다국어·멀티모달 벤치마크 개발과 피드백 통합, 테스트 시간 계산 최적화로 AI 성능 향상 추구
TL;DR
1. MiniMax-M1
하이브리드 MoE 아키텍처와 라이트닝 어텐션을 결합한 100만 토큰 컨텍스트를 지원하는 세계 최초 오픈 웨이트 대규모 추론 모델이다.
2. MultiFinBen
금융 도메인에 특화된 최초의 다국어, 멀티모달 벤치마크로 LLM의 실제 금융 커뮤니케이션 능력을 평가한다.
3. Scientists' First Exam
과학적 인지 능력을 신호 인식, 속성 이해, 비교 추론 세 단계로 평가하는 과학 특화 MLLM 벤치마크이다.
4. DeepResearch Bench
웹 탐색, 정보 검색, 종합 능력을 평가하는 100개의 박사급 연구 과제로 구성된 심층 연구 에이전트 벤치마크이다.
5. Scaling Test-time Compute for LLM Agents
다양한 테스트 시간 확장 전략이 언어 에이전트의 성능을 향상시키며 특히 리스트 기반 검증 방식이 가장 효과적임을 입증한다.
6. Sekai
세계 100개 이상 국가의 5,000시간 이상 영상과 풍부한 주석을 포함한 세계 탐험용 고품질 1인칭 비디오 데이터셋이다.
7. CMI-Bench
다양한 음악 정보 검색 작업을 지시 따르기 형태로 재해석한 오디오-텍스트 LLM 평가용 포괄적 음악 벤치마크이다.
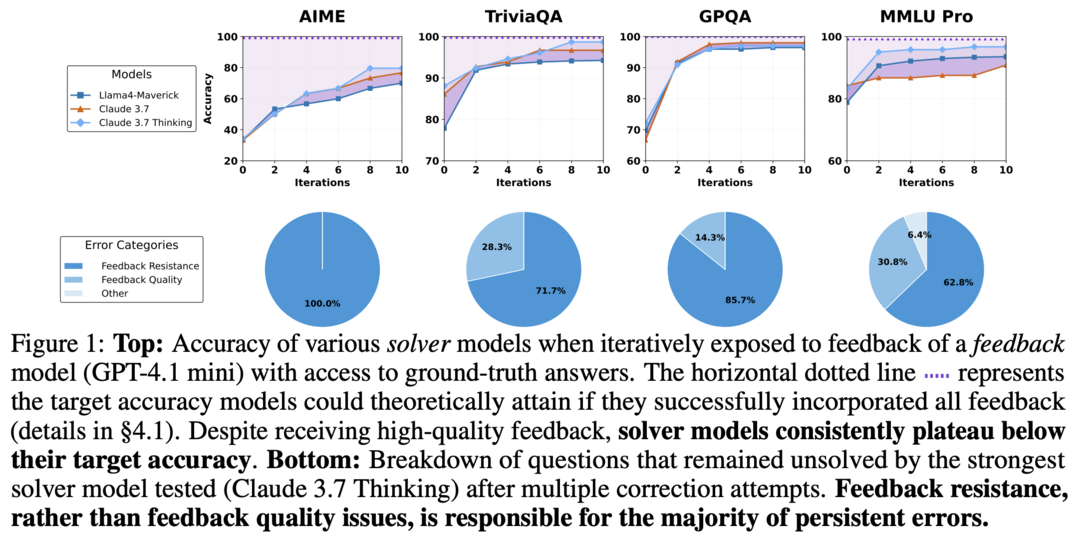
8. Feedback Friction
이상적인 조건에서도 LLM이 외부 피드백을 완전히 통합하는 데 저항하는 '피드백 마찰' 현상을 발견하고 분석한다.
