수학 추론, GUI 그라운딩, 동적 세계 생성 등 특정 영역에서 인간 수준의 지능을 구현
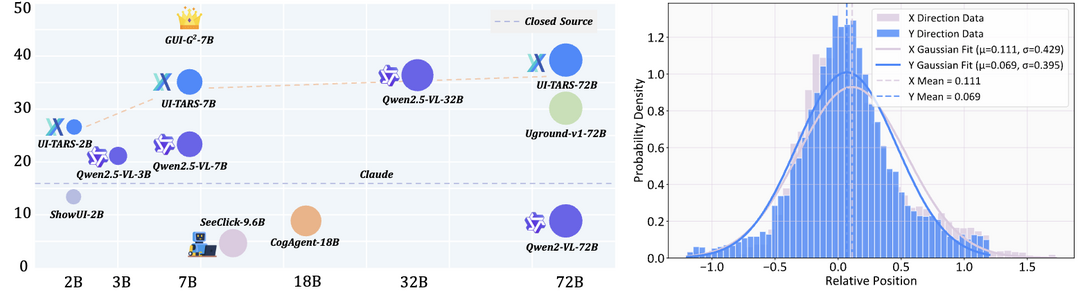
GUI-G^2: Gaussian Reward Modeling for GUI Grounding
https://arxiv.org/abs/2507.15846
GUI 그라운딩을 위한 가우시안 보상 모델링은 자연어 명령을 인터페이스의 정확한 위치로 매핑하는 기술에 혁신적인 접근법을 제시한다. 기존의 이진 보상(맞춤/놓침) 방식이 제공하는 희소한 신호의 한계를 극복하기 위해, GUI 요소를 2D 평면에서 연속적인 가우시안 분포로 모델링하는 방식을 도입했다. 가우시안 포인트 보상과 커버리지 보상, 그리고 요소 크기에 따라 조정되는 적응형 분산 메커니즘을 통해 보다 풍부한 그래디언트 신호를 생성하며, 이를 통해 ScreenSpot 벤치마크에서 최대 24.7%의 성능 향상을 달성했다.
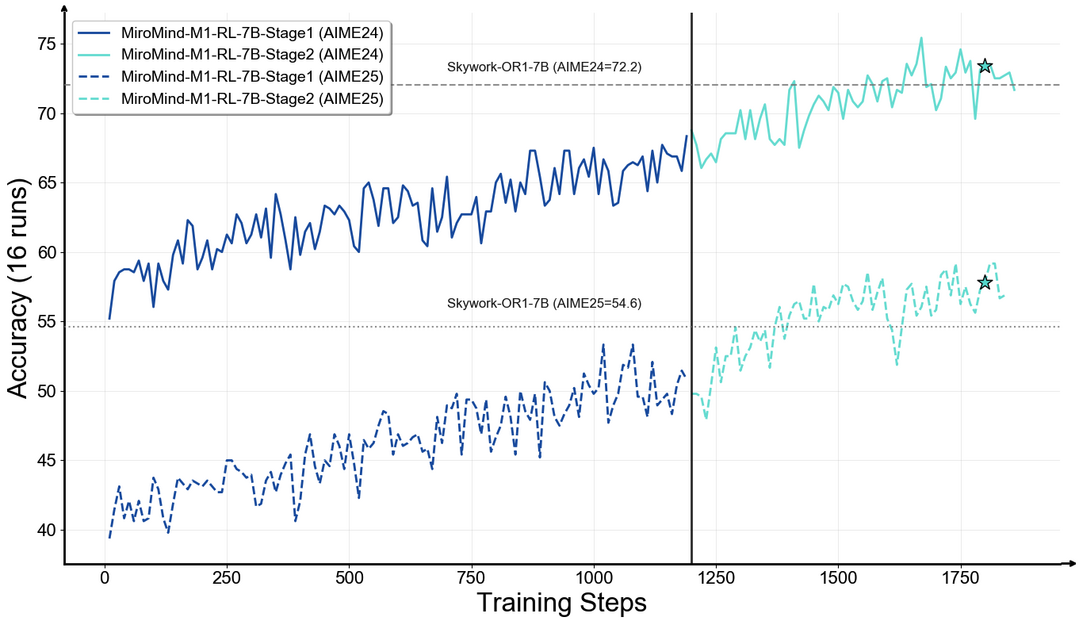
MiroMind-M1: An Open-Source Advancement in Mathematical Reasoning via Context-Aware Multi-Stage Policy Optimization
https://arxiv.org/abs/2507.14683
MiroMind-M1은 수학적 추론에 특화된 완전 오픈소스 추론 언어 모델로, 기존 오픈소스 모델들이 데이터셋이나 훈련 구성을 공개하지 않아 발생하는 재현성 부족 문제를 해결한다. Qwen-2.5를 기반으로 구축된 이 모델은 71.9만 개의 검증된 CoT 궤적을 가진 수학 문제로 지도 미세조정을 진행한 후, 6.2만 개의 검증 가능한 문제로 검증 가능한 보상을 통한 강화학습을 적용했다. 문맥 인식 다단계 정책 최적화 기술을 도입하여 AIME24, AIME25, MATH 벤치마크에서 최고 또는 경쟁력 있는 성능을 달성했으며, 모델(7B, 32B), 데이터셋, 훈련 및 평가 구성 전체를 공개하여 연구 커뮤니티의 발전에 기여한다.
