상호작용형 게임 월드와 3D 애니메이션까지 다양한 도메인의 AI 기술 발전
TL;DR
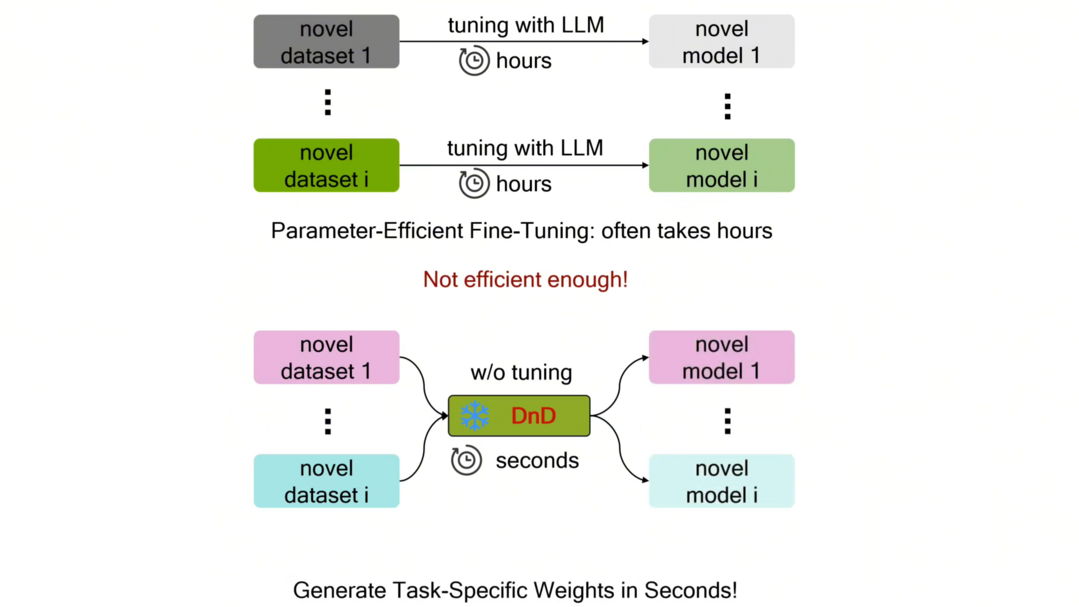
1. Drag-and-Drop LLMs: 개별 과제마다 파인튜닝하는 대신, 프롬프트만으로 모델의 가중치를 직접 생성하여 학습 비용을 획기적으로 줄인다.
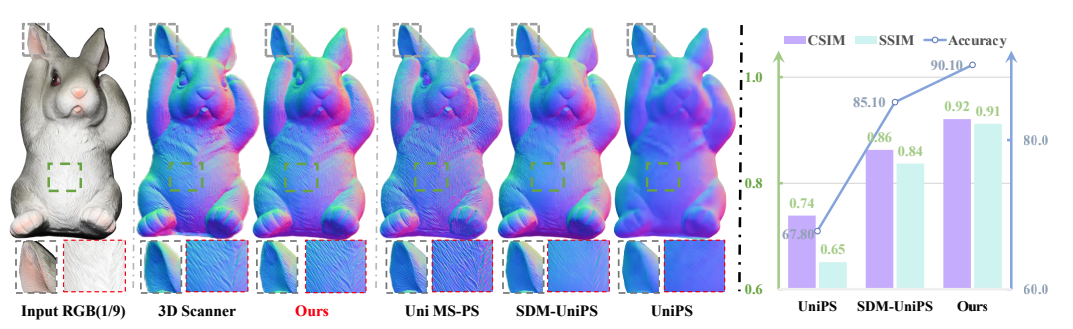
2. Light of Normals: 조명과 표면 형상 특징을 분리하는 통합된 표현 방식을 통해 임의의 조명 환경에서도 물체의 3차원 표면을 정확하게 복원한다.
3. Vision-Guided Chunking Is All You Need: 대규모 멀티모달 모델을 이용해 문서의 시각적 구조까지 이해하며 분할함으로써 RAG 시스템의 정확도를 향상시킨다.
4. OmniGen2: 텍스트와 이미지에 대한 디코딩 경로를 분리한 다목적 생성 모델로, 텍스트-이미지 변환 및 편집 등 다양한 작업을 하나의 모델로 처리한다.
5. ShareGPT-4o-Image: GPT-4o의 이미지 생성 능력을 모방한 대규모 데이터셋을 구축 및 공개하여 고품질 이미지 생성 기술의 대중화를 이끈다.
6. JarvisArt: 사용자의 의도를 파악하고 전문가용 사진 편집 도구를 직접 제어하여 지능적인 사진 보정 작업을 수행하는 멀티모달 에이전트이다.
7. PAROAttention: 어텐션 패턴을 하드웨어 친화적으로 재배열하여, 시각 생성 모델의 품질 저하 없이 계산 효율과 속도를 크게 향상시킨다.
8. Matrix-Game: 방대한 게임 플레이 데이터로 학습하여, 사용자의 행동에 실시간으로 반응하는 고품질의 상호작용형 게임 세계를 생성하는 파운데이션 모델이다.
