영상·음성 공간 넘나드는 멀티모달 생성에서 AI 평가 체계 개혁까지, 넓어지는 응용 영역
TL;DR
AI 추론 및 효율성 최적화 분야에서는 극소량의 데이터만으로 강화학습을 통해 추론 능력을 극대화하거나(1-Shot RLVR), 복잡한 추론 과정을 보조하는 특화된 정보 검색기를 개발하고(ReasonIR), 다양한 종류의 데이터를 함께 처리하며 추론하는 멀티모달 모델의 능력을 고도화하는(Skywork R1V2) 연구가 진행 중이다. 더불어, 1비트 언어 모델의 활성화 함수를 4비트로 정밀하게 양자화하여 메모리 및 계산 효율을 극대화하는(BitNet v2) 등 모델 경량화 및 최적화 연구도 중요한 축을 이루고 있다.
멀티모달 인식 및 생성 분야에서는 비디오 속 카메라의 동적인 움직임을 깊이 있게 이해하고 분석하며(Camera Motions), 텍스트, 이미지, 비디오 등 다양한 형태와 세분성을 가진 정보 소스를 효과적으로 통합하여 활용하는 차세대 검색 증강 생성(UniversalRAG) 기술이 개발되고 있다. 또한, 3차원 공간의 시간적 변화까지 모델링하는 4D 세계 모델을 학습하거나(TesserAct), 자연어 지시에 따라 이미지를 정교하게 편집하고(In-Context Edit), 영상 속 인물의 입 모양을 오디오에 맞춰 사실적으로 생성하며(KeySync), 여러 화자의 공간 음향 정보까지 보존하며 실시간으로 번역하는(Spatial Speech Translation) 등 멀티모달 데이터 처리 및 생성 능력이 고도화되고 있다.
AI 평가, 신뢰성 및 특화 응용 분야에서는 현재 널리 사용되는 AI 성능 리더보드의 잠재적 편향성과 구조적 문제를 비판적으로 분석하고 개선 방향을 제시하는 연구(Leaderboard Illusion)가 이루어졌다. 이와 함께, 범용 AI뿐만 아니라 특정 언어(아랍어)의 고유한 문제(발음 부호 표기)를 해결하기 위해 특화된 경량 모델을 개발하고, 해당 분야의 새로운 표준 평가 데이터셋(벤치마크)을 구축하여 연구 커뮤니티의 발전을 도모하는(Sadeed) 등, 특정 응용 분야에서의 AI 성능 향상 및 엄밀한 평가 체계 수립 노력이 병행되고 있다.
1. AI 추론 및 효율성 최적화 분야
Reinforcement Learning for Reasoning in Large Language Models with One Training Example
https://arxiv.org/abs/2504.20571
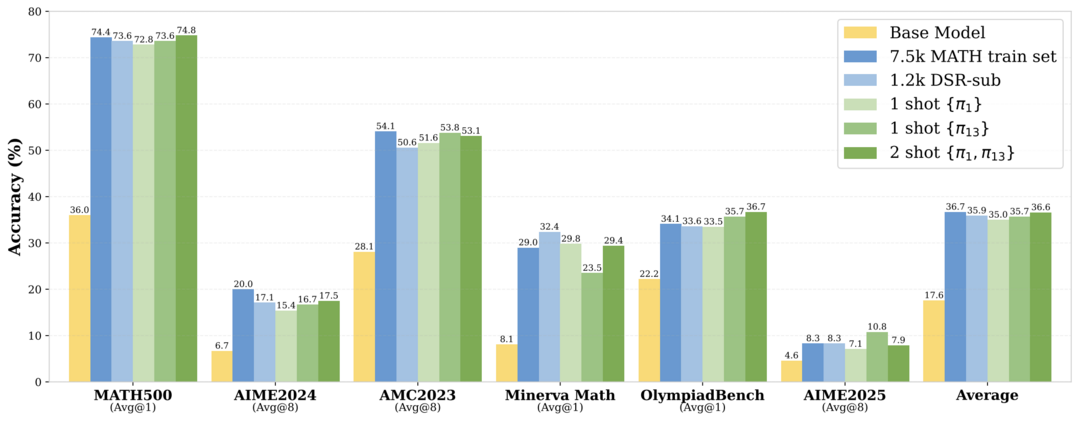
대규모 언어 모델(LLM)의 추론 능력을 강화하기 위해, 단 하나의 훈련 예제만 사용하는 강화학습(1-shot RLVR)이 매우 효과적임을 보였다. 이 방식은 특정 수학 문제 해결 예제 하나만으로 모델의 MATH500 벤치마크 성능을 36%에서 73.6%로 대폭 향상시켜, 수천 개 예제를 사용한 결과와 맞먹는 수준을 달성했으며, 훈련 시 탐색을 장려하는 것(엔트로피 손실 추가)이 중요함을 확인했다.
