강화학습 기반 Vision-Language 모델과 Diffusion 생성 시스템의 실용적 응용
TL;DR
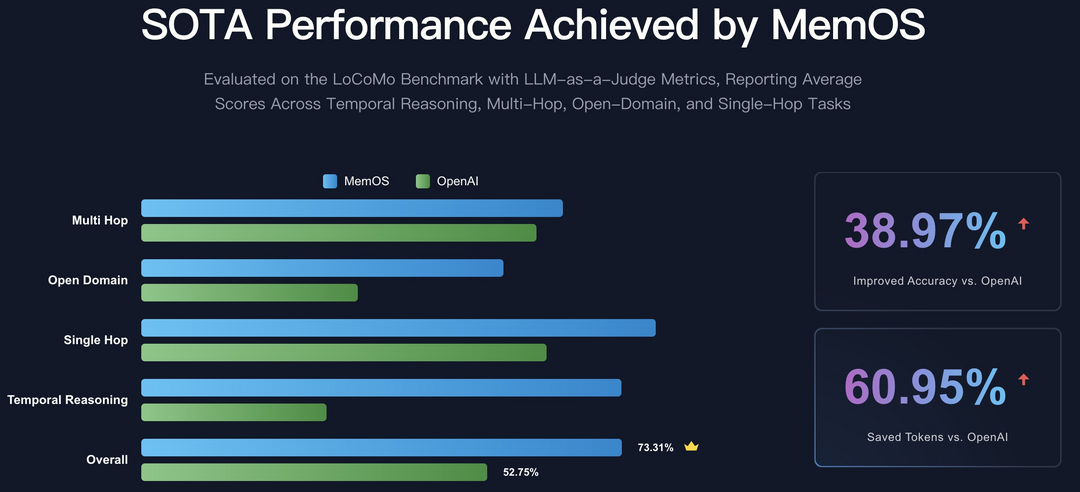
1.MemOS: LLM을 위한 메모리 운영체제로 텍스트, 활성화, 매개변수 메모리를 통합 관리하여 장기 추론과 개인화를 가능하게 한다.
2.SingLoRA: 단일 행렬과 그 전치행렬의 곱으로 LoRA를 단순화하여 매개변수를 50% 줄이면서도 더 안정적이고 높은 성능을 달성한다.
3.Scaling RL to Long Videos: 52K 긴 비디오 QA 데이터셋과 MR-SP 훈련 인프라로 LongVILA-R1이 Gemini-1.5-Pro 수준의 긴 비디오 추론 성능을 달성한다.
4.T-LoRA: 확산 시간 단계별로 다른 강도의 업데이트를 적용하여 단일 이미지 확산 모델 맞춤화에서 과적합 문제를 해결한다.
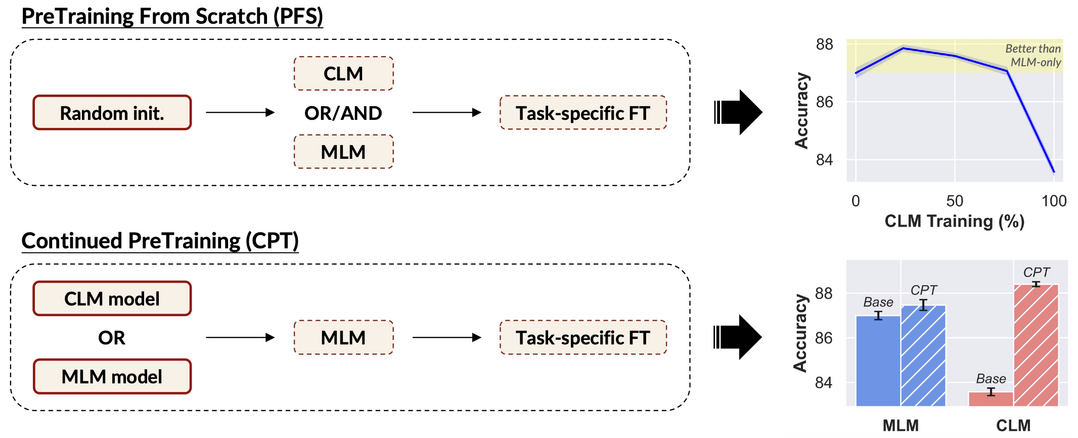
5.MLM vs CLM: 30개 모델 대규모 실험을 통해 CLM→MLM 순차 훈련이 고정 예산 하에서 최적 텍스트 표현 성능을 달성함을 입증한다.