Beyond Context Limits: Subconscious Threads for Long-Horizon Reasoning
https://arxiv.org/abs/2507.16784
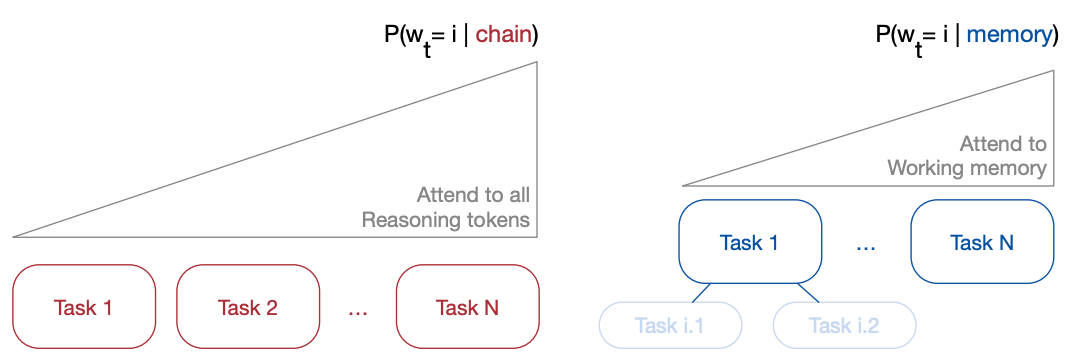
Thread Inference Model(TIM)과 TIMRUN은 LLM의 문맥 한계가 추론 정확도와 효율성을 제한하는 문제를 해결하기 위한 혁신적인 접근법이다. 자연어를 선형 시퀀스가 아닌 작업, 생각, 재귀적 하위 작업, 결론으로 구성된 추론 트리로 모델링하며, 규칙 기반 하위 작업 가지치기 메커니즘을 통해 가장 관련성 높은 문맥 토큰만 유지한다. 이를 통해 사실상 무제한 작업 메모리를 제공하고, 단일 언어 모델 추론 내에서 다중 도구 호출을 지원하며, 출력 제한, 위치 임베딩 제약, GPU 메모리 병목 현상을 극복하여 GPU 메모리의 KV 캐시 90%를 조작하면서도 높은 추론 처리량을 유지한다.
The Invisible Leash: Why RLVR May Not Escape Its Origin
https://arxiv.org/abs/2507.14843
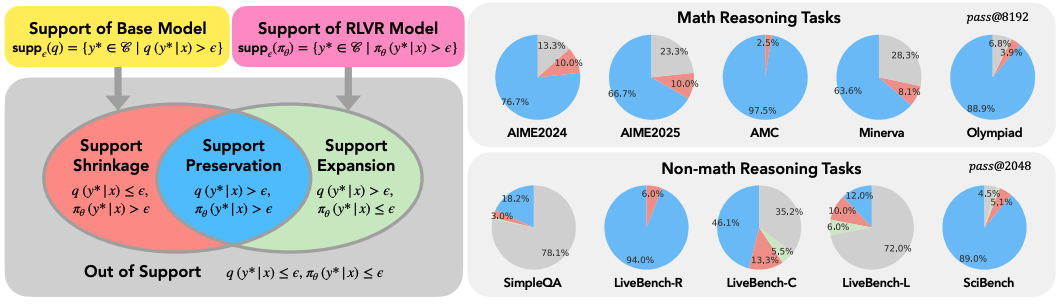
검증 가능한 보상을 통한 강화학습(RLVR)의 한계에 관한 연구는 RLVR이 모델의 추론 경계를 실제로 확장하는지에 대한 중요한 질문을 제기한다. 이론적 관점에서 RLVR은 기본 모델의 지원에 제한되어 초기 확률이 0인 솔루션을 샘플링할 수 없으며, 보수적인 재가중치 메커니즘으로 작동하여 완전히 새로운 솔루션 발견을 제한한다. 실험 결과, RLVR은 pass@1 성능은 일관되게 향상시키지만 경험적 지원 확장보다 축소가 더 크게 나타났으며, 토큰 수준 엔트로피는 증가할 수 있으나 답변 수준 엔트로피는 감소하는 엔트로피-보상 트레이드오프 현상이 관찰되었다.
