Off-policy 학습·그래프 구조 최적화를 통해 지식 활용 효율성과 검색 기반 생성 성능 향상
TL;DR
학습 패러다임 및 추론 강화 분야에서는 기존 모델에 새로운 언어 지식을 효율적으로 통합하거나(Kuwain), 강화학습(RL)이 실제로 LLM의 추론 능력을 어떻게 향상시키는지 심층 분석하고(RL Reasoning), 테스트 시점(TTRL)이나 외부 전문가 데이터(LUFFY)를 활용하는 새로운 RL 패러다임을 탐구하는 연구들이 진행 중이다. 또한, 지식 그래프 구조 최적화(NodeRAG)를 통해 검색 증강 생성(RAG)의 효율과 성능을 높이려는 시도도 주목받는다.
멀티모달 지능 확장 분야에서는 시각과 언어를 함께 처리하는 능력은 더욱 정교해진다. 긴 비디오나 고해상도 이미지에 대한 이해도를 높이고(Eagle 2.5), 이미지 내 특정 객체나 영역에 대한 상세 설명을 생성하며(Describe Anything), 사용자 요구에 맞춰 고품질 이미지를 편집하는(Step1X-Edit) 등 멀티모달 모델의 표현력과 생성 능력을 확장하는 연구들이 활발하다.
에이전트 AI와 월드 모델링 분야에서는 AI가 특정 환경이나 도구를 자율적으로 사용하는 에이전트 기술도 발전한다. 데스크톱 환경에서의 복잡한 작업을 자동화하는 에이전트(UFO2)의 실용성을 높이는 연구와 함께, 환경의 동역학을 학습하는 '월드 모델'을 신경망과 기호적 지식으로 결합하여(WALL-E 2.0) 에이전트의 계획 및 실행 능력을 근본적으로 향상시키려는 노력이 이루어지고 있다.
평가 방법론 및 벤치마킹 분야에서는 AI 모델의 실제 역량을 정확하고 공정하게 측정하는 것 또한 중요한 연구 주제다. 언어적 편향 없이 순수한 시각적 추론 능력을 평가하기 위한 새로운 벤치마크(VisuLogic)가 제안되었으며, 기존 다국어 평가 데이터셋들의 한계를 분석하고(Bitter Lesson) 문화적, 언어적 다양성을 반영하는 더 나은 평가 체계 구축의 필요성이 강조되고 있다.
1.학습 패러다임 및 추론 강화 분야
Kuwain 1.5B: An Arabic SLM via Language Injection
https://arxiv.org/abs/2504.15120
이 논문은 주로 영어로 훈련된 기존 소규모 LLM에 아랍어를 '주입'하여 15억 파라미터의 'Kuwain' 모델을 훈련시키는 새로운 언어 통합 방법을 제안한다. 이 접근법은 기존 모델의 지식을 손상시키지 않으면서 아랍어 성능을 평균 8% 향상시켰으며, 원본 데이터를 최소한으로 사용하여 영어와 아랍어를 모두 지원하는 모델을 처음부터 훈련하는 것보다 비용 효율적인 대안을 제공하여, 대규모 재훈련 없이 특정 언어 능력을 효율적으로 확장할 수 있음을 입증한다.
