생성형 AI를 통한 3D 장면 재구성, 애니메이션 채색, 그리고 웹 에이전트의 초인적 추론 구현
TL;DR
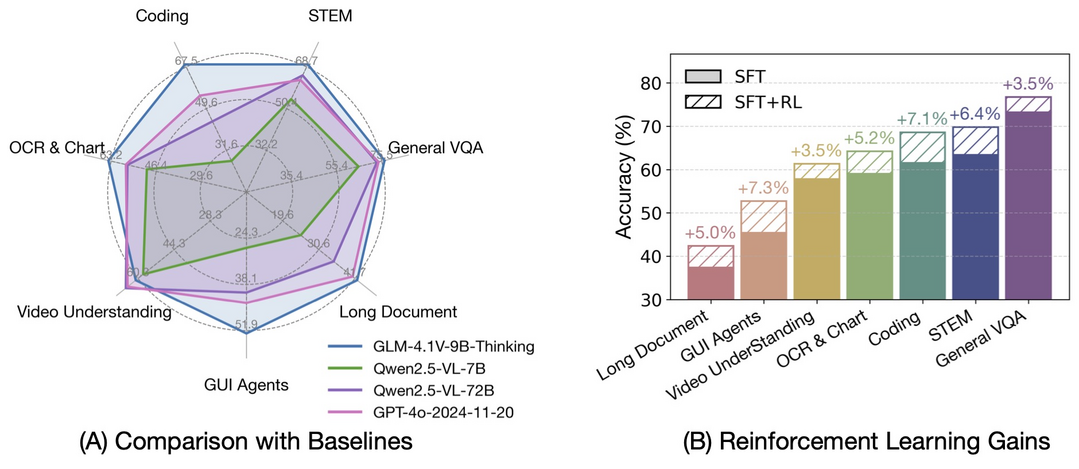
1. GLM-4.1V-Thinking: 대규모 사전 학습과 강화 학습으로 STEM 문제, 비디오 이해 등 다양한 멀티모달 추론 능력을 강화한 비전-언어 모델이다.
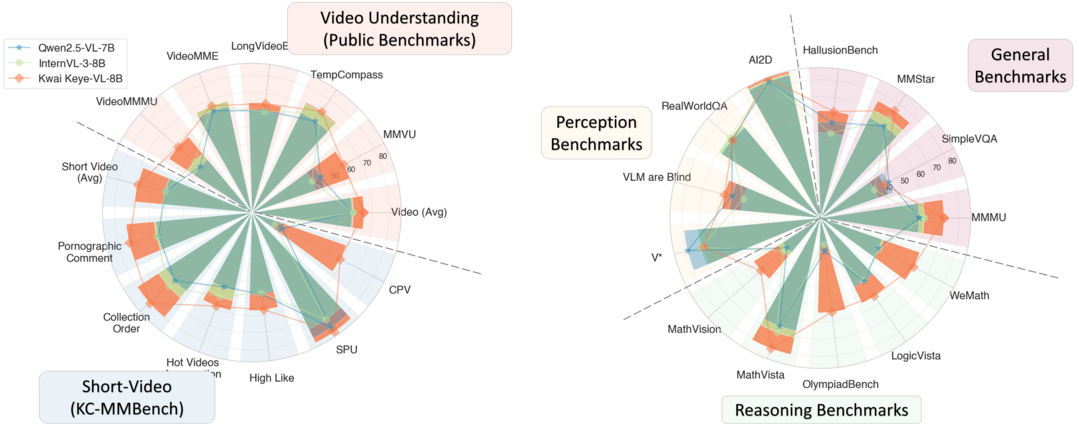
2. Kwai Keye-VL Technical Report: 대규모 고품질 비디오 데이터와 혁신적인 다단계 학습을 통해 짧은 비디오 이해 능력을 극대화한 멀티모달 모델이다.
3. LongAnimation: 동적 전역-지역 메모리 기법으로 긴 애니메이션의 장기적인 색상 일관성을 유지하며 자동 채색하는 프레임워크이다.
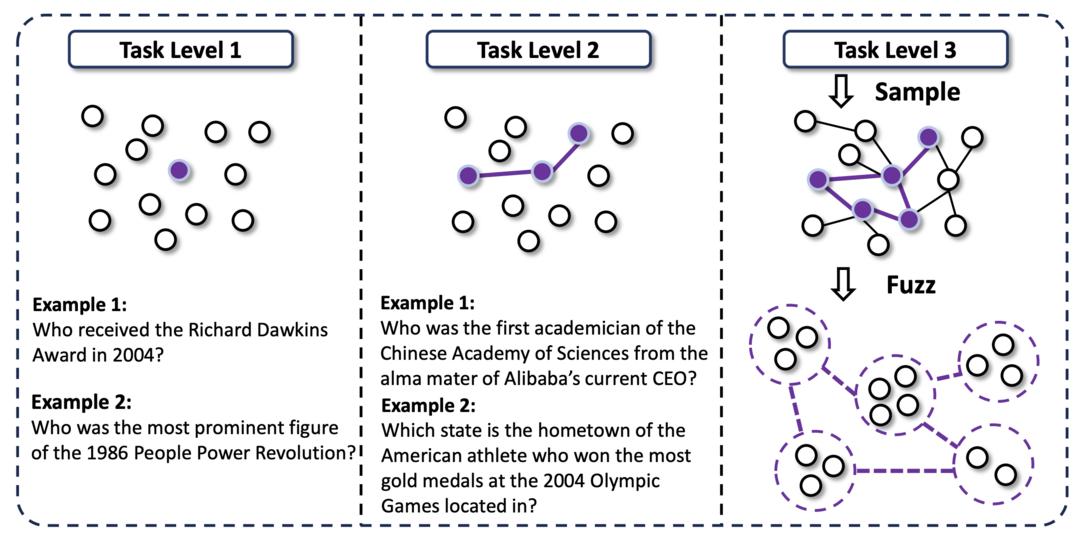
4. WebSailor: 고불확실성 작업 생성과 효율적인 강화 학습으로 웹 에이전트의 초인적인 정보 탐색 및 추론 능력을 구현하는 방법론이다.
5. BlenderFusion: 3D 기반 제어와 생성형 컴포지터를 활용하여 시각적 입력을 3D 엔티티로 분리, 편집, 합성하는 혁신적인 프레임워크이다.
6. Ovis-U1 Technical Report: 멀티모달 이해, 텍스트-이미지 생성, 이미지 편집 기능을 통합하고 단일 학습으로 성능을 향상시킨 효율적인 모델이다.
7. Does Math Reasoning Improve General LLM Capabilities? Understanding Transferability of LLM Reasoning: 수학 추론 훈련이 강화 학습 방식일 때만 일반 LLM 능력 전이에 효과적이며, 지도 미세 조정은 오히려 일반 능력을 저해할 수 있음을 밝힌다.