Skywork R1V2: Multimodal Hybrid Reinforcement Learning for Reasoning
https://arxiv.org/abs/2504.16656
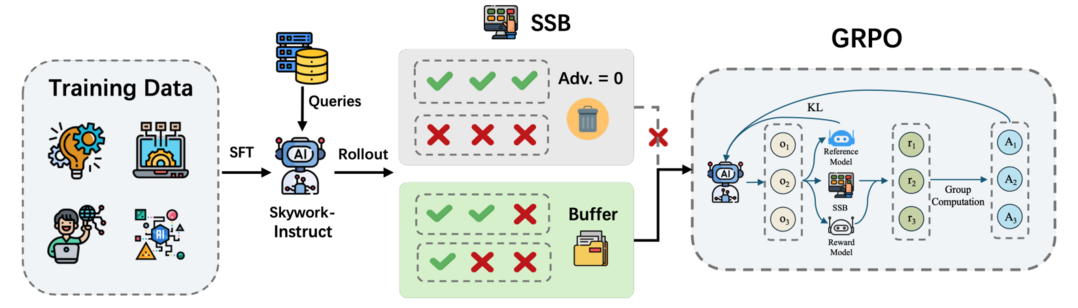
멀티모달 추론 모델 Skywork R1V2는 추론 능력과 일반화 사이의 어려운 균형을 맞추기 위해 보상 모델 유도와 규칙 기반 전략을 결합한 하이브리드 강화학습 패러다임을 도입했다. 또한, 훈련 효율성을 높이는 선택적 샘플 버퍼(SSB) 메커니즘을 적용하고 과도한 강화 신호로 인한 시각적 환각 현상을 제어하며, 여러 주요 추론 벤치마크(OlympiadBench, AIME2024 등)에서 최고 수준의 성능을 달성했다.
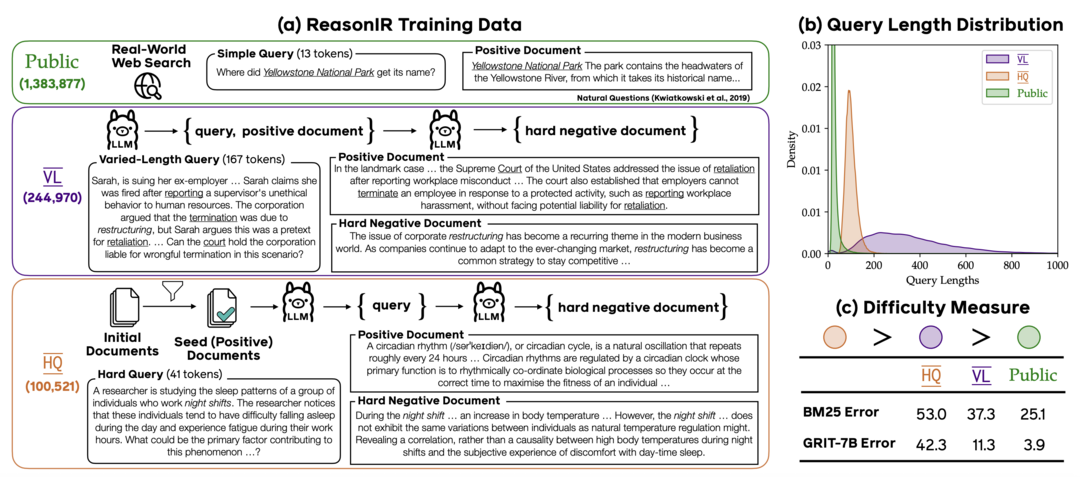
ReasonIR: Training Retrievers for Reasoning Tasks
https://arxiv.org/abs/2504.20595
기존 정보 검색기들이 사실적 질의에 치중되어 복잡한 추론에 약한 한계를 넘어, 추론 과제를 위해 특별히 훈련된 검색기 ReasonIR-8B를 개발했다. 이를 위해 어려운 질문과 혼동하기 쉬운 그럴듯한 오답(hard negative)을 포함한 합성 데이터 생성 기법을 개발하여 훈련했다. 그 결과, 추론 중심 벤치마크(BRIGHT)에서 최고 성능을 달성했고, RAG 시스템에 적용 시 주요 추론 과제(MMLU, GPQA 등) 성능을 크게 개선했다.