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
https://arxiv.org/abs/2504.13837
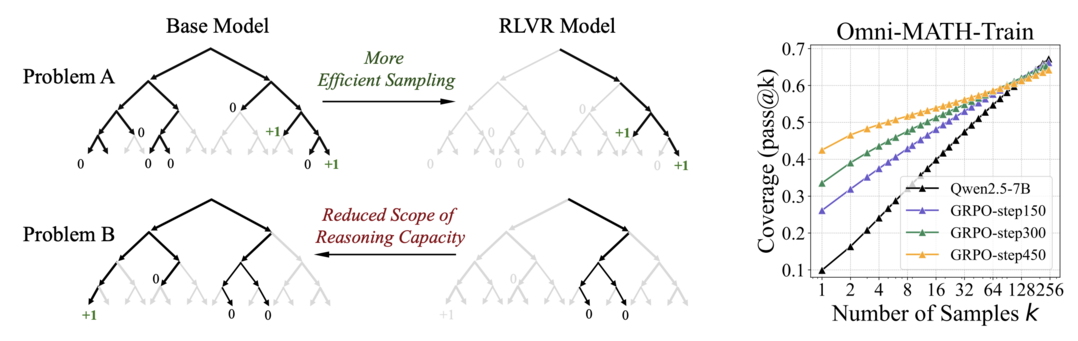
이 연구는 널리 알려진 믿음과 달리 강화학습(특히 RLVR)이 LLM에게 기본 모델의 능력을 근본적으로 넘어서는 새로운 추론 능력을 부여하지 못한다는 사실을 pass@k 지표(특히 큰 k값) 분석을 통해 밝혀낸다. RL 훈련은 새로운 추론 경로를 창조하기보다는 기본 모델이 이미 샘플링할 수 있는 경로 중 보상을 받을 가능성이 높은 경로를 더 효율적으로 찾도록 '편향'시키는 역할을 하지만, 이 과정에서 오히려 추론 능력의 전체 범위는 좁아질 수 있다는 한계를 지적하며 LLM 추론 능력 향상을 위한 RL의 역할 재고 및 새로운 패러다임 모색의 필요성을 강조한다.
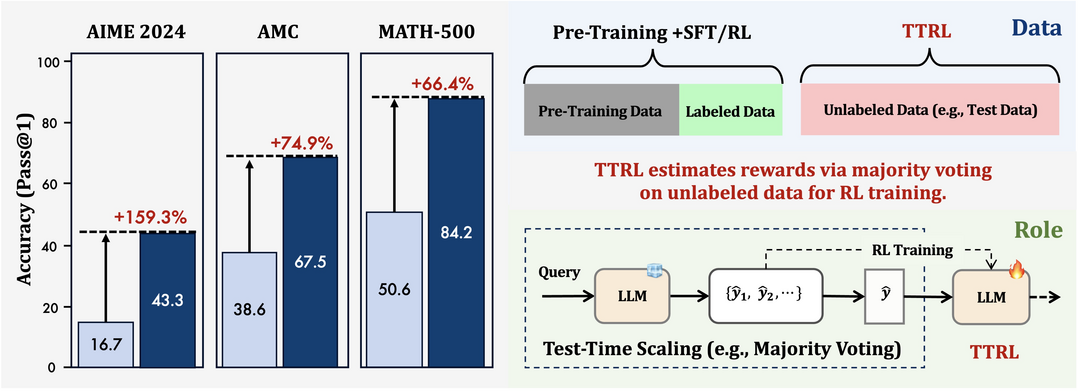
TTRL: Test-Time Reinforcement Learning
https://arxiv.org/abs/2504.16084
이 논문은 정답 라벨이 없는 데이터 환경에서 LLM의 추론 능력을 향상시키기 위해, 실제 추론(테스트) 단계에서 강화학습을 적용하는 새로운 방법론 'TTRL(Test-Time Reinforcement Learning)'을 제안한다. TTRL은 '다수결 투표(Majority Voting)'와 같은 테스트 시 스케일링 기법을 활용하여 정답 없이도 효과적인 보상 신호를 생성하고 이를 바탕으로 모델이 스스로 성능을 개선하도록 유도하고, 실험을 통해 라벨 없는 데이터만으로도 특정 수학 벤치마크에서 괄목할 만한 성능 향상(약 159%)을 보이고 초기 모델의 성능 상한선을 넘어 라벨 기반 훈련 모델에 근접하는 등 다양한 작업에서의 일반적인 효과와 잠재력을 입증한다.