9. AnimaX: 비디오의 움직임 정보를 3D 포즈에 접목하는 확산 모델을 통해, 어떤 뼈대 구조를 가진 3D 캐릭터라도 자연스럽게 애니메이션화한다.
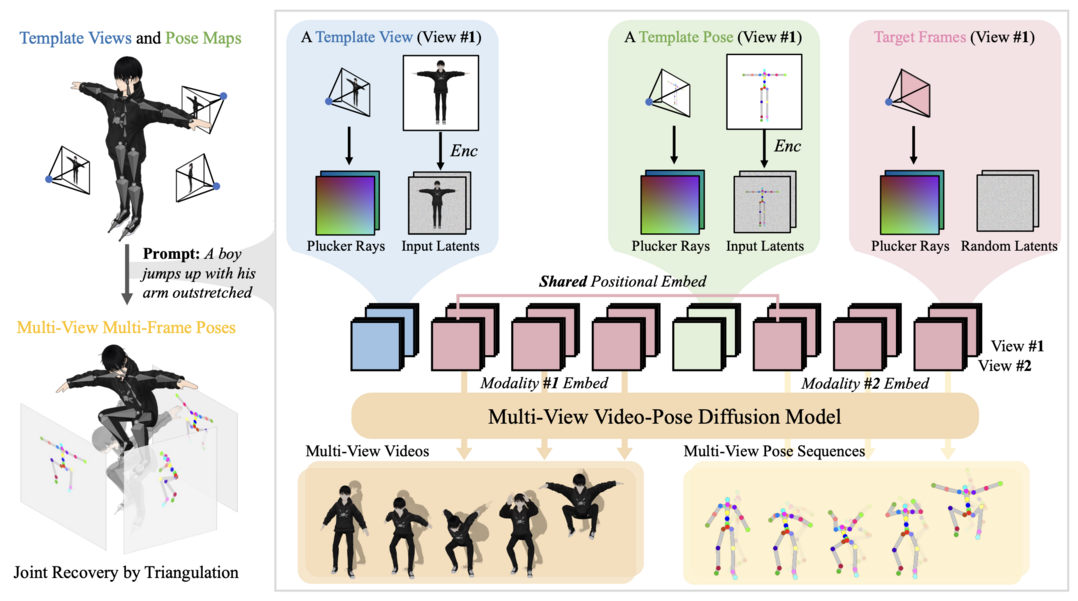
10. LongWriter-Zero: 별도의 데이터 없이 강화학습만을 이용해 언어 모델이 스스로 초장문의 고품질 텍스트를 생성하도록 학습시킨다.
Drag-and-Drop LLMs: Zero-Shot Prompt-to-Weights
https://arxiv.org/abs/2506.16406
개별 작업마다 별도의 최적화 과정 없이 프롬프트만으로 대규모 언어 모델의 가중치를 직접 생성하는 새로운 패러다임을 제안한다. 이 기술은 텍스트 인코더로 프롬프트를 조건 임베딩으로 변환하고, 이를 디코더가 LoRA 행렬로 바꾸어 모델을 업데이트한다. 이를 통해 기존 파인튜닝보다 오버헤드를 최대 12,000배 낮추고, 처음 접하는 벤치마크에서도 평균 30% 높은 성능 향상을 달성하며 강력한 일반화 성능을 입증한다.
Light of Normals: Unified Feature Representation for Universal Photometric Stereo
https://arxiv.org/abs/2506.18882
임의의 조명 아래에서 객체의 표면 정보를 복원하는 '보편적 광도 스테레오' 기술의 근본적인 문제를 다룬다. 기존 기술은 조명 변화와 표면 형상의 특징이 뒤섞이고 미세한 기하학적 디테일을 놓치는 한계가 있었다. 이 연구는 조명과 표면 법선을 분리하는 통합된 특징 표현을 학습하여, 조명 변화에 강인하고 복잡한 표면 구조까지 정확하게 복원하는 것을 목표로 한다.