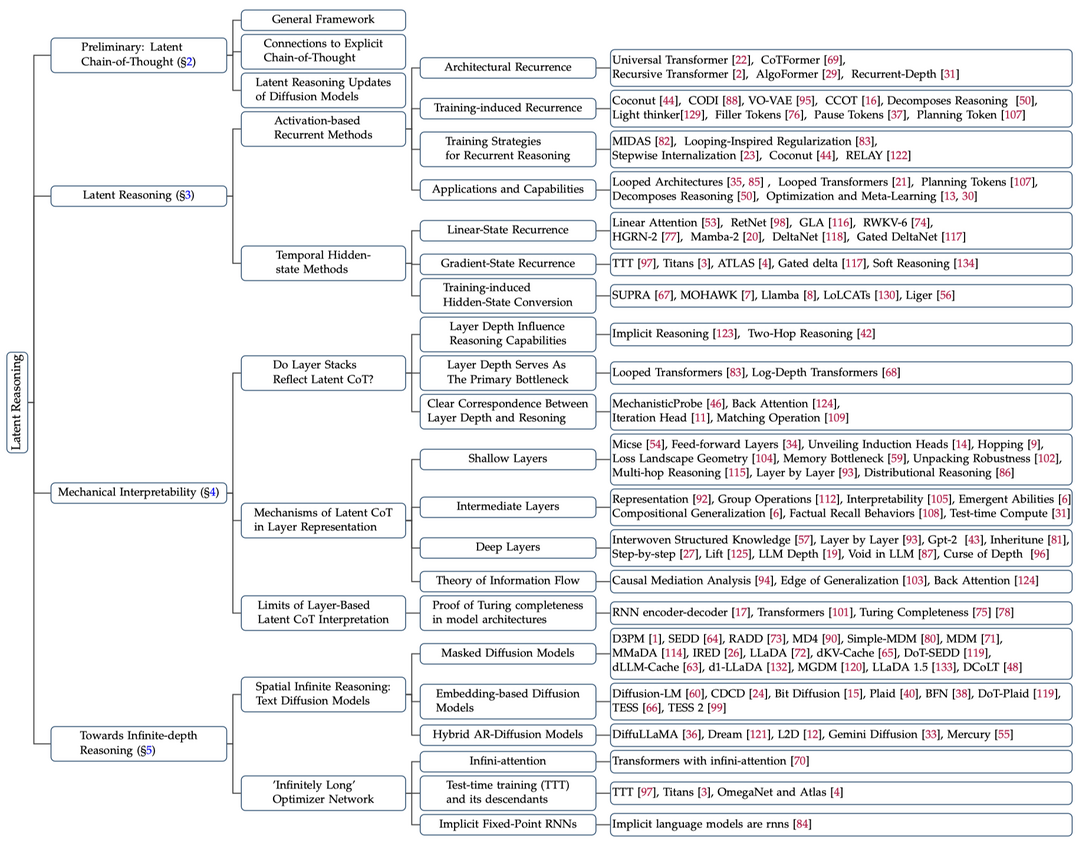
6.A Survey on Latent Reasoning: 자연어 한계를 극복하여 모델의 숨겨진 상태에서 직접 다단계 추론을 수행하는 잠재 추론 연구 분야를 종합적으로 정리한다.
7.4KAgent: 프로파일링-인식-복원 에이전트 구조로 256×256 극저해상도 이미지를 4K로 변환하는 통합 초해상도 시스템을 구현한다.