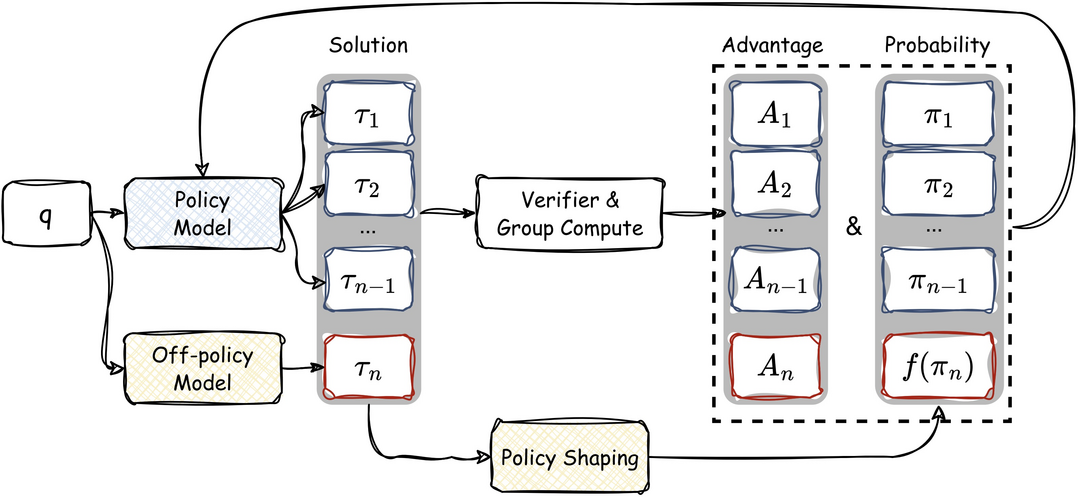
Learning to Reason under Off-Policy Guidance
https://arxiv.org/abs/2504.14945
기존 '온-폴리시(on-policy)' 강화학습이 모델의 초기 능력을 넘어서는 추론 능력 획득에 한계가 있다는 점을 지적하고, 외부의 모범 추론 사례('off-policy guidance')와 모델 자체의 탐색 결과('on-policy rollout')를 동적으로 결합하여 학습하는 'LUFFY' 프레임워크를 제안한다. LUFFY는 정규화된 중요도 샘플링을 통한 정책 형성 기법을 도입하여 피상적인 모방을 방지하고 탐색을 장려하고, 실험 결과 여러 수학 벤치마크와 분포 외(OOD) 작업에서 상당한 성능 향상을 달성하고 특히 일반화 능력에서 단순 모방 학습(SFT)을 크게 능가함으로써, 오프-폴리시 지도를 활용한 확장 가능하고 일반화 성능이 우수한 추론 모델 훈련 방법론의 가능성을 제시한다.
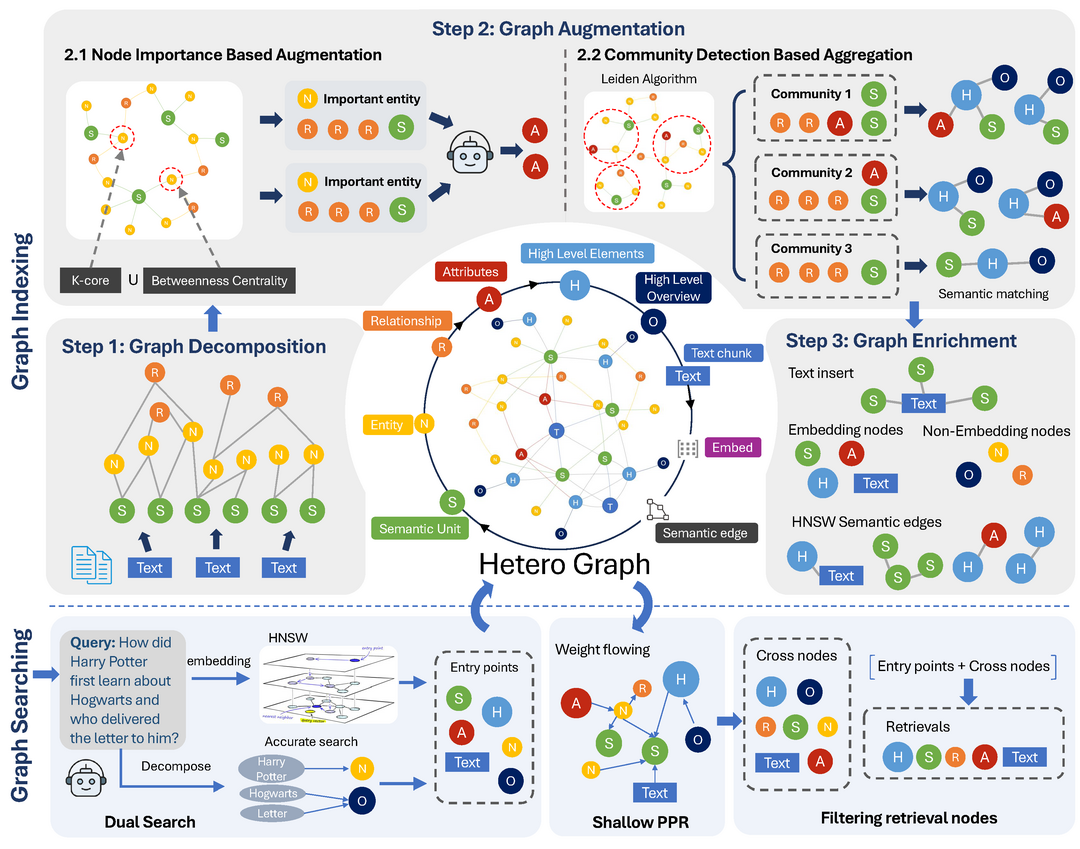
NodeRAG: Structuring Graph-based RAG with Heterogeneous Nodes
https://arxiv.org/abs/2504.11544
기존 그래프 기반 검색 증강 생성(RAG) 방식들이 종종 그래프 구조 자체의 설계에는 소홀하여 잠재력을 충분히 발휘하지 못한다는 문제의식 하에, RAG 워크플로우에 그래프 기반 방법론을 보다 원활하고 효과적으로 통합하기 위해 다양한 종류의 노드와 관계를 포함하는 '이기종(heterogeneous) 그래프 구조'를 핵심으로 도입하는 그래프 중심 프레임워크 'NodeRAG'를 