The Devil behind the mask: An emergent safety vulnerability of Diffusion LLMs
https://arxiv.org/abs/2507.11097
DIJA는 확산 기반 LLM(dLLM)의 안전 취약점을 체계적으로 연구하고 공격하는 최초의 프레임워크이다. 병렬 디코딩과 양방향 모델링으로 빠른 추론을 제공하는 dLLM이 문맥 인식 마스크 입력 적대적 프롬프트에 취약하다는 점을 발견했으며, 이는 양방향 모델링이 유해 내용이라도 문맥상 일관된 출력을 생성하고 병렬 디코딩이 모델의 동적 필터링과 안전하지 않은 콘텐츠 거부 샘플링을 제한하기 때문이다. 유해 콘텐츠를 재작성하거나 숨길 필요 없이 Dream-Instruct에서 키워드 기반 ASR 100%를 달성하고, JailbreakBench에서 이전 최고 기준보다 78.5% 향상된 성능을 보여주었다.

Yume: An Interactive World Generation Model
https://arxiv.org/abs/2507.17744
Yume는 이미지, 텍스트 또는 비디오에서 상호작용 가능한 사실적이고 동적인 세계를 생성하는 혁신적인 모델이다. 입력 이미지에서 동적 세계를 생성하고 키보드 액션으로 탐색할 수 있는 기능을 제공하며, 카메라 모션 양자화, Masked Video Diffusion Transformer(MVDT)를 활용한 비디오 생성 아키텍처, Anti-Artifact Mechanism(AAM)과 Time Travel Sampling(TTS-SDE)을 포함한 고급 샘플러, 그리고 적대적 증류와 캐싱 메커니즘의 시너지 최적화를 통한 모델 가속 등 네 가지 주요 구성 요소로 이루어져 있다. 고품질 세계 탐색 데이터셋을 사용하여 훈련되었으며, 월별 업데이트를 통해 원래 목표를 달성할 예정이다.

Pixels, Patterns, but No Poetry: To See The World like Humans
https://arxiv.org/abs/2507.16863
Turing Eye Test(TET)는 다중 모달 대형 언어 모델(MLLM)이 인간처럼 세상을 인식할 수 있는지 평가하는 새로운 벤치마크이다. 인간이 직관적으로 처리하는 합성 이미지에 대한 MLLM 성능을 평가한 결과, 최첨단 MLLM도 인간에게는 쉬운 지각 작업에서 심각한 실패를 보였으며, 문맥 내 학습이나 언어 백본 훈련은 성능 향상에 실패했으나 비전 타워 미세 조정은 빠른 적응이 가능했다. 이를 통해 현재 MLLM과 인간 지각 사이에는 비전 타워 일반화의 간극이 존재함을 확인했으며, 향후 더 다양한 TET 작업과 시각적 일반화 향상 방법을 도입할 예정이다.

A Data-Centric Framework for Addressing Phonetic and Prosodic Challenges in Russian Speech Generative Models
https://arxiv.org/abs/2507.13563
Balalaika는 러시아어 음성 합성의 고유한 과제를 해결하기 위한 데이터 중심 프레임워크이다. 모음 축소, 자음 무성화, 가변 강세 패턴, 동형이의어 모호성, 부자연스러운 억양 등 러시아어 특유의 문제를 해결하기 위해 2,000시간 이상의 스튜디오 품질 러시아어 음성과 구두점 및 강세 표시를 포함한 포괄적인 텍스트 주석을 제공한다. 실험 결과, Balalaika로 훈련된 모델이 음성 합성 및 향상 작업에서 기존 데이터셋보다 우수한 성능을 달성했으며, 데이터셋 구축 파이프라인, 주석 방법론, 비교 평가 결과를 상세히 제시한다.

