암기를 넘어, 현실과 상호작용하는 신뢰성 높은 지능의 새로운 지평
TL;DR
1. Test-Time Scaling with Reflective Generative Model
정책 모델과 보상 모델을 하나로 통합하여 추론 효율을 높이고, 테스트 시점에 계산량을 조절해 성능을 유연하게 바꾸는 생성형 모델 MetaStone-S1을 제안한다.
2. A Survey of Context Engineering for Large Language Models
LLM의 성능을 높이기 위한 '컨텍스트 엔지니어링' 분야를 체계적으로 정리하고, 모델이 복잡한 문맥을 이해하는 능력에 비해 생성하는 능력이 부족하다는 핵심 연구 과제를 제시한다.
3. Reasoning or Memorization? Unreliable Results of Reinforcement Learning Due to Data Contamination
데이터 오염이 없는 자체 제작 벤치마크를 통해 LLM의 강화학습 성능 향상이 진정한 추론 능력의 발전이 아닌 데이터 암기 때문일 수 있음을 밝히고, 신뢰성 있는 평가를 촉구한다.
4. Open Vision Reasoner: Transferring Linguistic Cognitive Behavior for Visual Reasoning
언어적 미세조정과 멀티모달 강화학습을 결합한 2단계 훈련법으로 언어 모델의 추론 능력을 시각 영역으로 성공적으로 전이시킨 Open-Vision-Reasoner 모델을 개발했다.
5. NeuralOS: Towards Simulating Operating Systems via Neural Generative Models
사용자의 입력에 반응하여 운영체제의 그래픽 인터페이스(GUI) 화면을 실시간으로 생성하는 신경망 시뮬레이터 NeuralOS를 제안한다.
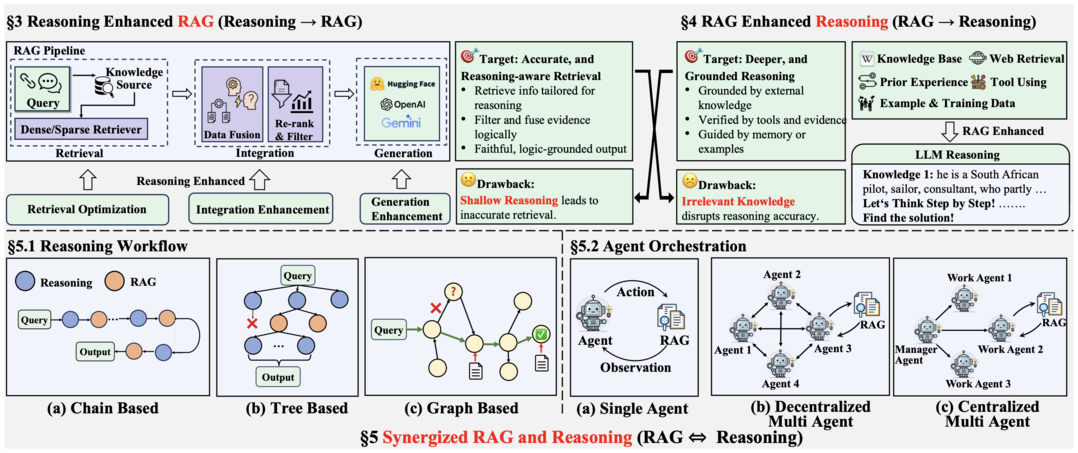
6. Towards Agentic RAG with Deep Reasoning: A Survey of RAG-Reasoning Systems in LLMs
사실적이지만 추론이 약한 RAG와 추론은 잘하지만 환각이 있는 순수 추론을 통합하는 관점을 제시하고, 에이전트가 검색과 추론을 반복하는 융합형 프레임워크를 핵심 발전 방향으로 제시한다.
7. Vision Foundation Models as Effective Visual Tokenizers for Autoregressive Image Generation
이미지 이해에 쓰이던 비전 파운데이션 모델을 이미지 생성용 토크나이저로 활용하여, 생성 품질과 학습 효율을 동시에 크게 향상시킨 VFMTok을 제안한다.