제안한다. NodeRAG는 LLM의 능력과 긴밀하게 연계되도록 설계되어 종단 간 프로세스의 효율성을 높이고, 광범위한 실험을 통해 기존 GraphRAG 및 LightRAG 대비 인덱싱/쿼리 시간 및 저장 효율성뿐만 아니라, 특히 다중 홉(multi-hop) 질의응답 성능에서 더 적은 검색 토큰으로도 우위를 보이며 그래프 기반 RAG의 성능을 한 단계 끌어올린다.
2. 멀티모달 지능 확장 분야
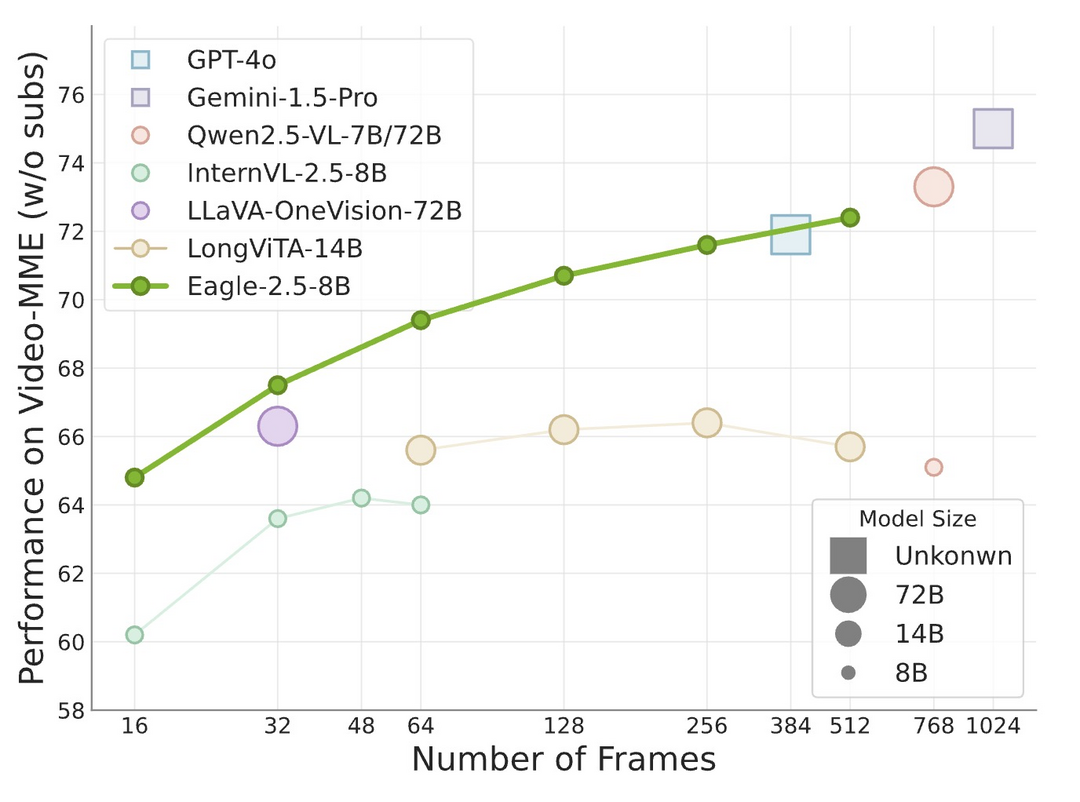
Eagle 2.5: Boosting Long-Context Post-Training for Frontier Vision-Language Models
https://arxiv.org/abs/2504.15271
이 연구는 긴 비디오 이해와 고해상도 이미지 처리와 같은 '긴 맥락(long-context)' 멀티모달 학습 능력을 강화한 최첨단 시각-언어 모델(VLM) 제품군 'Eagle 2.5'를 소개한다. 문맥적 무결성과 시각적 세부 사항을 보존하는 '자동 품질 저하 샘플링' 및 '이미지 영역 보존' 기법, 긴 맥락 데이터 처리를 위한 효율적인 훈련 파이프라인 최적화, 그리고 긴 비디오 이해를 돕는 새로운 'Eagle-Video-110K' 데이터셋 구축을 통해 개발되었고, Eagle 2.5-8B 모델은 주요 긴 비디오 벤치마크(Video-MME)에서 최고 수준의 상용 및 오픈소스 모델들과 견줄 만한 성능을 달성하여 기존 VLM의 한계를 극복하는 강력한 솔루션을 제시한다.
Describe Anything: Detailed Localized Image and Video Captioning
https://arxiv.org/abs/2504.16072