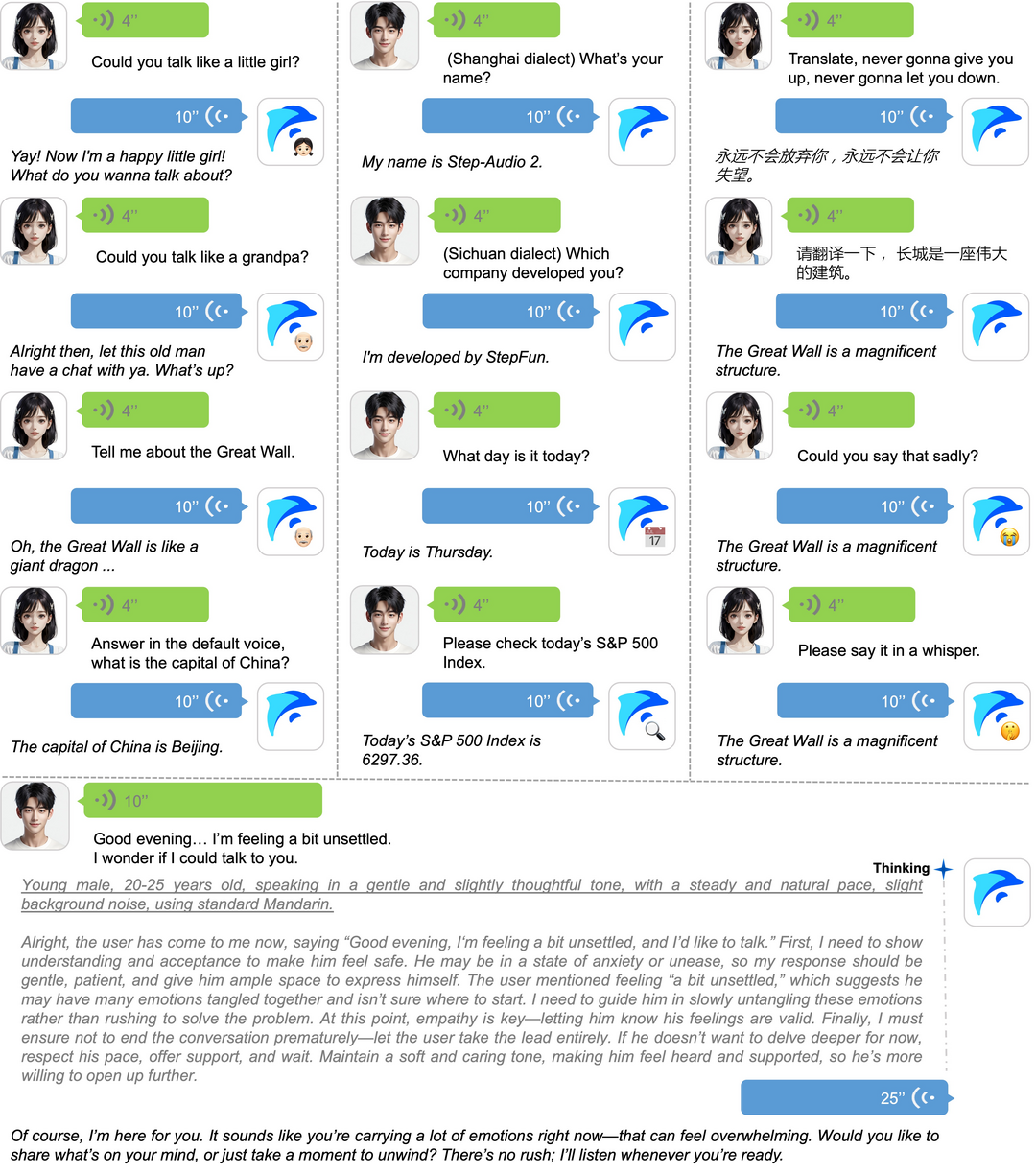
Step-Audio 2 Technical Report
https://arxiv.org/abs/2507.16632
Step-Audio 2는 산업 수준의 오디오 이해 및 음성 대화를 위한 엔드투엔드 다중 모달 대형 언어 모델이다. 잠재 오디오 인코더 통합과 추론 중심 강화학습을 통해 자동 음성 인식과 오디오 이해에서 뛰어난 성능을 달성했으며, 이산 오디오 토큰 생성을 언어 모델링에 통합하여 말하기 스타일, 감정 등 준언어적 정보에 효과적으로 반응한다. 검색 증강 생성(RAG)을 통합하고 웹 검색, 오디오 검색 등 외부 도구 호출 기능을 제공하며, 수백만 시간의 음성 및 오디오 데이터로 훈련되어 다양한 오디오 이해 및 대화 벤치마크에서 최고 수준의 성능을 달성했다.
[METAX = 김한얼 기자]
[저작권자ⓒ META-X. 무단전재-재배포 금지]