8. LangScene-X: TriMap 비디오 확산 모델과 언어 양자화 압축기를 사용하여 희소한 뷰에서도 일반화 가능한 3D 언어 임베디드 장면을 재구성하는 생성 프레임워크이다.
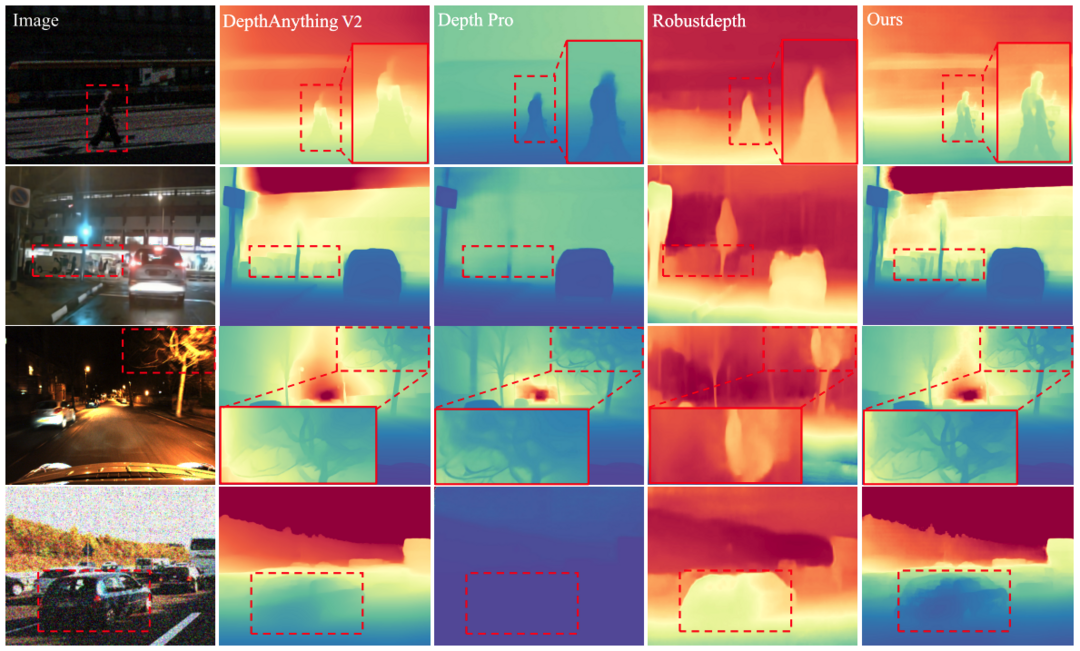
9. Depth Anything at Any Condition: 비지도 일관성 정규화와 공간 거리 제약을 통해 다양한 환경 조건에서도 뛰어난 성능을 발휘하는 단안 깊이 추정 파운데이션 모델이다.
GLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning
https://arxiv.org/abs/2507.01006
GLM-4.1V-Thinking은 다목적 멀티모달 추론을 위해 설계된 비전-언어 모델(VLM)이다. 대규모 사전 학습으로 비전 기반 모델을 개발한 후, 커리큘럼 샘플링을 활용한 강화 학습(RLCS)을 통해 모델의 잠재력을 최대한 발휘시켰다. 이로 인해 STEM 문제 해결, 비디오 이해, 코딩, 긴 문서 이해 등 다양한 작업에서 성능이 크게 향상되었다. 특히, GLM-4.1V-9B-Thinking은 GPT-4o와 같은 비공개 모델과 비교해도 뛰어난 성능을 보여준다.
Kwai Keye-VL Technical Report
https://arxiv.org/abs/2507.01949
Kwai Keye-VL은 짧은 비디오 이해에 특화된 80억 매개변수 멀티모달 파운데이션 모델이다. 6천억 토큰 이상의 대규모 고품질 비디오 중심 데이터셋과 혁신적인 4단계 사전 학습 및 2단계 사후 학습(고급 추론을 위한 5가지 모드의 콜드 스타트 데이터 혼합 포함)을 통해 개발되었다. Keye-VL은 공개 비디오 벤치마크에서 최첨단 결과를 달성하며 일반 이미지 기반 작업에서도 경쟁력을 유지한다.
LongAnimation: Long Animation Generation with Dynamic Global-Local Memory
https://arxiv.org/abs/2507.01945
LongAnimation은 동적 전역-지역 메모리(DGLM)를 사용하여 긴 애니메이션의 색상 일관성을 유지하며 자동 채색하는 프레임워크이다. 기존 방식은 지역적 정보에만 집중하여 장기적인 색상 일관성 유지가 어려웠지만, LongAnimation은 전역적인 색상 일관성 특징을 동적으로 추출하여 이를 해결한다. SketchDiT, DGLM, 색상 일관성 보상(Color Consistency Reward)을 통해 장단기 색상 일관성을 효과적으로 유지한다.

WebSailor: Navigating Super-human Reasoning for Web Agent
https://arxiv.org/abs/2507.02592
WebSailor는 웹 에이전트가 인간의 인지적 한계를 뛰어넘어 초인적인 추론 능력을 갖추도록 훈련하는 사후 학습 방법론이다. 특히, 방대한 정보 환경에서 극심한 불확실성을 체계적으로 줄이는 능력을 주입하는 데 중점을 둔다. 새로운 고불확실성 작업 생성, RFT 콜드 스타트, 효율적인 에이전트 RL 훈련 알고리즘(Duplicating Sampling Policy Optimization, DUPO)을 통합하여 오픈소스 에이전트의 성능을 크게 향상시키고 독점 에이전트와 유사한 성능을 달성한다.
