고정된 데이터셋을 넘어, 모델의 성장을 돕는 역동적인 학습 환경까지 구축하며 발전 가속
TL;DR
LLM 추론 능력 강화 및 최적화 분야에서는 스스로 실패 원인을 분석하고 재도전하여 학습하거나(Reflect, Retry, Reward), 장시간의 강화 학습을 통해 기존에 없던 새로운 추론 능력을 만들어내고(ProRL), 추론 과정에 결정적인 소수의 토큰만 집중 학습하여 효율을 극대화하며(Beyond the 80/20 Rule), 필요할 때만 깊게 생각하는 방식으로 성능과 효율을 모두 잡는(AlphaOne) 등 강화 학습을 활용해 LLM의 추론 능력을 한 단계 끌어올리는 연구들이 소개되었다.
시각과 언어가 통합된 멀티모달 AI 분야에서는 최신 비디오 모델이 시간의 흐름에 따른 변화는 인지하지 못하는 '시간맹' 상태임을 지적하거나(Time Blindness), 하나의 모델로 이미지 이해, 생성, 편집까지 모두 처리하는 프레임워크를 제안하고(UniWorld), 작고 효율적인 모델로 누구나 고성능 로봇 제어를 연구할 수 있도록 문턱을 낮추며(SmolVLA), 방대한 데이터와 강화학습으로 기존 모델들을 압도하는 초고성능 비전-언어 모델을 공개하는(MiMo-VL) 등 시각과 언어를 통합하는 멀티모달 분야의 발전이 다뤄졌다.
데이터셋 생태계 구축 분야에서는 기존의 고정된 데이터셋에서 벗어나, 모델의 수준에 맞춰 무한에 가까운 추론 문제를 생성하여 체계적인 학습과 평가를 가능하게 하는 새로운 학습 환경(REASONING GYM)이 제안되었다.
LLM 추론 능력 강화 및 최적화
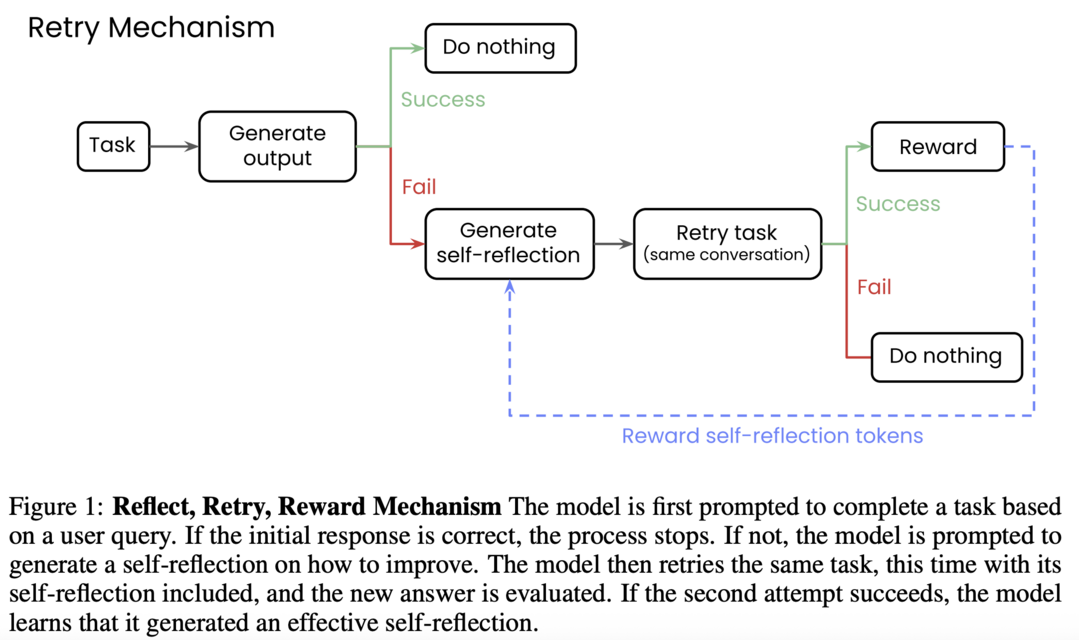
Reflect, Retry, Reward: Self-Improving LLMs via Reinforcement Learning
https://arxiv.org/abs/2505.24726
이 논문은 대규모 언어 모델이 주어진 과제에 실패했을 때, 스스로 실패 원인을 분석하는 '성찰' 텍스트를 생성하고 이를 바탕으로 재도전하여 성공하면 강화 학습으로 보상하는 2단계 프레임워크를 제안한다. 이 '성찰, 재시도, 보상'의 순환 구조를 통해 모델은 외부의 복잡한 피드백 없이 오직 성공/실패라는 이진 정보만으로도 스스로 학습하며, 수학 문제 풀이나 함수 호출과 같은 복잡한 작업에서 10배 이상 큰 모델을 능가하는 등 상당한 성능 향상을 이룰 수 있음을 보여준다.