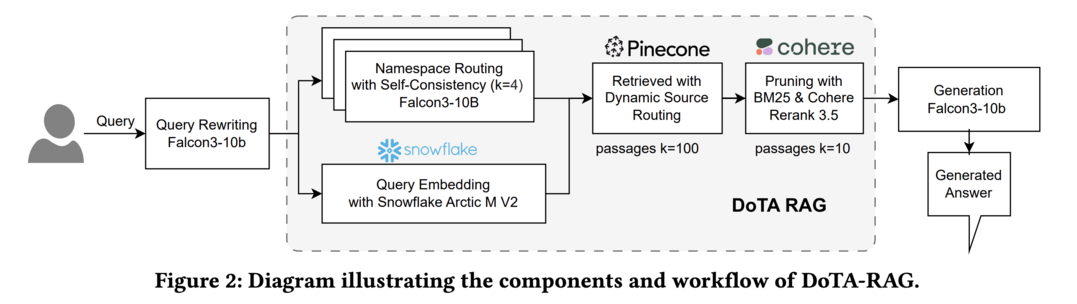
9. DoTA-RAG
쿼리 재작성, 동적 라우팅, 다단계 검색을 통해 대규모 웹 지식 인덱스에서 높은 정확도와 낮은 지연시간을 달성하는 RAG 시스템이다.
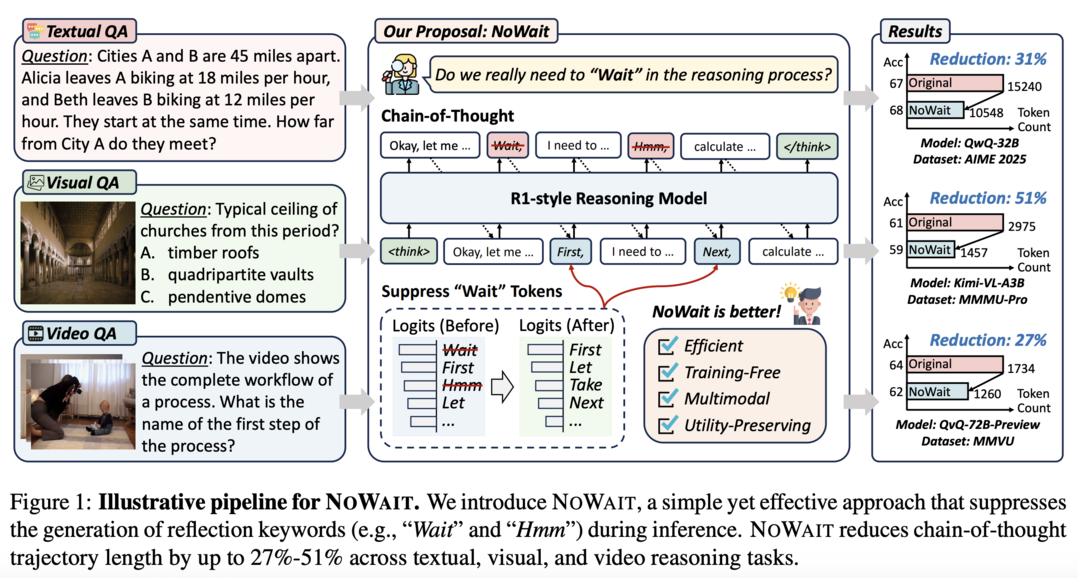
10. Wait, We Don't Need to "Wait"!
"Wait", "Hmm" 같은 사고 토큰을 제거함으로써 모델 유용성을 유지하면서 추론 길이를 최대 51%까지 줄이는 효율적 추론 방법이다.
MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
https://arxiv.org/abs/2506.13585
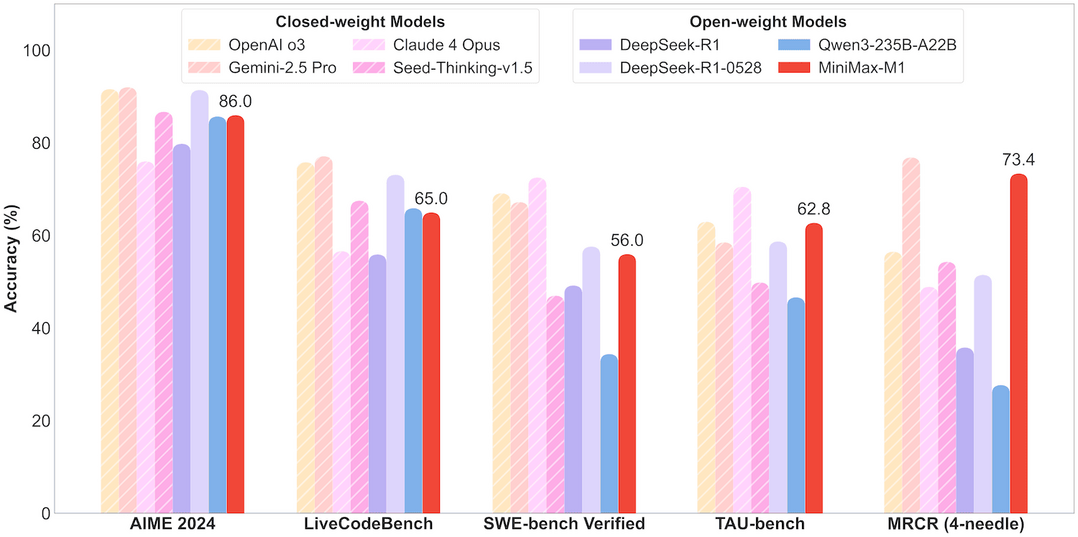
MiniMax-M1은 세계 최초의 오픈 웨이트 하이브리드 어텐션 추론 모델이다. 이 모델은 하이브리드 MoE(Mixture-of-Experts) 아키텍처와 라이트닝 어텐션 메커니즘을 결합하여 설계되었다. 총 456억 파라미터를 보유하고 있으며, 토큰당 45.9억 파라미터가 활성화된다. 특히 100만 토큰의 컨텍스트 길이를 지원하여 DeepSeek R1보다 8배 큰 컨텍스트를 처리할 수 있다. 연구팀은 새로운 RL 알고리즘인 CISPO를 제안하여 학습 효율성을 크게 향상시켰다. 이러한 기술적 혁신으로 인해 512대의 H800 GPU를 사용한 전체 RL 훈련이 단 3주 만에 완료되었으며, 비용은 $534,700에 불과했다. 연구팀은 40K와 80K 사고 예산을 가진 두 버전의 모델을 공개했으며, 이 모델들은 복잡한 소프트웨어 엔지니어링, 도구 활용, 긴 컨텍스트 작업에서 특히 강점을 보인다.
MultiFinBen: A Multilingual, Multimodal, and Difficulty-Aware Benchmark for Financial LLM Evaluation