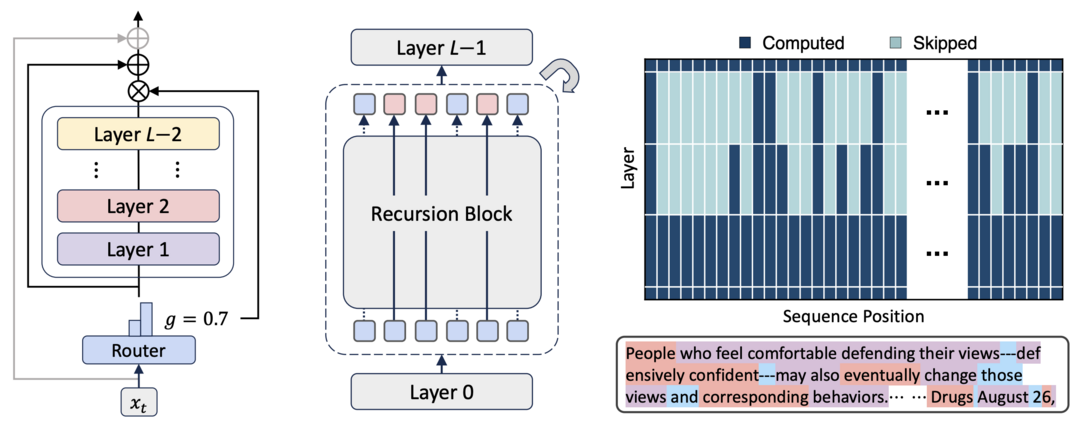
8. Mixture-of-Recursions: Learning Dynamic Recursive Depths for Adaptive Token-Level Computation
모델의 일부를 재사용하면서도 토큰별로 계산량을 동적으로 할당하는 재귀 혼합(MoR) 프레임워크를 통해 적은 비용으로 큰 모델의 성능을 달성한다.
9. CLiFT: Compressive Light-Field Tokens for Compute-Efficient and Adaptive Neural Rendering
3D 장면을 압축된 토큰(CLiFT)으로 표현하고 렌더링 시 토큰 수를 조절하여, 데이터 크기, 품질, 속도 간의 균형을 유연하게 선택할 수 있는 신경 렌더링 기술을 제안한다.
Test-Time Scaling with Reflective Generative Model
https://arxiv.org/abs/2507.01951
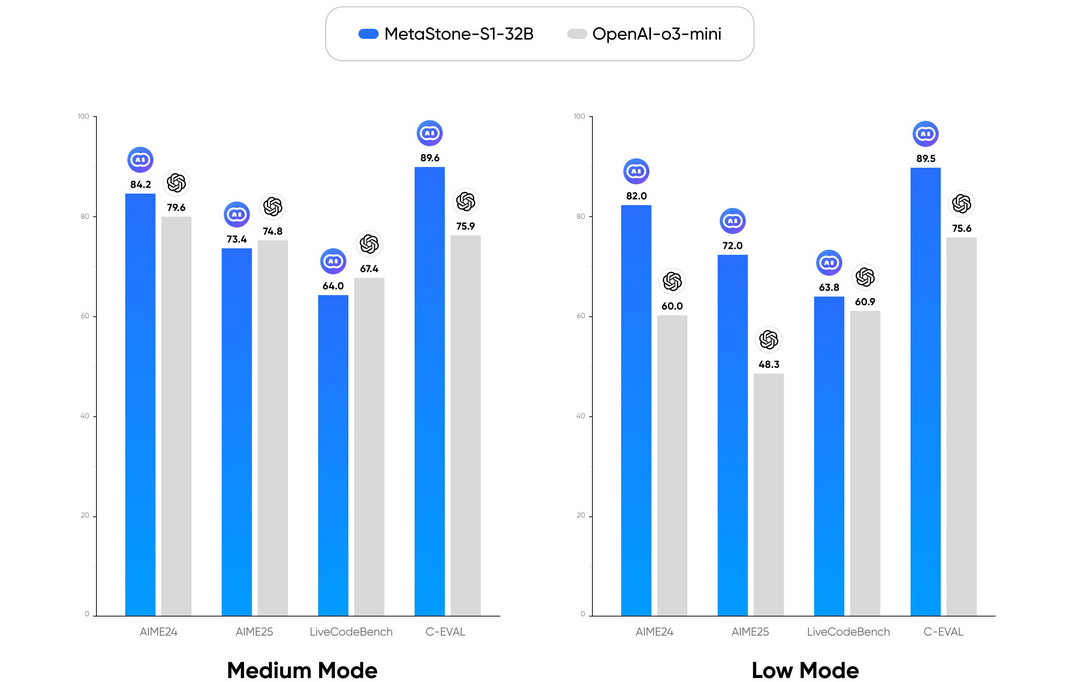
'반성적 생성 모델을 통한 테스트 시간 스케일링' 논문은 MetaStone-S1이라는 새로운 생성형 모델을 제안한다. 이 모델은 정책 모델과 보상 모델을 '자기 지도 방식 프로세스 보상 모델(SPRM)'이라는 단일 네트워크로 통합하여, 보상 모델의 파라미터를 99% 이상 절감하며 추론 효율성을 크게 높였다. 이러한 통합 구조를 통해 모델이 추론 시 생각의 길이를 조절하여 성능과 계산량의 균형을 맞추는 '테스트 시간 스케일링(TTS)'을 실현했으며, 실험을 통해 320억 개라는 상대적으로 적은 파라미터로 OpenAI의 o3-mini와 필적하는 성능을 달성할 수 있음을 입증했다.