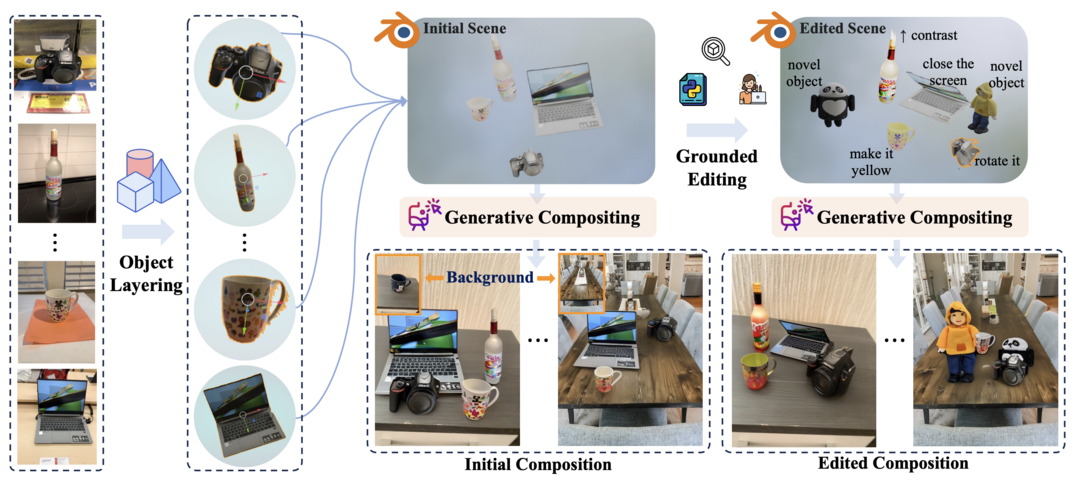
BlenderFusion: 3D-Grounded Visual Editing and Generative Compositing
https://arxiv.org/abs/2506.17450
BlenderFusion은 객체, 카메라, 배경을 재구성하여 새로운 장면을 합성하는 생성형 시각 합성 프레임워크이다. 시각적 입력을 편집 가능한 3D 엔티티로 분할(레이어링), Blender에서 3D 기반 제어로 편집(편집), 그리고 생성형 컴포지터를 사용하여 일관된 장면으로 융합(합성)하는 파이프라인을 따른다. 이를 통해 복잡한 구성 장면 편집 작업에서 기존 방법을 능가하는 성능을 보여준다.
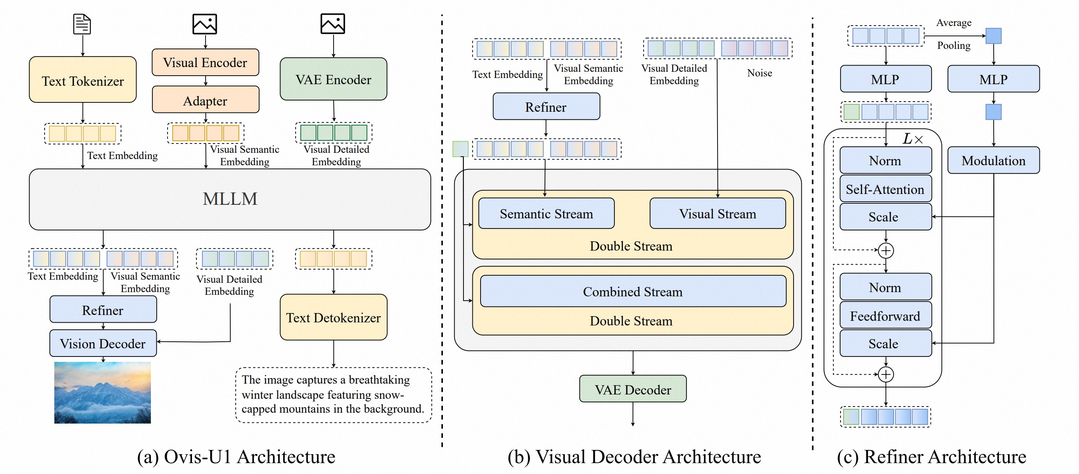
Ovis-U1 Technical Report
https://arxiv.org/abs/2506.23044
Ovis-U1은 멀티모달 이해, 텍스트-이미지 생성, 이미지 편집 기능을 통합한 30억 매개변수 통합 모델이다. 확산 기반 시각 디코더와 양방향 토큰 개선기를 결합하여 GPT-4o와 같은 선도적인 모델과 유사한 이미지 생성 작업을 가능하게 한다. 통합 학습 접근 방식을 통해 이해 및 생성 작업 모두에서 향상된 성능을 달성하며, 여러 벤치마크에서 최신 모델을 능가하는 결과를 보여준다.