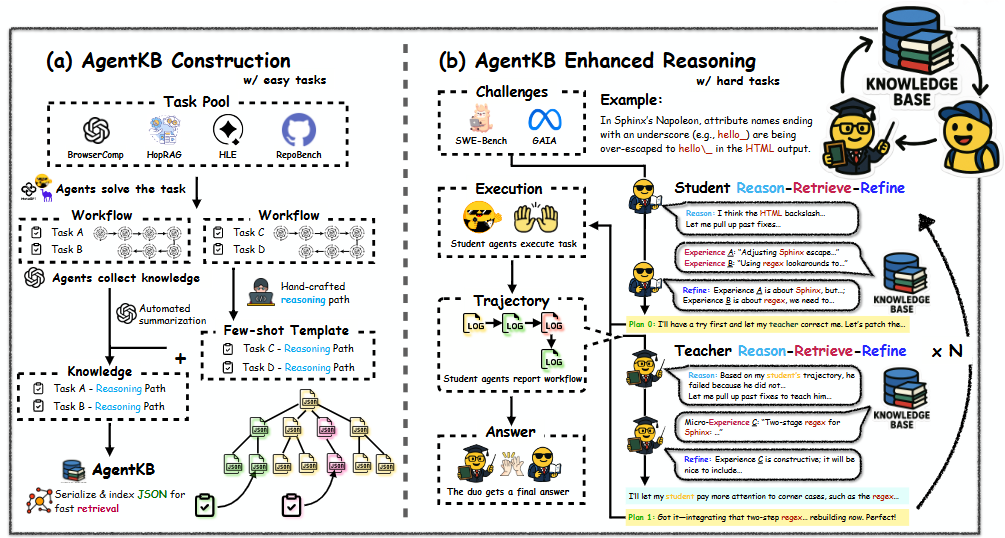
8.Agent KB: Reason-Retrieve-Refine 파이프라인으로 에이전트 간 경험 공유를 가능하게 하여 GAIA에서 최대 16.28%포인트 성능 향상을 달성한다.
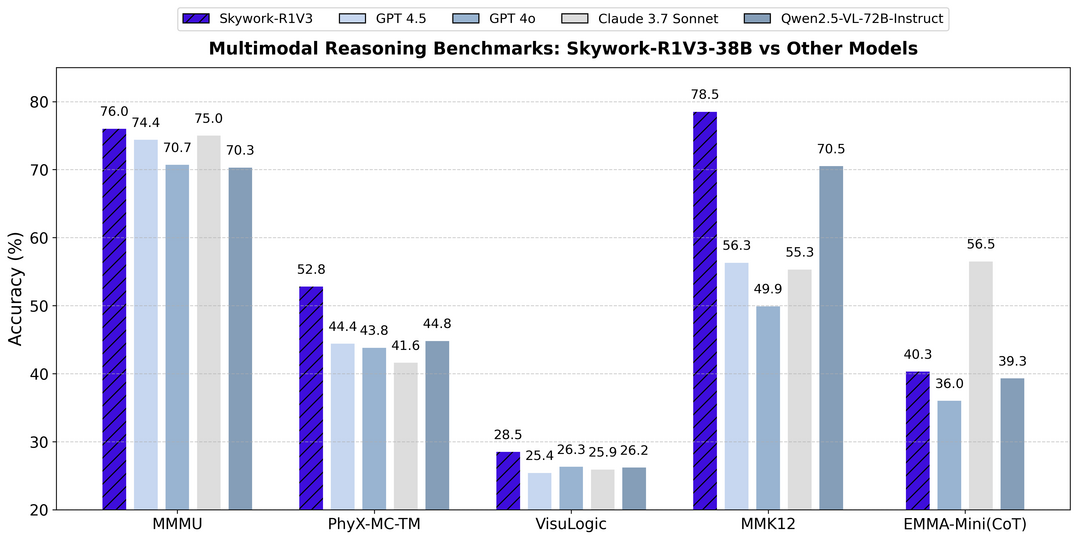
9.Skywork-R1V3: 강화학습 후훈련으로 텍스트 LLM의 추론 능력을 시각 작업에 전이하여 MMMU에서 76.0% 성능을 달성한다.
10.OmniPart: 자동회귀 구조 계획과 공간 조건부 생성으로 편집 가능한 부분 구조를 가진 3D 객체를 생성하는 프레임워크를 제안한다.