이미지나 비디오의 특정 영역에 대해 상세하고 정확한 설명을 생성하는 '상세 지역화 캡셔닝(DLC)'이 시각-언어 모델의 중요 과제임을 인식하여, 이를 위해 'DAM(Describe Anything Model)'을 제안한다. DAM은 목표 영역의 세부 정보를 고해상도로 인코딩하는 '초점 프롬프트'와 정밀한 위치 정보를 주변 맥락과 통합하는 '지역화된 비전 백본'이라는 두 가지 핵심 혁신을 통해 지역적 세부 사항과 전역적 맥락을 모두 효과적으로 보존하고, 고품질 DLC 데이터 부족 문제를 해결하기 위해 준지도학습 기반 데이터 파이프라인(DLC-SDP)을 개발하고 참조 캡션 없이 평가 가능한 DLC-Bench를 도입하여 7개의 관련 벤치마크에서 최고 성능(SOTA)을 달성했다.

Step1X-Edit: A Practical Framework for General Image Editing
https://arxiv.org/abs/2504.17761
최근 GPT-4o, Gemini Flash 등 최첨단 비공개 멀티모달 모델들이 뛰어난 이미지 편집 능력을 보여주는 반면 오픈소스 모델과의 성능 격차가 크다는 점에 주목하고, 이 간극을 메우기 위한 고성능 오픈소스 이미지 편집 모델 'Step1X-Edit'을 개발하고 공개한다. Step1X-Edit은 멀티모달 LLM을 사용하여 원본 이미지와 사용자의 편집 지시사항을 처리하고, 추출된 잠재 임베딩을 확산 이미지 디코더와 통합하여 목표 이미지를 생성하고, 자체 구축한 고품질 데이터 생성 파이프라인으로 훈련되고 실제 사용자 지침에 기반한 GEdit-Bench 평가에서 기존 오픈소스 모델들을 큰 차이로 능가하고 선도적인 상용 모델 성능에 근접함을 입증하여 이미지 편집 분야 발전에 기여한다.

