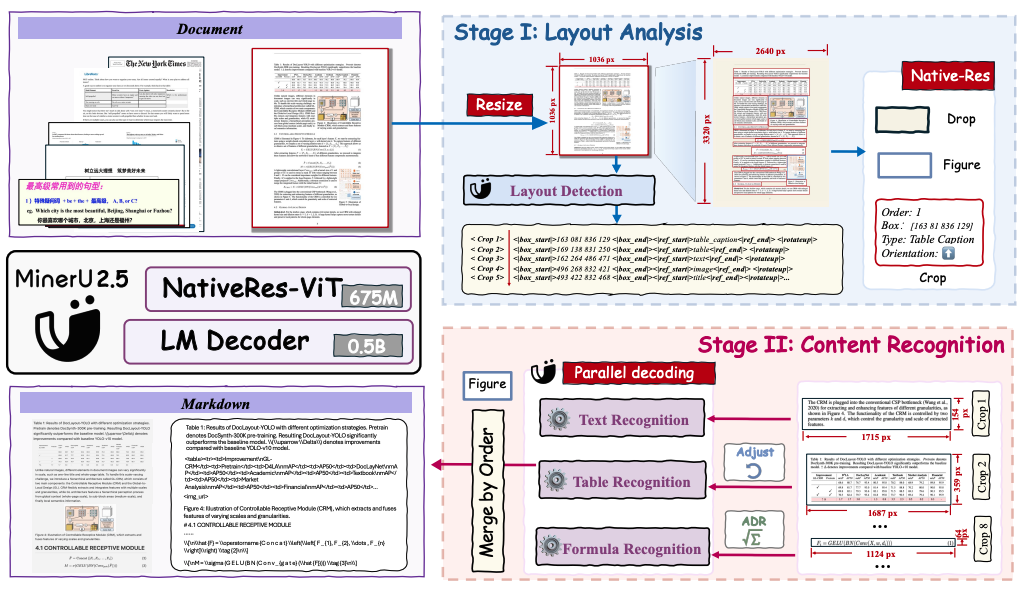
MinerU2.5: A Decoupled Vision-Language Model for Efficient High-Resolution Document Parsing
https://arxiv.org/abs/2509.22186
'MinerU2.5'는 빽빽한 텍스트나 복잡한 수식이 포함된 고해상도 문서를 높은 연산 비용 없이 효율적으로 분석하는 비전-언어 모델이다. 이 모델은 먼저 저해상도 이미지로 문서 전체의 구조적 레이아웃을 빠르게 파악하고, 그 다음 파악된 정보를 바탕으로 원본 고해상도 이미지의 핵심적인 부분만 잘라내어 정밀하게 내용을 인식하는 2단계 전략을 사용한다. 이러한 '대략적인 분석 후 세부 인식' 접근법 덕분에 적은 계산 자원으로도 여러 문서 분석 벤치마크에서 기존의 특화 모델들을 뛰어넘는 최고 수준의 정확도를 달성한다.
[METAX = 김한얼 기자]
[저작권자ⓒ META-X. 무단전재-재배포 금지]