A Survey of Context Engineering for Large Language Models
https://arxiv.org/abs/2507.13334
'LLM을 위한 컨텍스트 엔지니어링 개요'는 LLM의 성능을 극대화하기 위해 입력 정보를 체계적으로 최적화하는 '컨텍스트 엔지니어링'이라는 분야를 정립한 연구다. 1,300편이 넘는 논문을 종합 분석하여, 컨텍스트의 검색·생성·처리·관리와 같은 기본 요소부터 RAG, 멀티 에이전트 같은 복합 시스템까지의 기술적 로드맵을 제시했다. 이 연구는 현재 LLM이 복잡한 문맥을 이해하는 데는 뛰어나지만, 그에 상응하는 정교하고 긴 결과물을 생성하는 데는 뚜렷한 한계를 보이는 '이해-생성 비대칭성' 문제를 핵심적인 연구 격차로 지적하며, 이를 해결하는 것이 향후 중요한 과제임을 강조한다.
Reasoning or Memorization? Unreliable Results of Reinforcement Learning Due to Data Contamination
https://arxiv.org/abs/2507.10532
'추론인가 암기인가?' 논문은 강화학습(RL)이 LLM의 추론 능력을 향상시킨다는 최근 연구 결과들의 신뢰성에 의문을 제기한다. 연구진은 특정 모델에서 나타나는 성능 향상이 진정한 추론 능력의 발전이 아니라, 벤치마크 데이터가 사전 학습 데이터에 포함된 '데이터 오염'에 기인한 암기의 결과일 수 있다고 주장한다. 이를 입증하기 위해 데이터 유출이 원천적으로 불가능한 합성 데이터셋 'RandomCalculation'을 개발하여 실험한 결과, 오직 정확한 보상 신호만이 성능 향상에 기여함을 보였다. 따라서 이 연구는 신뢰할 수 있는 모델 평가를 위해 오염되지 않은 깨끗한 벤치마크를 사용할 것을 강력히 촉구한다.