https://arxiv.org/abs/2506.14028
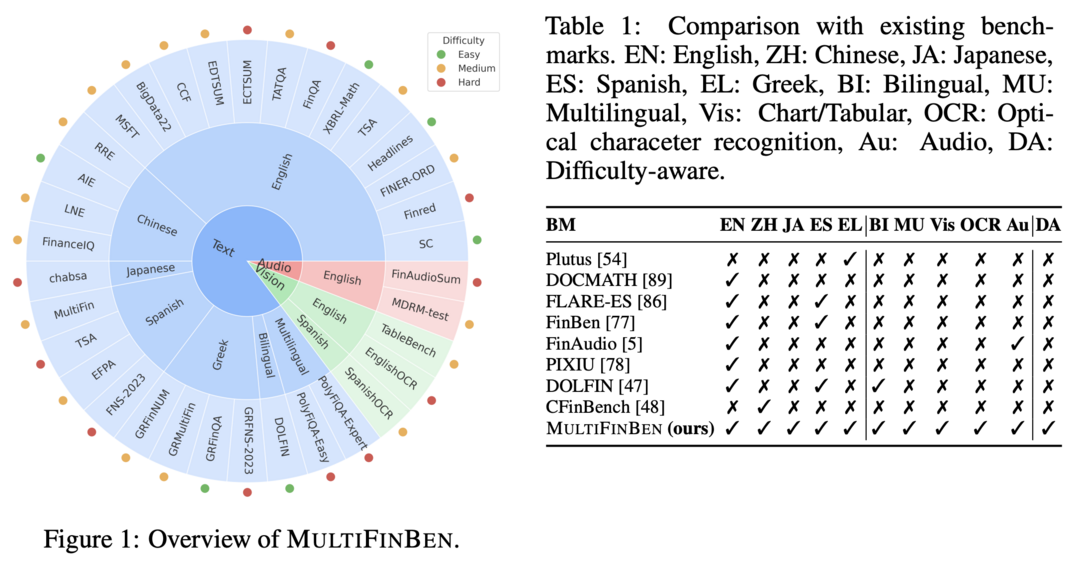
MultiFinBen은 글로벌 금융 도메인에 특화된 최초의 다국어, 멀티모달 벤치마크이다. 이 벤치마크는 텍스트, 비전, 오디오 등 다양한 모달리티와 다국어 환경에서 LLM의 성능을 평가한다. 연구팀은 PolyFiQA-Easy와 PolyFiQA-Expert라는 새로운 다국어 금융 벤치마크를 도입했으며, EnglishOCR과 SpanishOCR 같은 OCR 기반 금융 QA 작업도 포함시켰다. 또한 난이도 인식 선택 메커니즘을 제안하여 균형 잡힌 벤치마크를 구성했다. 22개의 최신 모델을 평가한 결과, 일반적인 멀티모달 및 다국어 능력이 뛰어난 강력한 모델들도 복잡한 다국어/멀티모달 금융 작업에서 상당한 어려움을 겪는 것으로 나타났다.
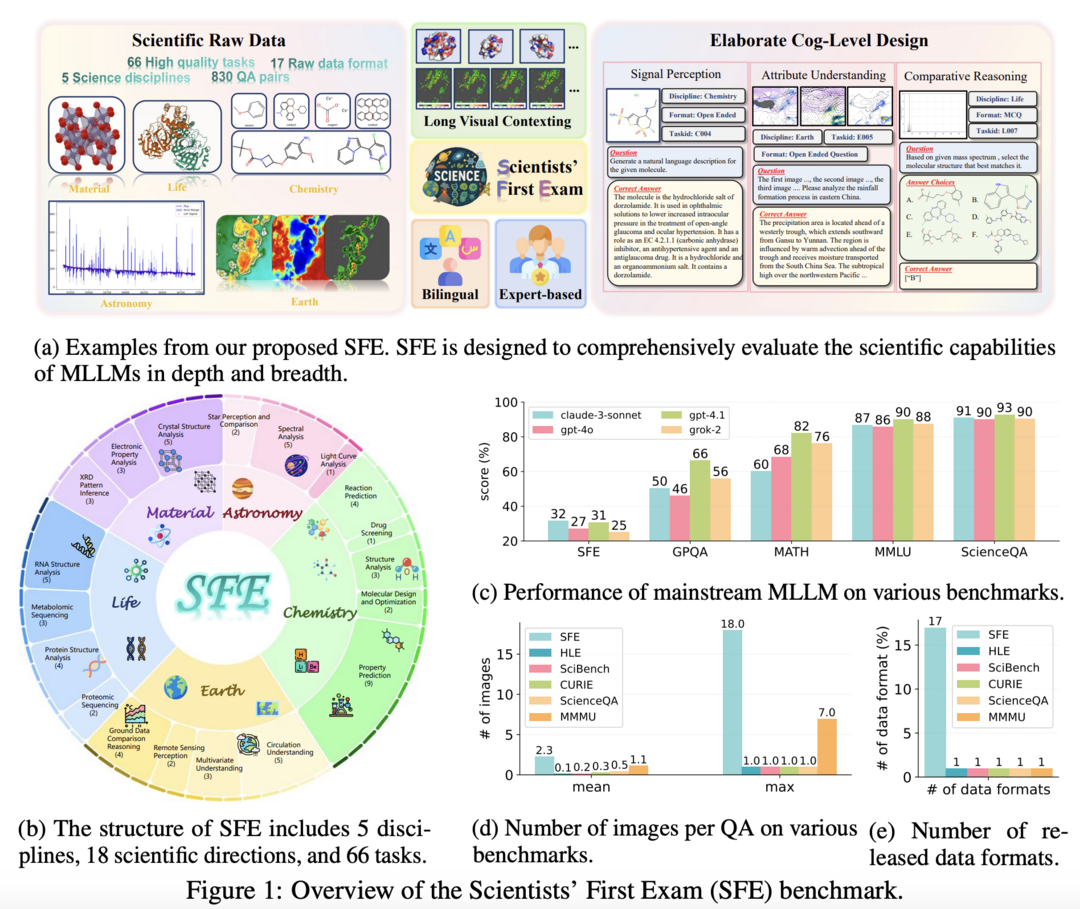
Scientists' First Exam: Probing Cognitive Abilities of MLLM via Perception, Understanding, and Reasoning
https://arxiv.org/abs/2506.10521