MemOS: A Memory OS for AI System
https://arxiv.org/abs/2507.03724
현재 대형 언어모델(LLM)은 정적 매개변수와 단기 맥락 상태에만 의존하여 장기적 추론, 지속적 개인화, 지식 일관성에 한계를 보인다. 이를 해결하기 위해 MemOS는 메모리를 관리 가능한 시스템 자원으로 취급하는 메모리 운영체제를 제안한다. MemCube라는 기본 단위를 통해 메모리 내용과 출처, 버전 등의 메타데이터를 캡슐화하고, 텍스트, 활성화 기반, 매개변수 수준의 메모리를 통합적으로 표현, 스케줄링, 진화시킨다. 이러한 접근을 통해 메모리 유형 간 유연한 전환과 검색-매개변수 학습 간의 연결을 가능하게 하여, LLM에 제어 가능성, 가소성, 진화성을 부여하는 메모리 중심 시스템 프레임워크를 구축한다.
SingLoRA: Low Rank Adaptation Using a Single Matrix
https://arxiv.org/abs/2507.05566
기존 LoRA는 두 개의 작은 행렬 곱으로 사전훈련된 가중치를 업데이트하는데, 이 행렬들 간의 스케일 차이로 인해 불안정한 훈련 역학과 차선의 성능을 보인다. SingLoRA는 단일 저순위 행렬과 그 전치행렬의 곱으로 가중치 업데이트를 분해하는 방식으로 저순위 적응을 재구성한다. 이 간단한 설계는 본질적으로 행렬 간 스케일 충돌을 제거하여 안정적인 최적화를 보장하고 매개변수 수를 대략 절반으로 줄인다. 무한 폭 신경망 프레임워크 내에서 SingLoRA를 분석한 결과 구조적으로 안정적인 특징 학습을 보장함을 보여주며, MNLI에서 LLama 7B를 미세조정했을 때 기존 LoRA(89.1%)와 LoRA+(90.2%)를 능가하는 91.3% 정확도를 달성하면서도 매개변수 예산의 60%만 사용한다.

Scaling RL to Long Videos
https://arxiv.org/abs/2507.07966
비전-언어 모델(VLM)의 긴 비디오 추론을 강화학습으로 확장하는 전체 스택 프레임워크를 제안한다. 스포츠, 게임, 브이로그 등 다양한 도메인에서 고품질 추론 주석을 가진 52K개의 긴 비디오 QA 쌍으로 구성된 LongVideo-Reason 데이터셋, 사고 연쇄 지도 미세조정과 강화학습을 결합한 2단계 훈련 파이프라인, 그리고 시퀀스 병렬화와 캐시된 비디오 임베딩을 활용하는 vLLM 기반 엔진을 포함하는 Multi-modal Reinforcement Sequence Parallelism(MR-SP) 훈련 인프라를 통합한다. LongVILA-R1-7B는 VideoMME 등 긴 비디오 QA 벤치마크에서 강력한 성능을 보이며, Video-R1-7B를 능가하고 심지어 Gemini-1.5-Pro와 시간적 추론, 목표 및 목적 추론, 공간적 추론, 플롯 추론에서 경쟁할 수준의 성능을 달성하고, MR-SP 시스템은 긴 비디오 강화학습 훈련에서 최대 2.1배의 속도 향상을 이룬다.

T-LoRA: Single Image Diffusion Model Customization Without Overfitting
https://arxiv.org/abs/2507.05964
확산 모델 미세조정은 특정 객체 생성을 위한 강력한 맞춤화 방법이지만, 훈련 샘플이 제한적일 때 과적합으로 인해 일반화 능력과 출력 다양성이 저하되는 문제가 있다. 가장 실용적 잠재력을 가진 단일 이미지 맞춤화 작업에 초점을 맞춰, 높은 확산 시간 단계가 낮은 시간 단계보다 과적합에 더 취약하다는 발견을 바탕으로 시간 단계에 민감한 미세조정 전략의 필요성을 제시한다. T-LoRA는 확산 시간 단계에 따라 순위 제약 업데이트를 조정하는 동적 미세조정 전략과 직교 초기화를 통해 어댑터 구성 요소 간 독립성을 보장하는 가중치 매개변수화 기법을 포함하는 시간 단계 의존적 저순위 적응 프레임워크를 도입하여, 개념 충실도와 텍스트 정렬 간의 우수한 균형을 달성한다.