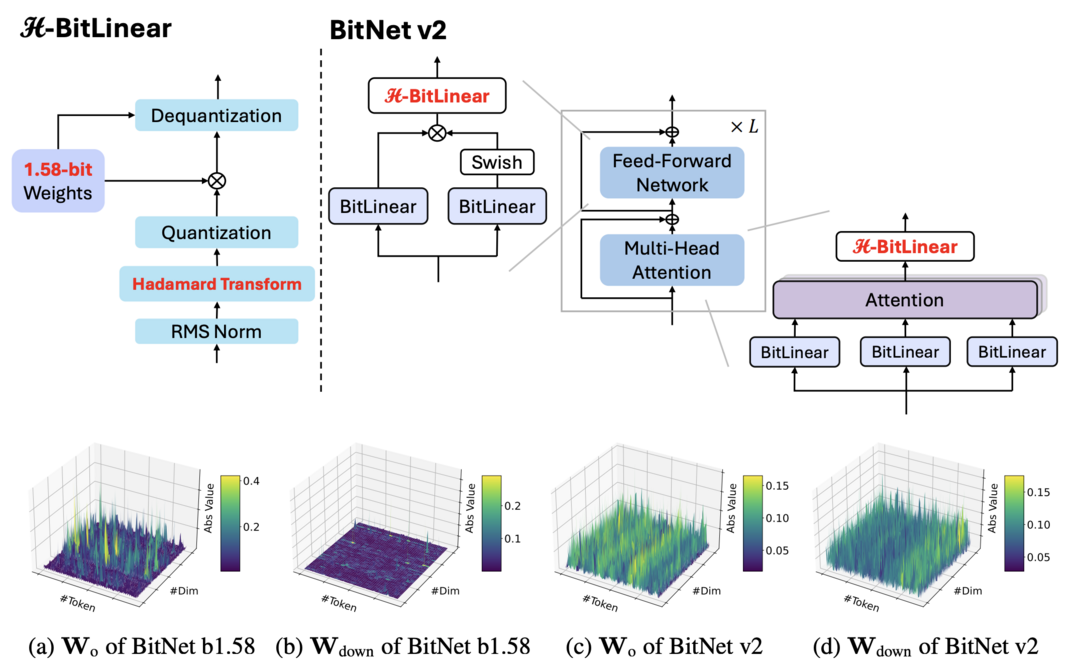
BitNet v2: Native 4-bit Activations with Hadamard Transformation for 1-bit LLMs
https://arxiv.org/abs/2504.18415
1비트 LLM의 효율적인 배포를 방해하는 활성화 값의 이상치(outlier) 문제를 해결하기 위해 BitNet v2 프레임워크를 제안했다. 핵심인 H-BitLinear 모듈은 활성화 양자화 직전에 온라인 아다마르 변환을 적용하여 분포를 부드럽게 만든다. 이를 통해 1비트 LLM에서 성능 저하를 최소화하면서 네이티브 4비트 활성화 양자화를 가능하게 하여 메모리 사용량 및 계산 효율성을 크게 향상시켰다.