Scientists' First Exam(SFE)은 과학적 다중모달 추론 능력을 평가하기 위한 새로운 벤치마크이다. 이 벤치마크는 과학적 신호 인식, 과학적 속성 이해, 과학적 비교 추론이라는 3단계로 MLLM의 인지 능력을 평가한다. 5개 핵심 학문 분야에 걸쳐 66개 멀티모달 작업을 포함한 830개의 전문가 검증 VQA 쌍으로 구성되어 있다. 최신 모델인 GPT-o3와 InternVL-3를 평가한 결과, 각각 34.08%와 26.52%의 낮은 성능을 보였다. 이는 과학 분야에서 MLLM이 아직 상당한 발전 가능성을 가지고 있음을 시사한다.
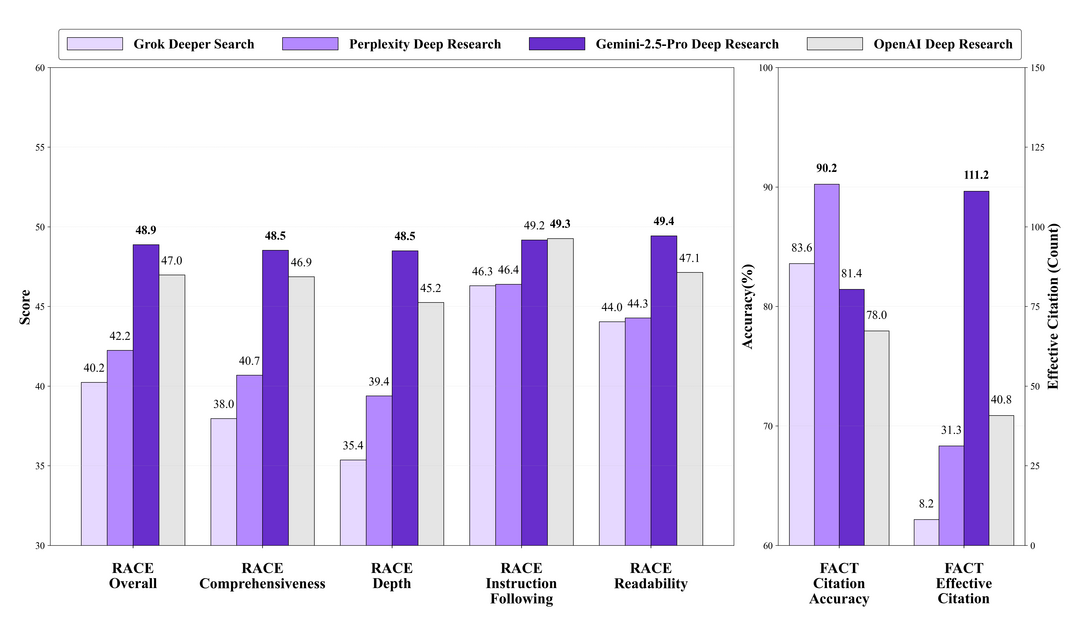
DeepResearch Bench: A Comprehensive Benchmark for Deep Research Agents
https://arxiv.org/abs/2506.11763
DeepResearch Bench는 LLM 기반 심층 연구 에이전트(DRA)를 평가하기 위한 포괄적인 벤치마크이다. 이 벤치마크는 22개 분야의 도메인 전문가가 설계한 100개의 박사급 연구 과제를 포함하고 있다. 연구팀은 인간 판단과 강한 일치도를 보이는 두 가지 평가 방법론을 제안했다. 첫 번째는 적응형 기준으로 연구 보고서 품질을 평가하는 참조 기반 방법이고, 두 번째는 인용 수와 인용 정확도를 평가하는 정보 검색 능력 평가 프레임워크이다. 이 벤치마크는 실용적인 LLM 기반 에이전트 개발을 가속화하기 위해 오픈소스로 공개되었다.