Should We Still Pretrain Encoders with Masked Language Modeling?
https://arxiv.org/abs/2507.00994
고품질 텍스트 표현 학습은 광범위한 NLP 작업의 기본이지만, 전통적으로 마스크 언어 모델링(MLM)에 의존해온 인코더 사전훈련과 달리 인과 언어 모델링(CLM)으로 사전훈련된 디코더 모델을 인코더로 재활용하는 방식이 종종 더 나은 성능을 보인다는 최근 증거가 있어 이러한 이득이 CLM 목적함수의 본질적 장점인지 아니면 모델 및 데이터 규모 등의 혼재 요인에서 비롯되는지 불분명하다. 2억 1천만에서 10억 매개변수에 이르는 총 30개 모델을 훈련하고 15,000회 이상의 미세조정 및 평가를 수행한 대규모의 신중히 통제된 사전훈련 절제 연구를 통해, MLM으로 훈련하는 것이 일반적으로 텍스트 표현 작업에서 더 나은 성능을 제공하지만 CLM 훈련 모델이 더 데이터 효율적이고 향상된 미세조정 안정성을 보임을 발견하고, 고정된 계산 훈련 예산 하에서 CLM을 먼저 적용한 후 MLM을 순차적으로 적용하는 이단계 훈련 전략이 최적 성능을 달성함을 실험적으로 보여준다.
A Survey on Latent Reasoning
https://arxiv.org/abs/2507.06203
대형 언어모델(LLM)은 중간 단계를 언어화하는 명시적 사고 연쇄(CoT) 추론의 안내를 받을 때 인상적인 추론 능력을 보여주지만, CoT가 해석 가능성과 정확성을 향상시키는 반면 자연어 추론에 대한 의존성이 모델의 표현 대역폭을 제한한다. 잠재 추론은 토큰 수준 감독을 제거하고 모델의 연속적 숨겨진 상태에서 완전히 다단계 추론을 수행함으로써 이러한 병목 현상을 해결한다. 이 서베이는 추론을 위한 계산 기질로서 신경망 층의 기초적 역할을 검토하고 계층적 표현이 복잡한 변환을 지원하는 방식을 강조하며, 활성화 기반 순환, 숨겨진 상태 전파, 명시적 추론 추적을 압축하거나 내재화하는 미세조정 전략을 포함한 다양한 잠재 추론 방법론을 탐구하고, 전역적으로 일관되고 가역적인 추론 과정을 가능하게 하는 마스크 확산 모델을 통한 무한 깊이 잠재 추론과 같은 고급 패러다임을 논의하여 잠재 추론의 개념적 풍경을 통합하고 LLM 인지의 최전선에서 연구의 미래 방향을 제시한다.
4KAgent: Agentic Any Image to 4K Super-Resolution
https://arxiv.org/abs/2507.07105
4KAgent는 모든 이미지를 4K 해상도로 보편적으로 업스케일하도록 설계된 통합 에이전트 초해상도 일반화 시스템으로, 256×256의 극도로 왜곡된 입력과 같은 극저해상도에서 심각한 열화를 가진 이미지를 수정처럼 맑고 사실적인 4K 출력으로 변환할 수 있다. 맞춤형 사용 사례에 따라 4KAgent 파이프라인을 맞춤화하는 프로파일링 모듈, 비전-언어 모델과 이미지 품질 평가 전문가를 활용하여 입력 이미지를 분석하고 맞춤형 복원 계획을 수립하는 인식 에이전트, 그리고 각 단계에서 최적 출력을 선택하기 위한 품질 기반 전문가 혼합 정책의 안내를 받아 재귀적 실행-반성 패러다임을 따르며 계획을 실행하는 복원 에이전트의 세 가지 핵심 구성 요소로 이루어진다. 자연 이미지, 초상화 사진, AI 생성 콘텐츠, 위성 영상, 형광 현미경, 안저 촬영, 초음파, X선과 같은 의료 영상을 포함한 총 26개의 다양한 벤치마크를 아우르는 11개의 서로 다른 작업 범주에서 지각적(NIQE, MUSIQ) 및 충실도(PSNR) 지표 모두에서 우수한 성능을 보여주며 광범위한 이미징 도메인에서 새로운 최첨단 성능을 설정한다.