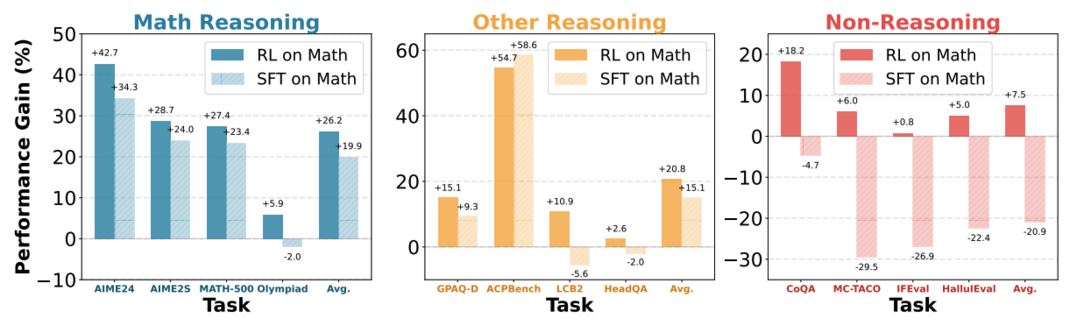
Does Math Reasoning Improve General LLM Capabilities? Understanding Transferability of LLM Reasoning
https://arxiv.org/abs/2507.00432
이 논문은 수학 추론 능력이 일반적인 LLM 능력 향상에 기여하는지 연구한다. 놀랍게도 대부분의 수학에 성공적인 모델들이 다른 도메인으로 이득을 전이하지 못한다는 것을 발견한다. 통제된 실험을 통해 강화 학습(RL)으로 튜닝된 모델은 도메인 전반에 걸쳐 잘 일반화되는 반면, 지도 미세 조정(SFT)으로 튜닝된 모델은 일반적인 능력을 잊어버리는 경향이 있음을 밝혀낸다. 이는 표준 사후 학습 방식, 특히 SFT 증류 데이터 의존성에 대한 재고를 시사한다.
LangScene-X: Reconstruct Generalizable 3D Language-Embedded Scenes with TriMap Video Diffusion
https://arxiv.org/abs/2507.02813
LangScene-X는 2D 이미지에서 개방형 어휘 장면 이해를 통해 일반화 가능한 3D 언어 임베디드 장면을 재구성하는 생성 프레임워크이다. 희소한 시점에서 3D 일관된 다중 모달 정보를 생성하며, 특히 TriMap 비디오 확산 모델을 통해 외형, 기하학, 의미론을 생성하고, 대규모 이미지 데이터셋으로 훈련된 언어 양자화 압축기(LQC)를 사용하여 효율적으로 언어 임베딩을 인코딩한다. 이를 통해 실제 데이터에서 뛰어난 품질과 일반화 가능성을 보여준다.

Depth Anything at Any Condition
https://arxiv.org/abs/2507.01634
Depth Anything at Any Condition (DepthAnything-AC)는 다양한 환경 조건(조명 변화, 악천후, 센서 왜곡 등)을 처리할 수 있는 단안 깊이 추정(MDE) 파운데이션 모델이다. 데이터 부족과 손상된 이미지에서 고품질 의사 레이블을 생성하기 어려운 문제를 극복하기 위해 상대적으로 적은 양의 레이블 없는 데이터만으로 학습 가능한 비지도 일관성 정규화 미세 조정 패러다임을 제안한다. 실험 결과, 다양한 벤치마크에서 뛰어난 제로샷 성능을 보여준다.
[METAX = 김한얼 기자]
[저작권자ⓒ META-X. 무단전재-재배포 금지]