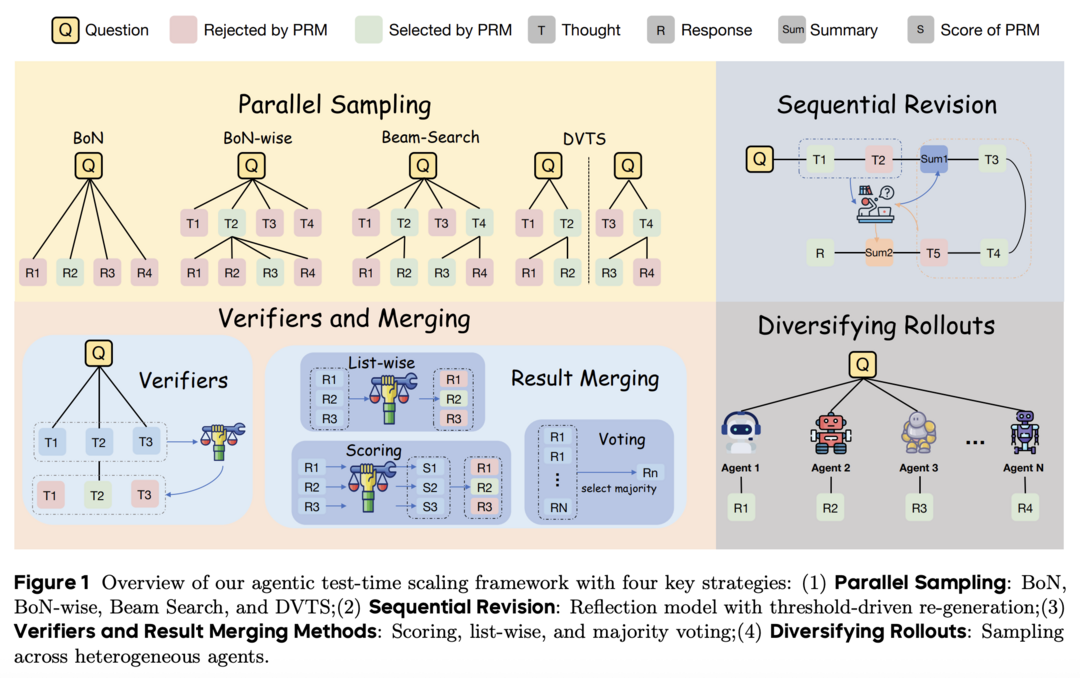
Scaling Test-time Compute for LLM Agents
https://arxiv.org/abs/2506.12928
이 연구는 언어 에이전트에 테스트 시간 확장 방법을 적용한 첫 체계적인 탐색이다. 연구팀은 병렬 샘플링 알고리즘, 순차적 수정 전략, 검증기 및 병합 방법, 다양한 롤아웃 전략 등 다양한 테스트 시간 확장 전략을 탐구했다. 연구 결과, 테스트 시간 계산 확장이 에이전트의 성능을 향상시킬 수 있음을 확인했다. 또한 언제 성찰할지 아는 것이 에이전트에게 중요하며, 리스트 기반 검증 및 결과 병합 방식이 가장 우수한 성능을 보였다. 다양한 롤아웃을 증가시키는 것도 에이전트의 작업 성능에 긍정적인 영향을 미쳤다.