Agent KB: Leveraging Cross-Domain Experience for Agentic Problem Solving
https://arxiv.org/abs/2507.06229
언어 에이전트가 점점 복잡한 작업을 다루면서 효과적인 오류 수정과 도메인 간 경험 재사용에 어려움을 겪고 있으며, 전통적으로 에이전트들이 서로의 경험으로부터 학습할 수 없다는 핵심 한계를 해결하기 위해 Agent KB는 새로운 Reason-Retrieve-Refine 파이프라인을 통해 복잡한 에이전트 문제 해결을 가능하게 하는 계층적 경험 프레임워크를 도입한다. 고수준 전략과 세부 실행 로그를 모두 캡처함으로써 Agent KB는 에이전트 간 지식 전이를 가능하게 하는 공유 지식 베이스를 생성한다. GAIA 벤치마크에서 평가한 결과 Agent KB는 성공률을 최대 16.28 퍼센트 포인트 향상시키며, 가장 도전적인 작업에서 Claude-3이 38.46%에서 57.69%로, GPT-4가 중간 작업에서 53.49%에서 73.26%로 개선되고, SWE-bench 코드 수리에서 Claude-3이 41.33%에서 53.33%로 향상되어 Agent KB가 과거 경험으로부터 학습하고 성공적인 전략을 새로운 작업에 일반화할 수 있게 하는 모듈식, 프레임워크 무관 인프라를 제공함을 시사한다.
Skywork-R1V3 Technical Report
https://arxiv.org/abs/2507.06167
Skywork-R1V3는 시각적 추론에 대한 새로운 접근 방식을 개척하는 고급 오픈소스 비전-언어 모델(VLM)로, 텍스트 전용 대형 언어모델(LLM)의 추론 기술을 시각적 작업으로 효과적으로 전이하는 것이 핵심 혁신이다. 추가적인 지속 사전훈련 없이 모델의 추론 능력을 효과적으로 활성화하고 향상시키는 정교한 후훈련 강화학습 프레임워크에서 주로 강력한 성능이 나오며, 이 프레임워크를 통해 다중모달 추론 모델에서 견고한 교차 모달 정렬을 달성하는 데 있어 연결자 모듈의 근본적 역할을 추가로 발견한다. 강화학습 훈련 중 체크포인트 선택에 매우 효과적임이 입증된 추론 능력의 독특한 지표인 핵심 추론 토큰의 엔트로피를 도입하고, MMMU에서 64.3%에서 76.0%로 크게 향상되는 최첨단 결과를 달성하여 초급 수준의 인간 능력과 일치하며, 놀랍게도 강화학습 기반 후훈련 접근법을 통해 38B 매개변수 모델조차 최고 수준의 폐쇄형 VLM과 경쟁할 수 있게 하고 수학적 추론을 다른 주제 관련 추론 작업으로 성공적으로 전이시킨다.
OmniPart: Part-Aware 3D Generation with Semantic Decoupling and Structural Cohesion
https://arxiv.org/abs/2507.06165
명시적이고 편집 가능한 부분 구조를 가진 3D 자산 생성은 상호작용 애플리케이션 발전에 중요하지만 대부분의 생성 방법은 단일체 형태만 생산하여 유용성을 제한한다. OmniPart는 구성 요소 간 높은 의미적 분리를 달성하면서 견고한 구조적 결합을 유지하도록 설계된 부분 인식 3D 객체 생성을 위한 새로운 프레임워크를 도입한다. 직접적인 대응이나 의미적 레이블을 요구하지 않고 부분 분해에 대한 직관적 제어를 허용하는 유연한 2D 부분 마스크의 중요한 안내를 받아 제어 가능하고 가변 길이의 3D 부분 경계 상자 시퀀스를 생성하는 자동회귀 구조 계획 모듈과, 사전훈련된 전체론적 3D 생성기로부터 효율적으로 적응되어 계획된 레이아웃 내에서 모든 3D 부분을 동시에 일관되게 합성하는 공간 조건부 정류 흐름 모델의 두 가지 상승 작용 단계로 이 복잡한 작업을 독특하게 분리한다. 사용자 정의 부분 세분화, 정확한 위치 지정을 지원하고 다양한 후속 애플리케이션을 가능하게 하며, 광범위한 실험을 통해 OmniPart가 최첨단 성능을 달성하여 더 해석 가능하고 편집 가능하며 다재다능한 3D 콘텐츠의 길을 열어준다.

[METAX = 김한얼 기자]
[저작권자ⓒ META-X. 무단전재-재배포 금지]