2. 멀티모달 인식 및 생성 분야
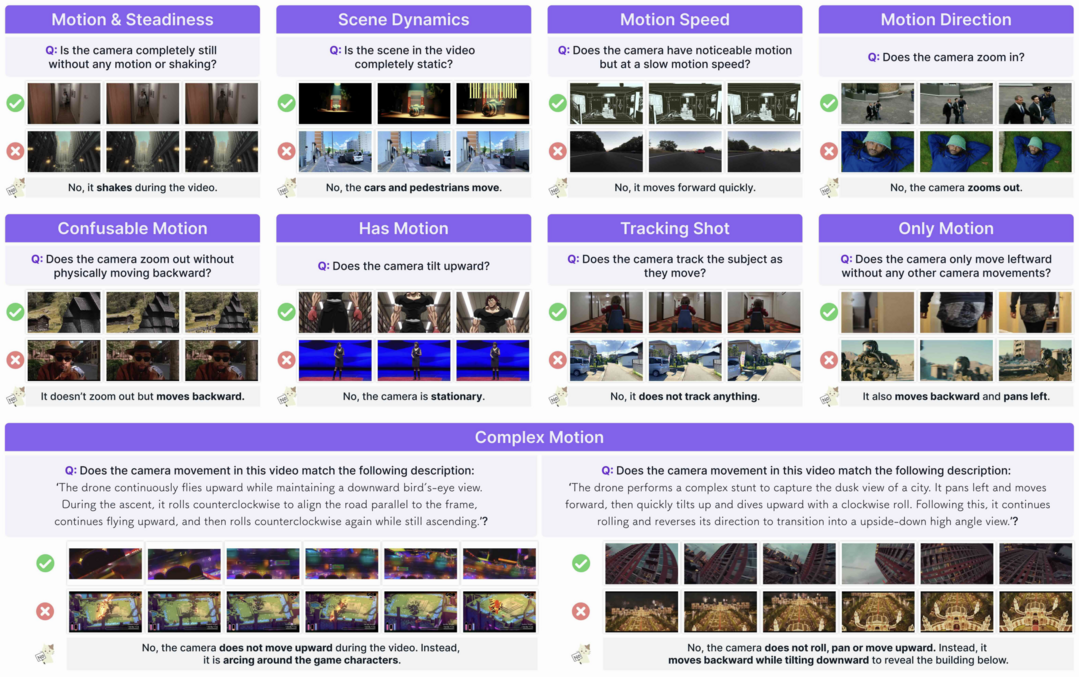
Towards Understanding Camera Motions in Any Video
https://arxiv.org/abs/2504.15376
비디오 속 카메라 움직임 이해를 목표로, 약 3,000개의 비디오로 구성된 대규모 데이터셋/벤치마크 CameraBench와 전문가 기반 움직임 분류 체계를 구축했다. 기존 구조-움직임 복원(SfM) 모델은 의미론적 움직임(예: 따라가기)에, 비디오-언어 모델(VLM)은 정밀한 기하학적 궤적 추정에 약점을 보였으며, 이를 개선하기 위해 두 장점을 결합한 VLM을 미세 조정하여 더 포괄적인 분석을 가능하게 했다.