3. 에이전트 AI와 월드 모델링 분야
UFO2: The Desktop AgentOS
https://arxiv.org/abs/2504.14603
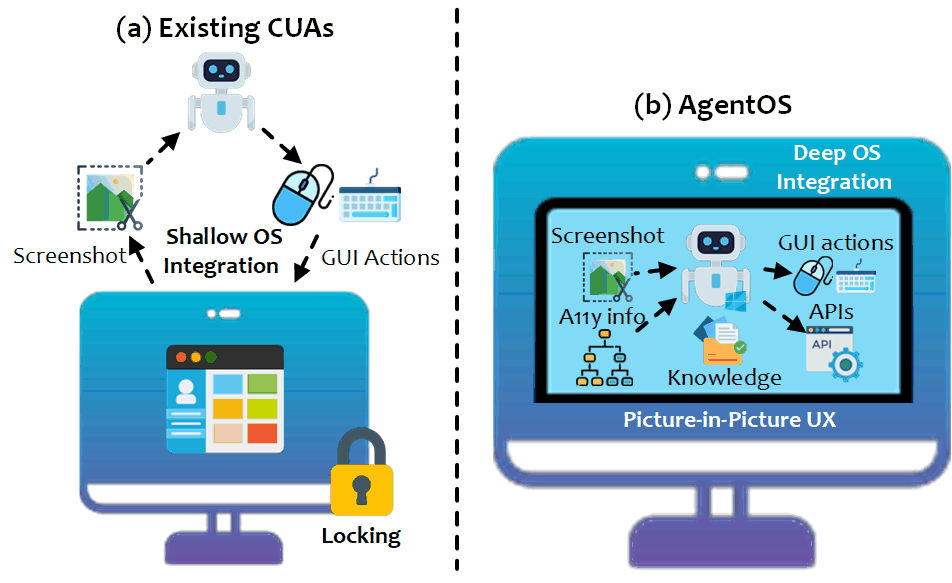
자연어로 복잡한 데스크톱 작업을 자동화하는 컴퓨터 사용 에이전트(CUA)가 아직 개념 증명 수준에 머물고 얕은 OS 통합, 불안정한 스크린샷 기반 상호작용, 사용자 작업 방해 등의 한계를 보이는 상황을 개선하기 위해, 실용적인 시스템 수준 자동화를 목표로 하는 윈도우 데스크톱용 멀티 에이전트 'AgentOS'인 UFO2를 개발했다. UFO2는 중앙 집중식 HostAgent가 작업을 조율하고 다수의 애플리케이션 특화 AppAgent가 네이티브 API, 도메인 지식, 통합 GUI-API 액션 레이어를 활용하여 작업을 수행하는 구조를 가지고 있으며, 하이브리드 제어 감지 파이프라인, 추측적 다중 행동 계획, 그리고 사용자와 에이전트의 동시 작업을 가능케 하는 PIP 인터페이스 등을 통해 20개 이상의 실제 윈도우 애플리케이션 환경에서 기존 CUA 대비 향상된 안정성과 실행 정확도를 입증하며 깊은 OS 통합이 신뢰성 있는 자동화의 핵심임을 강조한다.