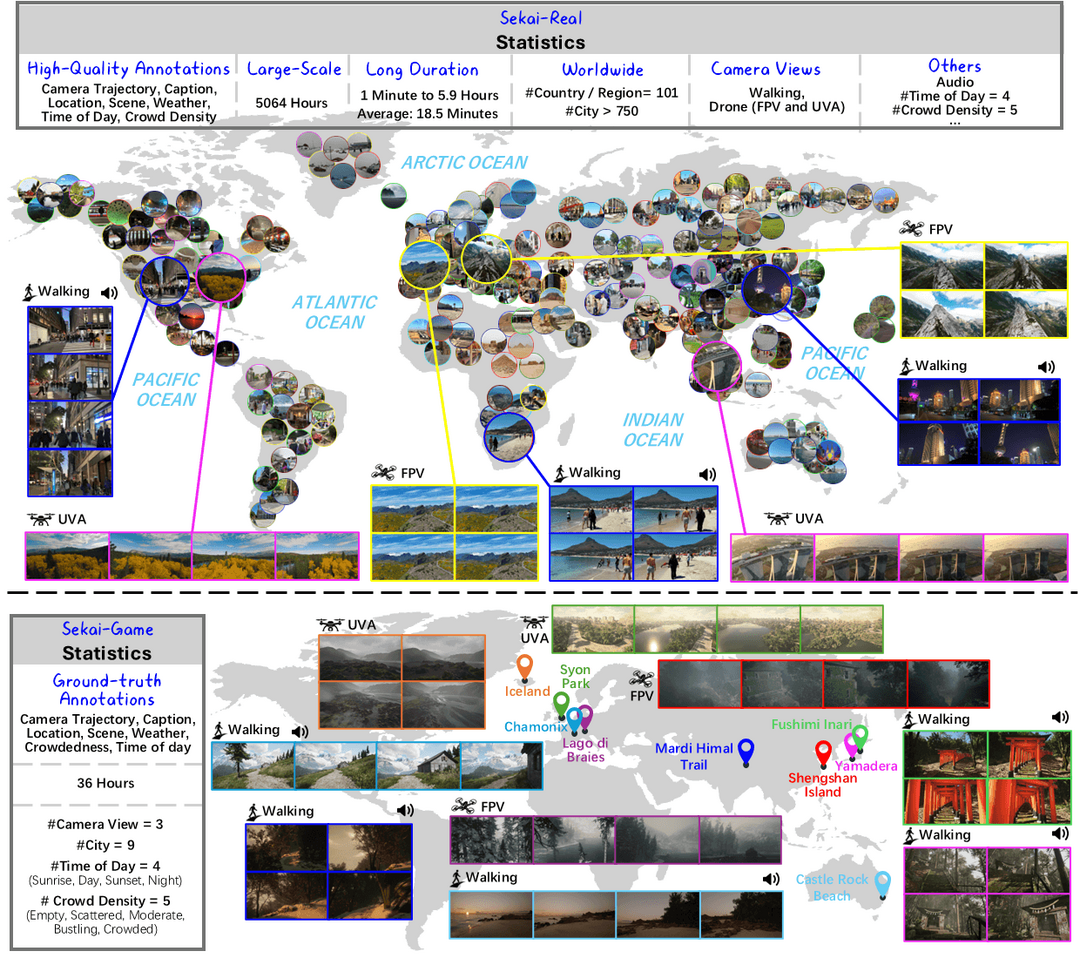
Sekai: A Video Dataset towards World Exploration
https://arxiv.org/abs/2506.15675
Sekai는 세계 탐험 훈련에 적합한 고품질 1인칭 시점의 전 세계 비디오 데이터셋이다. 이 데이터셋은 전 세계 100개 이상 국가 및 지역의 750개 도시에서 수집한 5,000시간 이상의 걷기/드론 영상을 포함하고 있다. 각 영상에는 위치, 장면, 날씨, 인구 밀도, 캡션, 카메라 궤적 등 풍부한 주석이 제공된다. 연구팀은 비디오 수집, 전처리, 주석 처리를 위한 효율적인 도구를 개발했으며, 이 데이터셋의 일부를 활용하여 YUME라는 인터랙티브 비디오 세계 탐험 모델을 훈련시켰다. Sekai는 비디오 생성 및 세계 탐험 분야의 발전에 크게 기여할 것으로 기대된다.