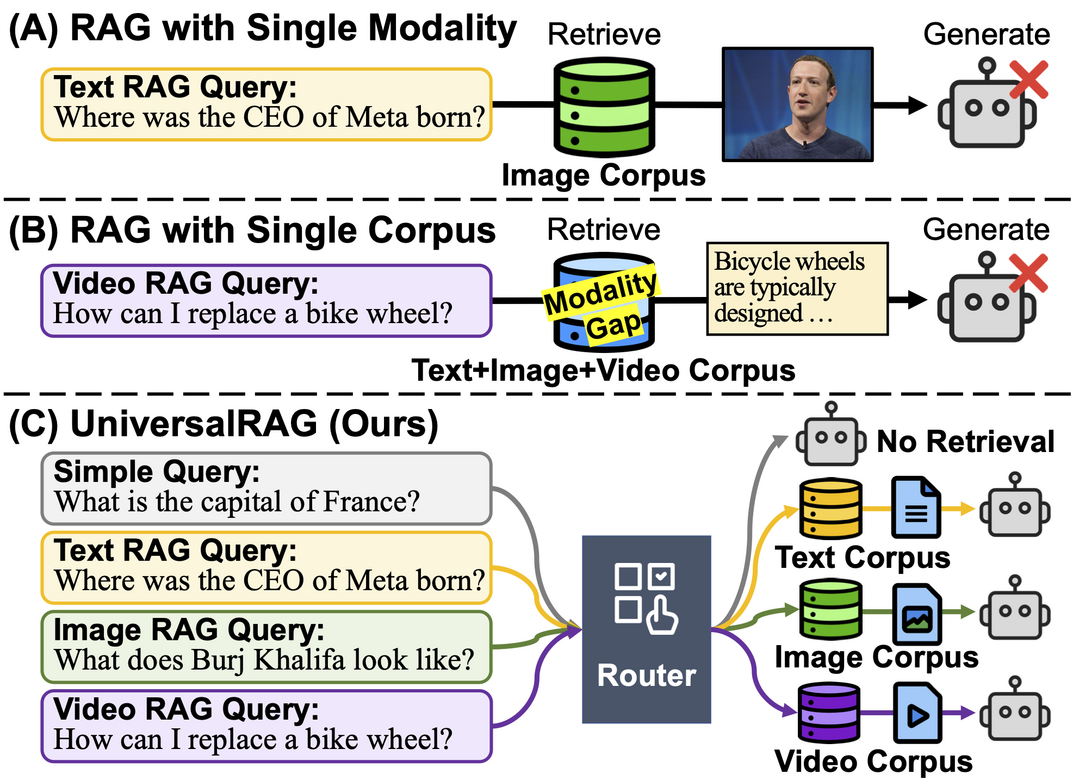
UniversalRAG: Retrieval-Augmented Generation over Multiple Corpora with Diverse Modalities and Granularities
https://arxiv.org/abs/2504.20734
기존 검색 증강 생성(RAG)이 주로 텍스트에 국한된 한계를 넘어, UniversalRAG는 텍스트, 이미지, 비디오 등 다양한 형태(modality)와 세분성(granularity)의 여러 데이터 소스를 동시에 활용하는 프레임워크다. 핵심인 형태 인식 라우팅 메커니즘을 통해 질의의 내용에 가장 적합한 형태의 데이터 소스를 동적으로 식별하고 그 안에서 검색함으로써, 보다 정확하고 관련성 높은 정보를 생성하도록 개선했다.
TesserAct: Learning 4D Embodied World Models
https://arxiv.org/abs/2504.20995
로봇과 같은 체화된 에이전트가 주변 환경과 상호작용하는 방식을 이해하기 위해, TesserAct는 3D 공간의 시간적 변화까지 예측하는 4D(3D+시간) 체화된 세계 모델 학습법을 제시했다. RGB 비디오에 깊이(D)와 법선(N) 정보를 추가하여 학습함으로써, 객체의 상세한 형태와 동적인 변화를 함께 모델링하고 이를 바탕으로 더 효과적인 에이전트 행동 정책(policy) 학습을 가능하게 했다.

In-Context Edit: Enabling Instructional Image Editing with In-Context Generation in Large Scale Diffusion Transformer
https://arxiv.org/abs/2504.20690
지시 기반 이미지 편집에서 정밀도와 효율성의 균형을 맞추고자 In-Context Edit 프레임워크를 개발했다. 대규모 디퓨전 트랜스포머(DiT)의 강력한 문맥 이해 능력을 활용하여, 별도의 큰 파인튜닝 없이 인-컨텍스트 프롬프팅만으로 제로샷(zero-shot) 편집을 수행한다. 또한 LoRA-MoE 하이브리드 튜닝으로 극소량의 파라미터만 효율적으로 학습시켜, 매우 적은 자원으로도 최첨단 수준의 편집 품질을 달성했다.