ProRL: Prolonged Reinforcement Learning Expands Reasoning Boundaries in Large Language Models
https://arxiv.org/abs/2505.24864
이 논문은 강화 학습이 단순히 모델에 내재된 능력을 증폭시키는 것을 넘어 실제로 새로운 추론 능력을 만들어낼 수 있는지 탐구하며, 'ProRL(장기 강화 학습)'이라는 방법론을 제시한다. 다양한 과제와 정교한 제어 기법을 동원해 모델을 오랜 시간 학습시킨 결과, 기존 모델이 수많은 시도에도 풀지 못했던 문제에 대한 새로운 해결책을 발견하는 등 추론의 경계 자체가 확장되는 것을 확인했으며, 이는 충분한 시간과 연산을 투입한 강화 학습이 언어 모델의 근본적인 추론 한계를 넘어설 수 있다는 가능성을 시사한다.
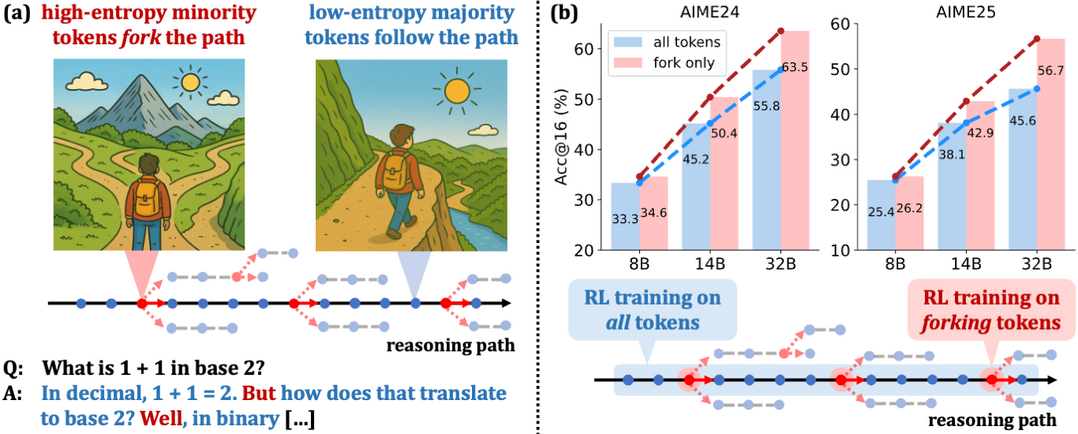
Beyond the 80/20 Rule: High-Entropy Minority Tokens Drive Effective Reinforcement Learning for LLM Reasoning
https://arxiv.org/abs/2506.01939
이 연구는 강화 학습이 언어 모델의 추론 능력을 향상시키는 원리를 '토큰 엔트로피' 관점에서 분석하여, 추론 과정의 방향을 결정하는 소수의 결정적인 '고엔트로피 토큰'이 존재함을 밝혀냈다. 실험을 통해 전체 토큰이 아닌, 이처럼 중요한 분기점 역할을 하는 20%의 소수 토큰에만 학습을 집중시켰을 때 전체를 학습시킨 것보다 오히려 더 높은 성능을 달성할 수 있음을 증명했으며, 이는 강화 학습의 효율성이 핵심적인 소수 토큰을 최적화하는 데서 비롯된다는 새로운 사실을 입증한다.