Open Vision Reasoner: Transferring Linguistic Cognitive Behavior for Visual Reasoning
https://arxiv.org/abs/2507.05255
'Open Vision Reasoner'는 언어 모델의 고차원적 추론 능력을 멀티모달 모델에 전이시켜 시각적 추론 능력을 극대화하는 방법을 제시한다. 이 연구는 대규모 언어 데이터로 사전 학습을 진행한 뒤, 멀티모달 강화학습을 적용하는 2단계 훈련 패러다임을 제안했다. 그 결과, 언어 학습만으로도 '언어적 심상'을 통해 추론 행동이 시각 영역으로 전이될 수 있으며, 이후 강화학습이 효과적인 시각 패턴을 선별하고 강화하는 핵심적인 역할을 수행함을 발견했다. 이렇게 개발된 'OVR' 모델은 MATH500 등 여러 고난도 시각 추론 벤치마크에서 최고 수준의 성능을 달성했다.

NeuralOS: Towards Simulating Operating Systems via Neural Generative Models
https://arxiv.org/abs/2507.08800
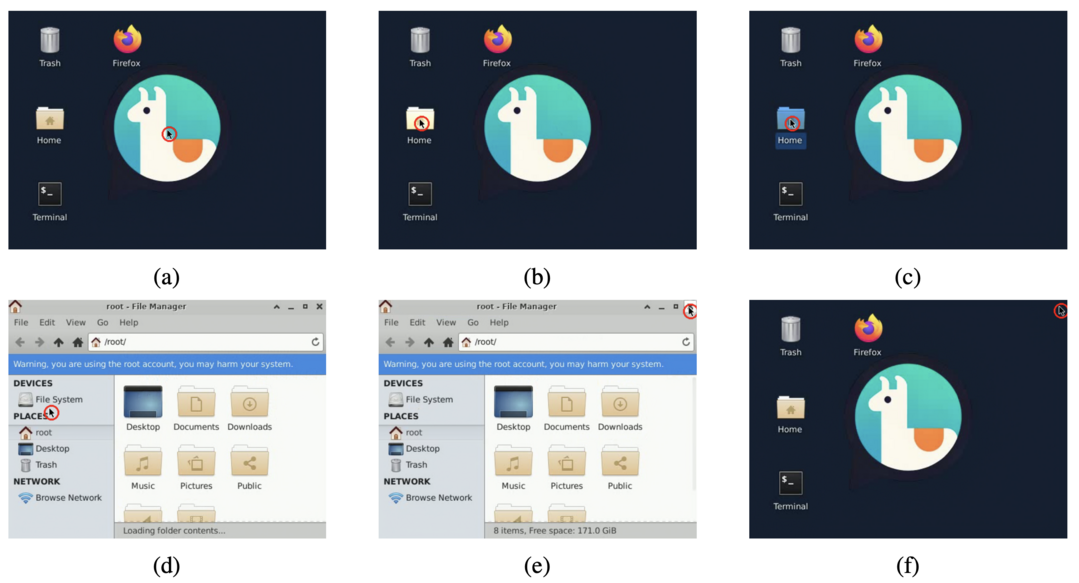
'NeuralOS'는 사용자의 마우스, 키보드 입력에 직접 반응하여 운영체제의 GUI 화면 프레임을 생성하는 신경망 프레임워크를 소개한다. 이 시스템은 컴퓨터의 내부 상태를 추적하는 순환 신경망(RNN)과 화면 이미지를 렌더링하는 확산 모델을 결합하여, 실제 OS와 유사하게 작동하는 시뮬레이터를 구현했다. 대규모 우분투 사용 기록 데이터셋으로 학습한 NeuralOS는 사실적인 GUI 시퀀스를 생성하고 마우스 상호작용 및 응용 프로그램 실행과 같은 상태 변화를 정확하게 예측하는 데 성공했지만, 정교한 키보드 입력 모델링은 향후 과제로 남겼다.