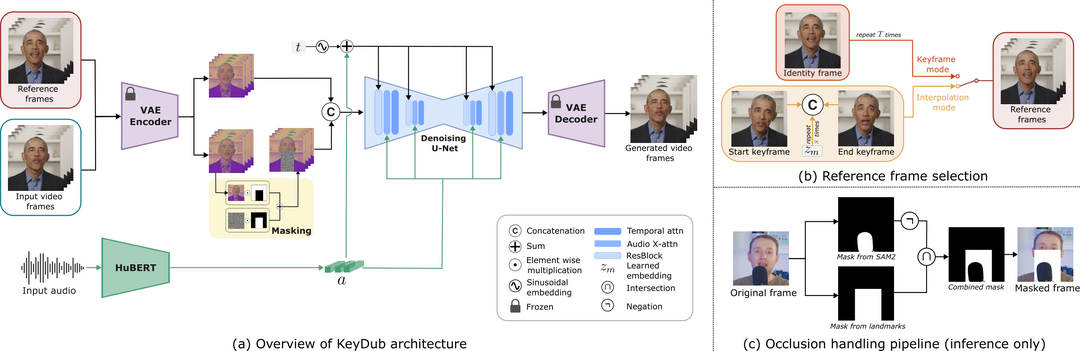
KeySync: A Robust Approach for Leakage-free Lip Synchronization in High Resolution
https://arxiv.org/abs/2505.00497
비디오 립싱크 시 원본 영상의 표정이 부자연스럽게 남는 표정 누수(leakage) 문제와 입 주변이 가려지는 얼굴 가림(occlusion) 문제를 해결하기 위해 KeySync 프레임워크를 제안했다. 이 2단계 시스템은 시간적 일관성을 유지하면서, 특수하게 설계된 마스킹 전략을 적용하여 원치 않는 표정 정보나 가려진 부분을 효과적으로 처리함으로써, 더욱 자연스럽고 정확한 고해상도 립싱크 결과를 생성한다.
Spatial Speech Translation: Translating Across Space With Binaural Hearables
https://arxiv.org/abs/2504.18715
여러 사람이 동시에 다른 언어로 말하는 복잡한 환경에서, 히어러블 기기가 이를 실시간 번역하여 들려주되, 각 화자의 원래 위치(공간감)와 고유한 목소리 특성까지 보존하는 공간 음성 번역 개념과 시스템을 개발했다. 음원 분리, 화자 위치 파악, 실시간 번역, 바이노럴 렌더링 기술을 통합하여, 주변 소음이나 다른 화자의 간섭 속에서도 각 화자의 번역된 목소리가 해당 방향에서 들리도록 구현했다.

3. AI 평가, 신뢰성 및 특화 응용 분야
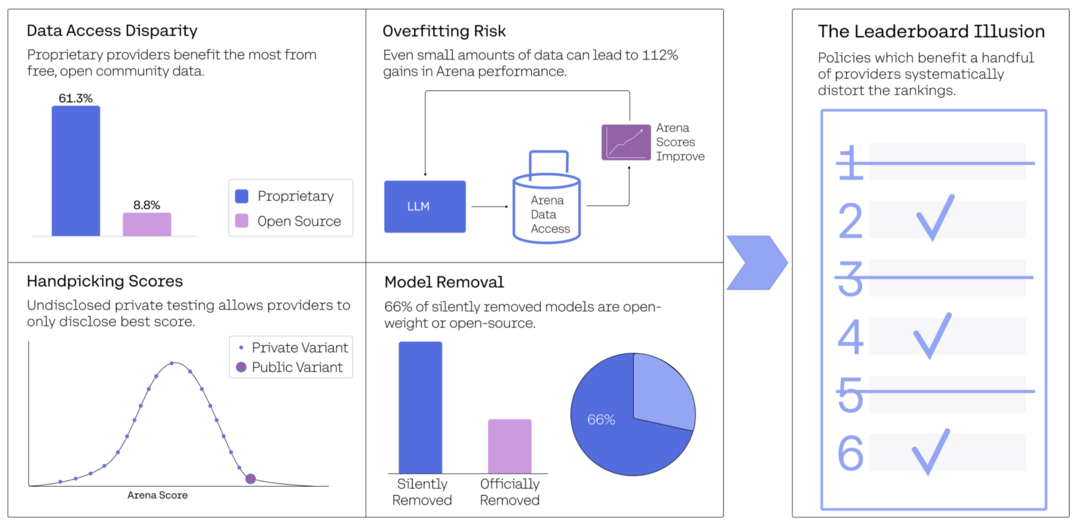
The Leaderboard Illusion
https://arxiv.org/abs/2504.20879
AI 모델 순위 리더보드인 Chatbot Arena가 공정성 문제를 겪고 있음을 지적했다. 일부 기업이 비공개 사전 테스트, 유리한 점수만 선택적 공개, 특정 기업 모델에 대한 더 많은 데이터(배틀 기회) 접근 등 체계적 편향의 혜택을 누리고 있으며, 이로 인해 순위가 왜곡되고 모델들이 실제 성능 향상보다 Arena 자체에 과적합되는 리더보드 착시 현상이 발생한다고 밝혔다.