Vision-Guided Chunking Is All You Need: Enhancing RAG with Multimodal Document Understanding
https://arxiv.org/abs/2506.16035
기존 RAG(Retrieval-Augmented Generation) 시스템의 한계를 지적한다. 텍스트 기반 문서 분할 방식은 여러 페이지에 걸친 표나 이미지, 문맥적 연결성을 제대로 처리하지 못한다. 이에 대한 해결책으로, 대규모 멀티모달 모델(LMM)을 활용해 문서의 시각적 구조와 텍스트 의미를 동시에 이해하는 '비전 가이드 분할' 방식을 제시한다. 이 접근법은 여러 페이지의 표나 이미지도 정확히 처리하며, 기존 RAG 시스템보다 높은 정확도와 의미적 일관성을 보인다.
OmniGen2: Exploration to Advanced Multimodal Generation
https://arxiv.org/abs/2506.18871
텍스트-이미지 변환, 이미지 편집 등 다양한 생성 작업을 하나의 모델로 처리하는 다목적 생성 모델이다. 이 모델의 핵심 특징은 텍스트와 이미지에 대해 분리된 디코딩 경로를 사용한다는 점이다. 이를 통해 기존 멀티모달 모델의 텍스트 생성 능력은 보존하면서 이미지 생성 기능을 효과적으로 통합했다. OmniGen2는 여러 벤치마크에서 경쟁력 있는 성능을 달성했으며, 특히 이미지 일관성을 평가하는 새로운 벤치마크 'OmniContext'를 자체적으로 제안하고 최고 수준의 성능을 기록했다.

ShareGPT-4o-Image: Aligning Multimodal Models with GPT-4o-Level Image Generation
https://arxiv.org/abs/2506.18095
비공개 모델인 GPT-4o의 뛰어난 이미지 생성 능력을 오픈소스 커뮤니티에 확산시키는 것을 목표로 한다. 이를 위해 GPT-4o로 생성한 9만여 개의 이미지 데이터셋 'ShareGPT-4o-Image'를 구축하고 공개했다. 이 데이터셋을 기반으로 'Janus-4o'라는 멀티모달 모델을 개발했으며, 이 모델은 단 6시간의 짧은 학습만으로 텍스트-이미지 변환 및 텍스트와 이미지를 모두 활용한 이미지 생성 작업에서 인상적인 성능을 달성했다.

JarvisArt: Liberating Human Artistic Creativity via an Intelligent Photo Retouching Agent
https://arxiv.org/abs/2506.17612
전문가용 사진 편집 도구의 복잡성과 기존 AI 자동화 도구의 한계 사이의 간극을 메우는 것을 목표로 한다. 이 연구는 사용자의 의도를 이해하고 전문가처럼 추론하며, 200개 이상의 Lightroom 도구를 지능적으로 제어하는 멀티모달 에이전트 'JarvisArt'를 개발했다. 2단계 학습 과정을 통해 추론 및 도구 사용 능력을 강화했으며, 자체 개발한 벤치마크에서 GPT-4o보다 픽셀 수준 정확도가 60% 향상되는 등 뛰어난 성능과 사용자 친화적인 상호작용을 입증하며 지능형 사진 편집의 새로운 방향을 제시한다.

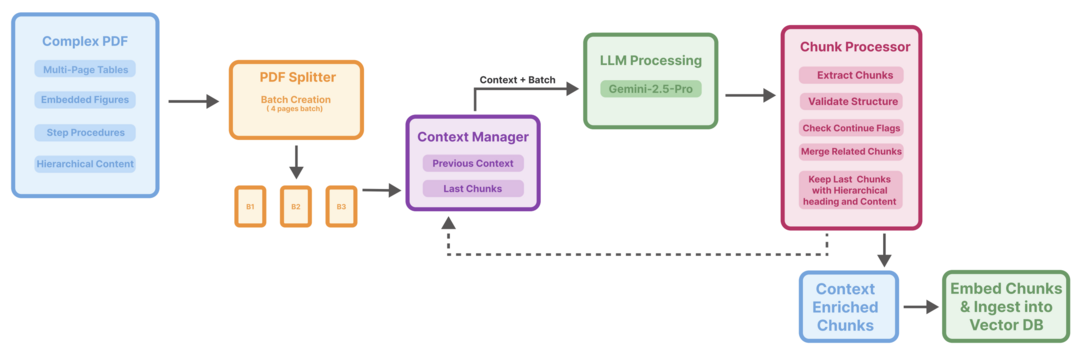
PAROAttention: Pattern-Aware ReOrdering for Efficient Sparse and Quantized Attention in Visual Generation Models
https://arxiv.org/abs/2506.16054
시각 생성 모델에서 어텐션 메커니즘이 유발하는 막대한 메모리 및 계산 비용 문제를 해결한다. 이 연구는 복잡한 어텐션 패턴에 맞는 알고리즘을 개발하는 대신, 토큰의 순서를 재배열하여 어텐션 패턴 자체를 하드웨어에 친화적인 형태로 단순화하는 'PARO' 기술을 제안한다. 이 접근법을 통해 어텐션 밀도와 비트 폭을 크게 낮추면서도 원본과 거의 동일한 품질의 결과물을 생성하며, 전체 지연 시간을 최대 2.7배까지 단축시키는 데 성공했다.