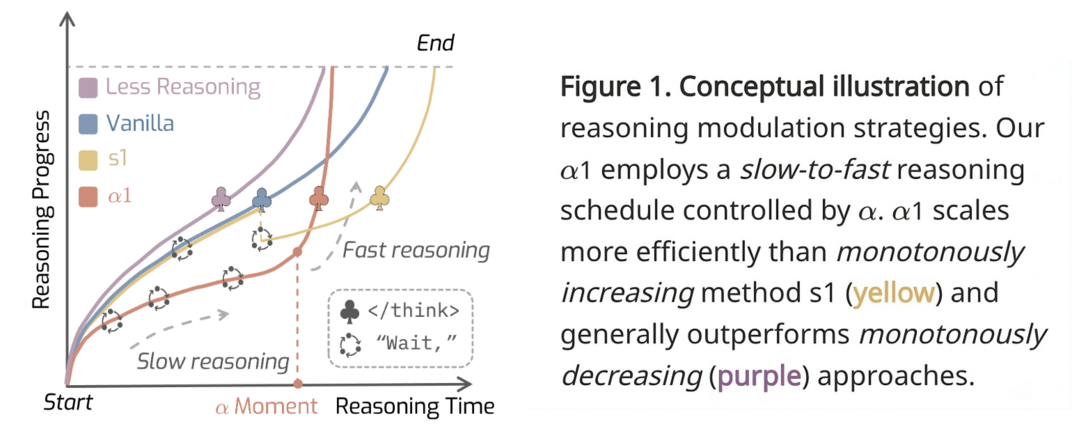
AlphaOne: Reasoning Models Thinking Slow and Fast at Test Time
https://arxiv.org/abs/2505.24863
이 연구는 모델이 추론을 수행하는 테스트 시점에서 '느린 사고'와 '빠른 사고'를 유연하게 조절하는 범용 프레임워크 'AlphaOne'을 제안한다. 이 프레임워크는 '알파 모멘트'라는 개념을 통해 깊이 있는 사고가 필요한 구간에서는 추론 토큰을 동적으로 삽입해 신중하게 생각하게 하고, 이후 단계에서는 신속하게 정답을 생성하도록 전환함으로써, 다양한 추론 벤치마크에서 기존 방식들보다 뛰어난 성능과 효율성을 동시에 달성하는 새로운 접근법을 보여준다.
시각과 언어가 통합된 멀티모달 AI 분야
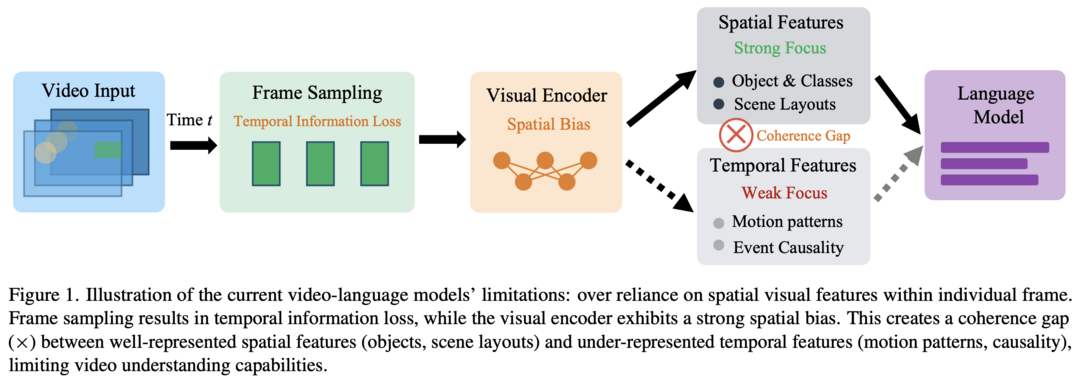
Time Blindness: Why Video-Language Models Can't See What Humans Can?
https://arxiv.org/abs/2505.24867
이 연구는 최신 비디오-언어 모델들이 프레임 속 공간 정보에는 뛰어나지만, 오직 시간의 흐름 속에만 인코딩된 정보는 전혀 인식하지 못하는 '시간맹(Time Blindness)'이라는 근본적인 한계를 지적한다. 연구진이 직접 개발한 'SpookyBench' 벤치마크를 통해 인간은 98% 이상 인식하는 시간적 패턴을 최첨단 모델들은 0%의 정확도로 전혀 감지하지 못함을 보여주었으며, 이는 현재 모델들이 공간적 특징과 시간적 처리를 분리하지 못하는 심각한 약점을 가지고 있음을 명확히 드러낸다.