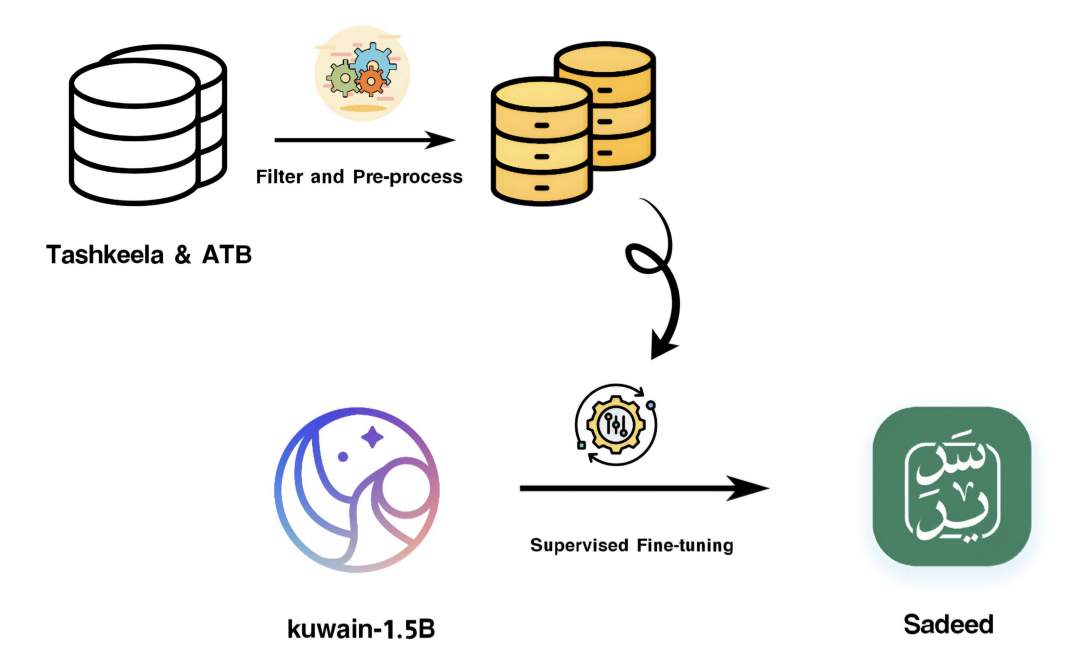
Sadeed: Advancing Arabic Diacritization Through Small Language Model
https://arxiv.org/abs/2504.21635
아랍어 발음 부호 표기(diacritization)의 어려움을 해결하기 위해, 다양한 아랍어 코퍼스로 사전 훈련된 소형 언어 모델을 기반으로 고품질 데이터에 미세 조정한 Sadeed 모델을 개발했다. 이 모델은 제한된 컴퓨팅 자원으로도 독점 대형 모델과 경쟁력 있는 성능을 달성했다. 더불어, 기존 평가 방식의 한계를 개선하기 위해 다양한 텍스트 유형과 난이도를 포괄하는 새 벤치마크 SadeedDiac-25도 함께 소개하여 공정한 비교를 가능하게 했다.
[METAX = 김한얼 기자]
[저작권자ⓒ META-X. 무단전재-재배포 금지]