Towards Agentic RAG with Deep Reasoning: A Survey of RAG-Reasoning Systems in LLMs
https://arxiv.org/abs/2507.09477
'심층 추론을 통한 에이전트형 RAG를 향하여' 논문은 검색증강생성(RAG)의 사실성과 순수 추론의 장점을 결합하기 위한 통합적 관점을 제시하는 연구다. 기존 RAG는 다단계 추론에 취약하고, 순수 추론은 사실 왜곡을 일으키는 한계를 지닌다. 이 연구는 두 접근법을 통합하여, (1) 추론 능력이 RAG의 각 단계를 어떻게 강화하는지, (2) 검색된 지식이 복잡한 추론을 어떻게 돕는지를 분석한다. 나아가, 에이전트(agent)와 같은 LLM이 검색과 추론을 반복적으로 수행하며 지식 집약적 과제에서 최고 성능을 달성하는 '융합형 RAG-추론' 프레임워크를 핵심적인 발전 방향으로 조명한다. 이 논문은 관련 기술, 데이터셋, 그리고 향후 과제를 체계적으로 정리하며 더 효과적이고 신뢰성 높은 RAG-추론 시스템을 위한 연구 로드맵을 제공한다.
Vision Foundation Models as Effective Visual Tokenizers for Autoregressive Image Generation
https://arxiv.org/abs/2507.08441
이 연구는 이미지 '이해'를 위해 사전 학습된 강력한 비전 파운데이션 모델(VFM)을 이미지 '생성'을 위한 토크나이저로 활용하는 새로운 방향을 탐구한다. 제안된 'VFMTok'는 고정된 VFM을 인코더로 사용하면서, 중복 정보를 줄이는 '영역 적응형 양자화'와 의미 정보를 보존하는 '의미적 재구성' 목표를 도입하여 효율성을 높였다. 그 결과, VFMTok은 기존 방식보다 이미지 생성 품질과 토큰 효율을 크게 개선했으며, 특히 자기회귀(AR) 생성 모델의 학습 속도를 3배가량 가속하고 최고 수준의 성능을 달성하는 데 기여했다.

Mixture-of-Recursions: Learning Dynamic Recursive Depths for Adaptive Token-Level Computation
https://arxiv.org/abs/2507.10524
'재귀 혼합 모델(Mixture-of-Recursions, MoR)'은 LLM의 고비용 문제를 해결하기 위해 파라미터 재사용과 적응형 계산을 결합한 새로운 프레임워크다. MoR은 공유된 레이어 스택을 반복적으로 사용하여(파라미터 효율성) 모델 크기를 줄이는 동시에, 경량 라우터를 통해 각 토큰마다 재귀 깊이를 동적으로 할당하여 중요한 토큰에만 계산을 집중시킨다(적응형 계산). 이 접근법을 통해 MoR은 동일한 학습 연산량(FLOPs)으로 더 작은 모델 크기를 가지면서도 더 높은 성능과 처리량을 달성하며, 큰 모델의 품질을 적은 비용으로 얻을 수 있는 효율적인 경로를 제시한다.
CLiFT: Compressive Light-Field Tokens for Compute-Efficient and Adaptive Neural Rendering
https://arxiv.org/abs/2507.08776
'CLiFT' 논문은 3D 장면을 '압축된 라이트 필드 토큰(CLiFTs)'이라는 효율적인 단위로 표현하여 새로운 뷰를 렌더링하는 접근법을 제안한다. 이 방법은 여러 장의 이미지로부터 장면의 외형과 기하학 정보를 담은 압축 토큰을 생성하며, 핵심은 렌더링 시 사용할 토큰의 수를 계산 예산에 따라 유연하게 조절할 수 있다는 점이다. 이를 통해 CLiFT는 데이터 크기를 크게 줄이면서도 높은 품질의 렌더링을 유지하고, 사용자가 데이터 크기, 렌더링 품질, 속도 간의 상충 관계를 직접 선택할 수 있는 적응형 렌더링을 가능하게 한다.

[METAX = 김한얼 기자]
[저작권자ⓒ META-X. 무단전재-재배포 금지]