WALL-E 2.0: World Alignment by NeuroSymbolic Learning improves World Model-based LLM Agents
https://arxiv.org/abs/2504.15785
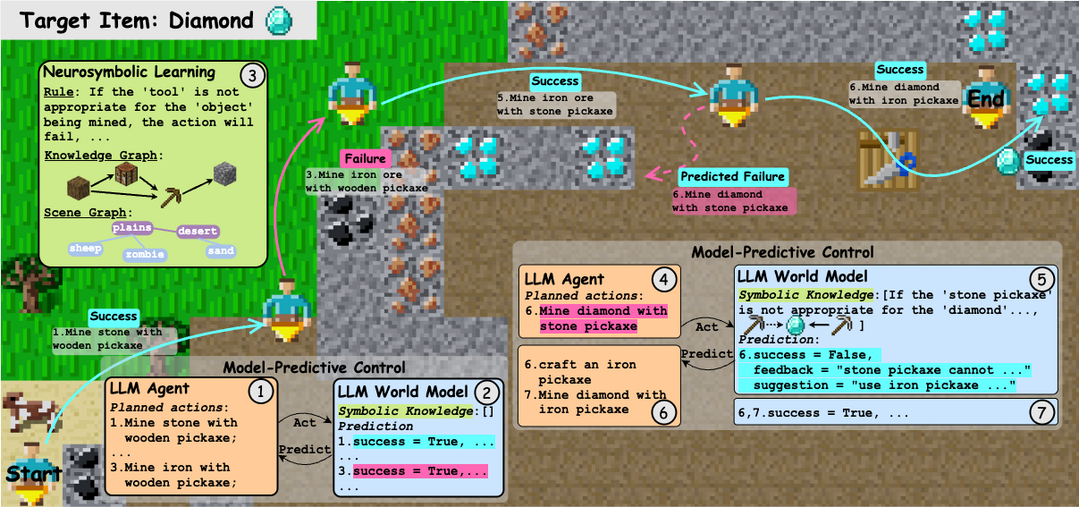
대규모 언어 모델(LLM)의 사전 지식과 특정 환경의 동역학 사이의 불일치가 LLM 기반 월드 모델 및 에이전트 성능의 병목이 된다는 점을 해결하기 위해, 별도의 훈련 없이 환경의 행동 규칙, 지식 그래프 등 상징적 지식을 학습하여 LLM의 지식을 보완하는 '월드 정렬(World Alignment)' 개념과 이를 활용하는 강화학습(RL) 없는 모델 예측 제어(MPC) 기반 에이전트 'WALL-E 2.0'을 제안한다. WALL-E 2.0은 LLM 에이전트를 효율적인 미래 행동 계획자(look-ahead optimizer)로 사용하고 이를 정확하게 정렬된 신경-상징적 월드 모델과 상호작용시켜 계획의 효율성과 정확성을 동시에 확보하고, Mars(마인크래프트 유사) 및 ALFWorld(실내 환경)와 같은 도전적인 환경에서 기존 방법들을 성공률과 점수 면에서 큰 폭으로 능가하고 특히 ALFWorld에서는 단 4번의 반복만으로 98%라는 최고 수준의 성공률을 달성하여 새로운 환경에서의 빠른 학습 능력과 효과를 입증했다.
4. 평가 방법론 및 벤치마킹 분야
VisuLogic: A Benchmark for Evaluating Visual Reasoning in Multi-modal Large Language Models
https://arxiv.org/abs/2504.15279
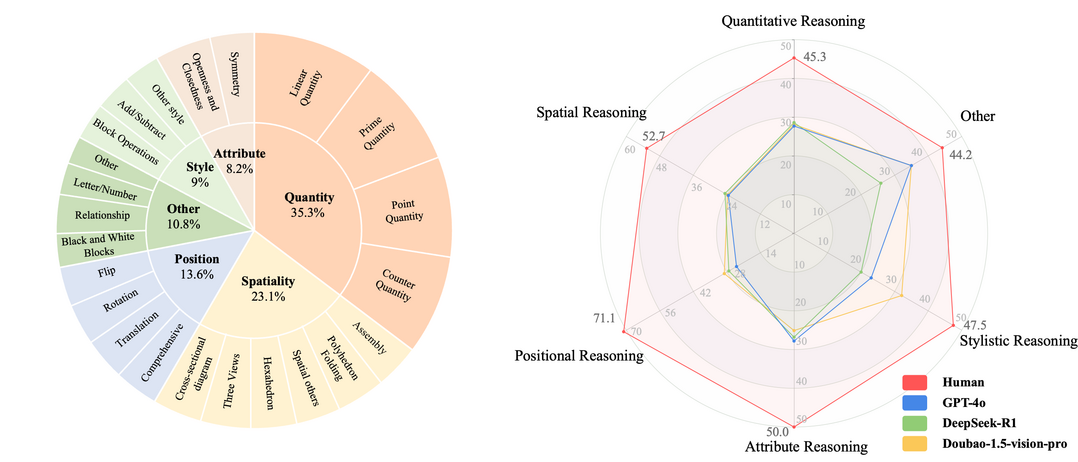
현재 멀티모달 대형 언어 모델(MLLM)의 시각적 추론 능력 평가가 텍스트 정보에 의존하여 언어적 '꼼수(shortcut)'를 허용하고 진정한 시각 기반 추론을 측정하지 못하는 한계를 지적하고, 이를 해결하기 위해 'VisuLogic'이라는 새로운 벤치마크를 제안한다. VisuLogic은 양적 변화, 공간 관계 등 6가지 범주에 걸쳐 인간이 검증한 1,000개의 문제로 구성되어 MLLM의 시각적 추론 능력을 다각도로 평가하도록 설계되었으며, 주요 MLLM 평가 결과 무작위 추측(25%)보다 약간 높은 30% 미만의 낮은 정확도를 보여 인간(51.4%)과의 현저한 격차를 드러냈으며, 향후 연구 지원을 위해 관련 훈련 데이터셋과 강화학습 기반 베이스라인 모델을 함께 제공한다.