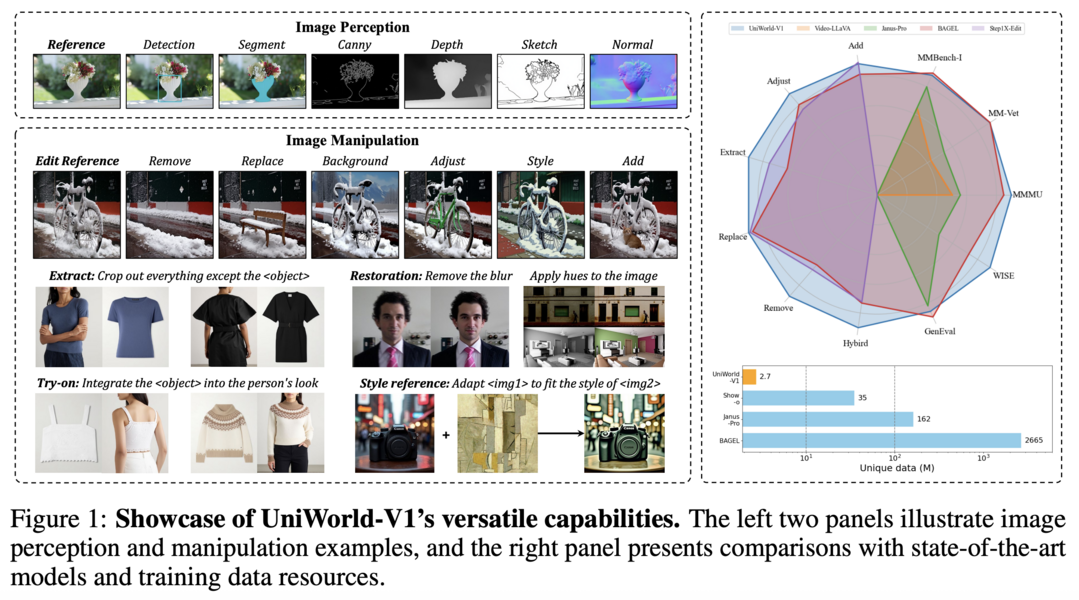
UniWorld: High-Resolution Semantic Encoders for Unified Visual Understanding and Generation
https://arxiv.org/abs/2506.03147
이 연구는 이미지 이해, 생성, 편집을 하나의 모델로 통합하기 위해, 기존의 VAE 방식 대신 강력한 비전-언어 모델의 '시맨틱 인코더' 특징을 활용하는 새로운 프레임워크 'UniWorld'를 제안한다. 이 접근법을 통해 경쟁 모델보다 100배나 적은 데이터만으로도 이미지 편집 성능을 능가했으며, 동시에 뛰어난 이미지 이해 및 생성 능력을 유지함으로써, 시맨틱 특징을 활용하는 것이 다양한 시각적 과제를 아우르는 강력한 통합 모델을 구축하는 데 매우 효과적인 전략임을 입증한다.
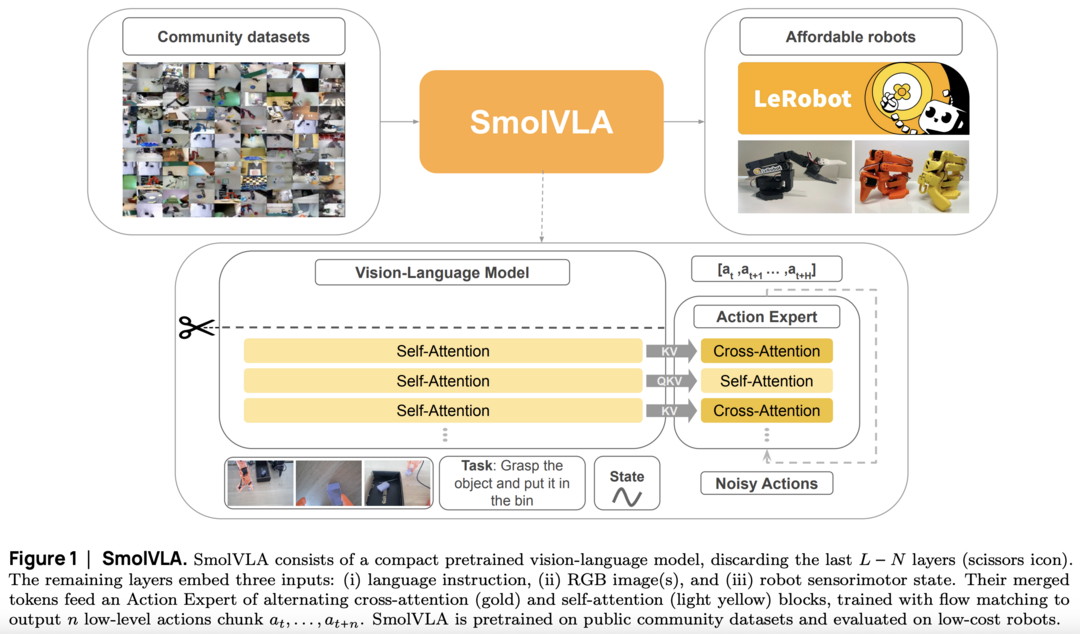
SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics
https://arxiv.org/abs/2506.01844
이 논문은 기존 로보틱스 모델들이 너무 크고 비싸 실제 환경에 적용하기 어려운 문제를 해결하기 위해, 작고 효율적인 비전-언어-행동 모델인 'SmolVLA'를 제시한다. 단일 GPU에서도 훈련 가능하고 일반 PC에서도 구동될 수 있도록 설계된 이 모델은, 크기가 10배 이상 큰 모델들과 비교해도 뒤지지 않는 경쟁력 있는 성능을 달성했으며, 이를 통해 더 적은 비용과 자원으로도 고성능 로봇 제어 기술을 연구하고 배포할 수 있는 길을 열어준다.