CMI-Bench: A Comprehensive Benchmark for Evaluating Music Instruction Following
https://arxiv.org/abs/2506.12285
CMI-Bench는 오디오-텍스트 LLM을 평가하기 위한 포괄적인 음악 지시 따르기 벤치마크이다. 이 벤치마크는 장르 분류, 감정 회귀, 악기 분류, 음높이 추정 등 다양한 음악 정보 검색(MIR) 작업을 포함하고 있다. 연구팀은 기존 최첨단 MIR 모델과 직접 비교할 수 있도록 표준화된 평가 지표를 채택했으며, 모든 오픈소스 오디오-텍스트 LLM을 지원하는 평가 도구를 제공했다. 실험 결과, LLM과 지도학습 모델 간에 상당한 성능 격차가 있으며, 모델들이 문화적, 시간적, 성별 편향을 보이는 것으로 나타났다. CMI-Bench는 음악 인식 LLM 발전을 위한 통합 기반을 확립했다.

Feedback Friction: LLMs Struggle to Fully Incorporate External Feedback
https://arxiv.org/abs/2506.11930
이 연구는 LLM이 외부 피드백을 효과적으로 통합하는 능력을 체계적으로 조사했다. 연구팀은 솔버 모델이 해결을 시도하고, 피드백 생성기가 타겟 피드백을 제공한 후, 솔버가 다시 시도하는 통제된 실험 환경을 설계했다. 수학 추론, 지식 추론, 과학 추론 등 다양한 작업에서 Claude 3.7 등 최신 언어 모델을 평가했다. 놀랍게도 이상적인 조건에서도 모델들이 피드백에 저항하는 "피드백 마찰" 현상이 발견되었다. 연구팀은 점진적 온도 증가, 이전 오답 명시적 거부 등의 개선 전략을 실험했지만 여전히 목표 성능에 도달하지 못했다. 또한 모델 과신뢰, 데이터 친숙도 등 피드백 마찰의 잠재적 원인을 탐색했으나 명확한 원인을 찾지 못했다.
DoTA-RAG: Dynamic of Thought Aggregation RAG
https://arxiv.org/abs/2506.12571
DoTA-RAG는 대규모 웹 지식 인덱스를 위한 최적화된 검색 증강 생성 시스템이다. 이 시스템은 쿼리 재작성, 전문화된 하위 인덱스로의 동적 라우팅, 다단계 검색 및 랭킹이라는 세 단계 파이프라인을 도입했다. 연구팀은 우수한 임베딩 모델을 평가하고 선택하여 FineWeb-10BT 코퍼스를 재임베딩했으며, WebOrganizer 주제와 형식에 걸친 500개 질문으로 다양한 Q&A 데이터셋을 생성했다. DoTA-RAG는 기준선(0.752) 대비 정답 정확도 점수를 1.478로 크게 개선하면서도 낮은 지연시간을 유지했으며, Live Challenge Day에서 0.929의 정확도 점수를 달성했다. 이 결과는 DoTA-RAG가 빠르고 신뢰할 수 있는 대규모 지식 소스 접근이 필요한 도메인에 실용적으로 배포될 수 있는 잠재력을 보여준다.
Wait, We Don't Need to "Wait"! Removing Thinking Tokens Improves Reasoning Efficiency
https://arxiv.org/abs/2506.08343
이 연구는 대규모 추론 모델의 과도한 사고 과정이 효율성을 저해하는 문제를 해결하기 위해 진행되었다. 연구팀은 "Wait", "Hmm" 같은 명시적 자기 성찰 토큰이 고급 추론에 필요한지 검토했다. 이를 바탕으로 NoWait이라는 접근법을 제안했는데, 이는 추론 중 이러한 토큰을 억제하여 명시적 자기 성찰을 비활성화하는 방법이다. 텍스트, 시각, 비디오 추론 작업의 10개 벤치마크에서 광범위한 실험을 수행한 결과, 5개 R1 스타일 모델 시리즈에서 사고 과정 길이를 27%-51%까지 줄이면서도 모델의 유용성을 유지할 수 있었다. NoWait은 멀티모달 추론을 위한 즉시 사용 가능한 효율적인 솔루션을 제공한다.
[METAX = 김한얼 기자]
[저작권자ⓒ META-X. 무단전재-재배포 금지]