The Bitter Lesson Learned from 2,000+ Multilingual Benchmarks
https://arxiv.org/abs/2504.15521
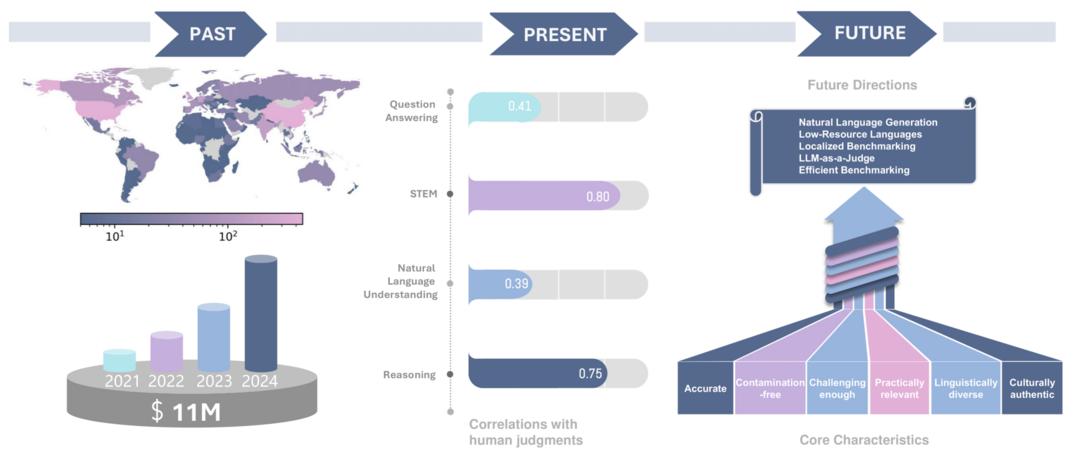
이 연구는 2021년부터 2024년까지 148개국에서 발표된 2,000개 이상의 비영어권 다국어 벤치마크를 포괄적으로 분석하여 현재 다국어 LLM 평가 방식의 문제점을 진단한다. 상당한 투자에도 불구하고 여전히 영어가 과도하게 대표되고 있으며, 대부분의 벤치마크가 고자원 국가의 원어 콘텐츠에 의존하고, 벤치마크 점수와 인간의 실제 판단(특히 전통적 NLP 작업) 사이에 상당한 불일치가 존재하며, 단순 번역보다는 문화·언어적으로 맞춤화된 현지 벤치마크가 인간 판단과 훨씬 더 잘 일치한다는 점 등 6가지 주요 한계를 지적한다. 이를 바탕으로 효과적인 다국어 벤치마킹을 위한 지침 원칙과 향후 연구 방향을 제시하고, 실제 응용을 우선시하고 인간의 판단과 잘 맞는 벤치마크 개발을 위한 전 세계적인 협력을 촉구한다.
[METAX = 김한얼 기자]
[저작권자ⓒ META-X. 무단전재-재배포 금지]