Matrix-Game: Interactive World Foundation Model
https://arxiv.org/abs/2506.18701
사용자가 직접 제어 가능한 게임 세계를 생성하는 상호작용형 월드 파운데이션 모델이다. 이 모델은 2,700시간이 넘는 방대한 마인크래프트 게임 플레이 데이터셋을 기반으로 학습했다. 사용자의 키보드 및 마우스 조작에 따라 캐릭터의 행동과 카메라 움직임을 정밀하게 제어하면서 고품질의 일관된 영상을 생성하는 것이 특징이다. 자체 개발한 벤치마크에서 기존 오픈소스 모델들을 모든 지표에서 능가했으며, 특히 제어 가능성과 물리적 일관성 측면에서 강력한 성능을 보인다.

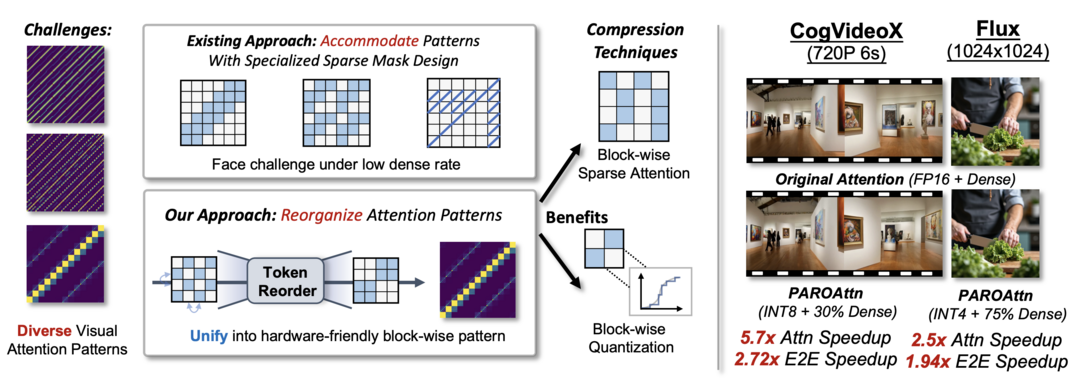
AnimaX: Animating the Inanimate in 3D with Joint Video-Pose Diffusion Models
https://arxiv.org/abs/2506.19851
고정된 뼈대 구조에 제약되거나 최적화 비용이 높았던 기존 3D 애니메이션 기술의 한계를 극복한다. 이 연구는 비디오 확산 모델의 풍부한 움직임 지식과 뼈대 기반 애니메이션의 정밀한 제어 가능성을 결합한 'AnimaX' 프레임워크를 제시한다. 3D 모션을 여러 시점의 2D 포즈 맵으로 변환하고, 비디오와 포즈를 함께 생성하는 모델을 학습시켜 임의의 뼈대를 가진 다양한 3D 모델에 생동감 있는 움직임을 적용한다. 이를 통해 여러 벤치마크에서 일반화, 움직임 충실도, 효율성 모두 최고 수준의 성능을 달성했다.
LongWriter-Zero: Mastering Ultra-Long Text Generation via Reinforcement Learning
https://arxiv.org/abs/2506.18841
대규모 언어 모델(LLM)이 겪는 초장문 생성의 어려움을 해결하기 위해 제안되었다. 기존 방식이 비용이 많이 들고 부자연스러운 인공 데이터에 의존했던 것과 달리, 이 연구는 강화학습을 통해 LLM이 데이터 없이 스스로 고품질의 긴 글을 생성하도록 유도한다. 기본 모델에서 시작하여 글의 계획 및 수정 능력을 강화학습으로 길러내며, 길이 제어, 품질, 구조 등을 위한 특수 보상 모델을 활용한다. 그 결과, 주요 벤치마크에서 기존 방식이나 훨씬 더 큰 규모의 모델을 능가하는 최고 수준의 성능을 기록했다.
[METAX = 김한얼 기자]
[저작권자ⓒ META-X. 무단전재-재배포 금지]