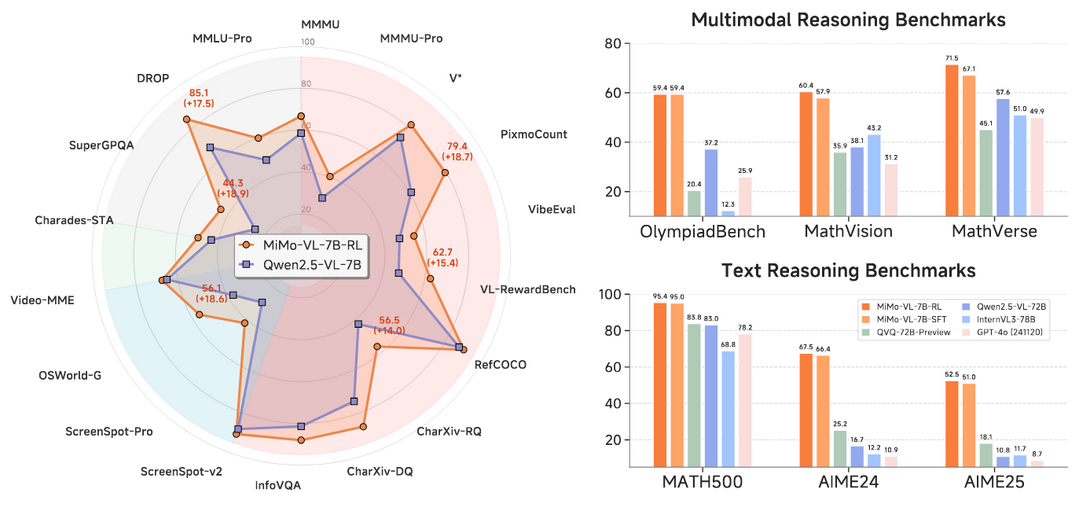
MiMo-VL Technical Report
https://arxiv.org/abs/2506.03569
이 문서는 샤오미가 개발한 최첨단 오픈소스 비전-언어 모델 'MiMo-VL'의 기술적 성과를 상세히 보고한다. 2.4조 개의 방대한 토큰으로 4단계에 걸쳐 사전 훈련하고, 다양한 보상 신호를 결합한 혼합 정책 강화 학습(MORL)을 적용하여, 경쟁 모델들을 압도하고 수십억 개 더 많은 파라미터를 가진 모델보다도 높은 성능을 달성했으며, GUI 제어와 같은 전문 분야에서도 새로운 최고 기록을 세우는 등 강력한 범용 시각 및 추론 능력을 갖추었음을 알린다.
데이터셋 생태계 구축
REASONING GYM: Reasoning Environments for Reinforcement Learning with Verifiable Rewards
https://arxiv.org/abs/2505.24760
이 논문은 기존의 고정된 데이터셋의 한계를 극복하기 위해, 'Reasoning Gym(RG)'이라는 새로운 추론 학습 환경 라이브러리를 소개한다. RG는 절차적 생성 방식을 통해 대수학, 논리학, 게임 등 다양한 영역에서 난이도 조절이 가능한 훈련 데이터를 거의 무한하게 생성할 수 있으며, 이를 통해 언어 모델의 수준에 맞춰 지속적으로 과제를 제공함으로써 추론 능력을 더욱 체계적이고 효과적으로 훈련하고 평가할 수 있는 환경을 제공한다.

[METAX = 김한얼 기자]
[저작권자ⓒ META-X. 무단전재-재배포 금지]