데스크톱 데이터 전이와 공간 강제를 통한 로봇 AI의 진화, 그리고 멀티 에이전트 평가 체계 구축
QeRL: Beyond Efficiency -- Quantization-enhanced Reinforcement Learning for LLMs
https://arxiv.org/pdf/2510.11696
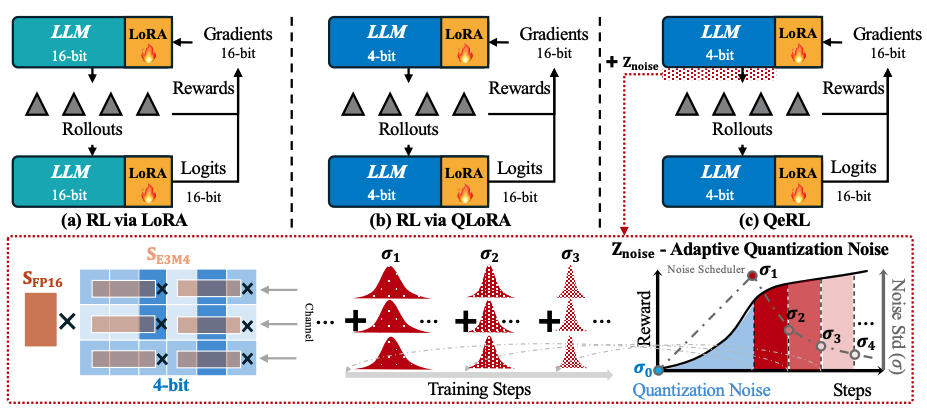
QeRL은 대규모 언어 모델(LLM)의 강화학습(RL)이 요구하는 막대한 자원 문제를 해결하기 위해 NVFP4 양자화와 LoRA를 결합한 프레임워크다. 이 방식은 RL의 롤아웃 단계를 1.5배 이상 가속하고 메모리 오버헤드를 줄일 뿐만 아니라, 양자화 과정에서 발생하는 노이즈를 활용해 정책 엔트로피를 높여 모델의 탐험 능력을 강화한다. 적응형 양자화 노이즈(AQN) 메커니즘으로 탐험을 최적화하며, 단일 H100 GPU에서 32B 모델의 RL 훈련을 최초로 가능하게 했고, 주요 수학 벤치마크에서 전체 파라미터 미세조정과 동등한 성능을 달성함으로써 효율성과 효과성을 모두 입증했다.
Diffusion Transformers with Representation Autoencoders
https://arxiv.org/abs/2510.11690
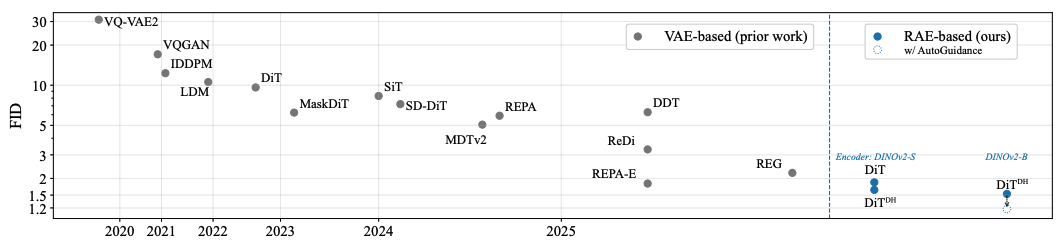
이 논문은 디퓨전 트랜스포머(DiT)의 이미지 생성 성능을 높이기 위해 기존의 VAE 오토인코더를 의미적으로 풍부한 표현을 학습하는 표현 오토인코더(RAE)로 대체하는 방법을 제안한다. RAE는 DINO와 같은 사전 훈련된 표현 인코더와 훈련된 디코더를 결합하여 고품질의 이미지 복원과 풍부한 잠재 공간을 제공하며, 고차원 잠재 공간에서 발생하는 어려움을 이론에 기반한 해결책으로 극복했다. 그 결과, 보조적인 손실 함수 없이도 더 빠른 수렴을 달성하고 ImageNet 벤치마크에서 최고 수준의 FID 점수를 기록함으로써 RAE가 DiT 훈련의 새로운 표준이 되어야 함을 주장한다.
Spatial Forcing: Implicit Spatial Representation Alignment for Vision-language-action Model
https://arxiv.org/abs/2510.12276
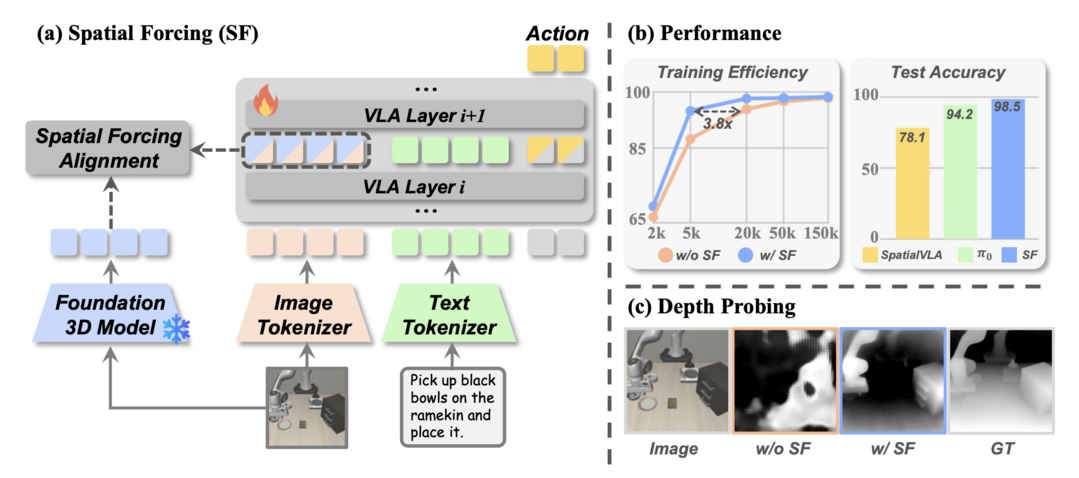
공간 강제(SF)는 시각-언어-행동(VLA) 모델이 깊이 맵과 같은 명시적인 3D 데이터 없이도 3D 공간 이해 능력을 갖추도록 하는 새로운 정렬 전략이다. 이 방법은 VLA 모델의 중간 시각 임베딩을 사전 훈련된 3D 파운데이션 모델의 기하학적 표현과 정렬시켜, 모델이 행동 정밀도를 높이는 데 필요한 풍부한 공간 정보를 암시적으로 인코딩하도록 유도한다. 시뮬레이션 및 실제 로봇 실험에서 SF는 기존 2D 및 3D 기반 모델들을 능가하는 최고 성능을 달성했으며, 훈련 속도를 최대 3.8배 가속하고 데이터 효율성을 개선하는 효과를 보였다.
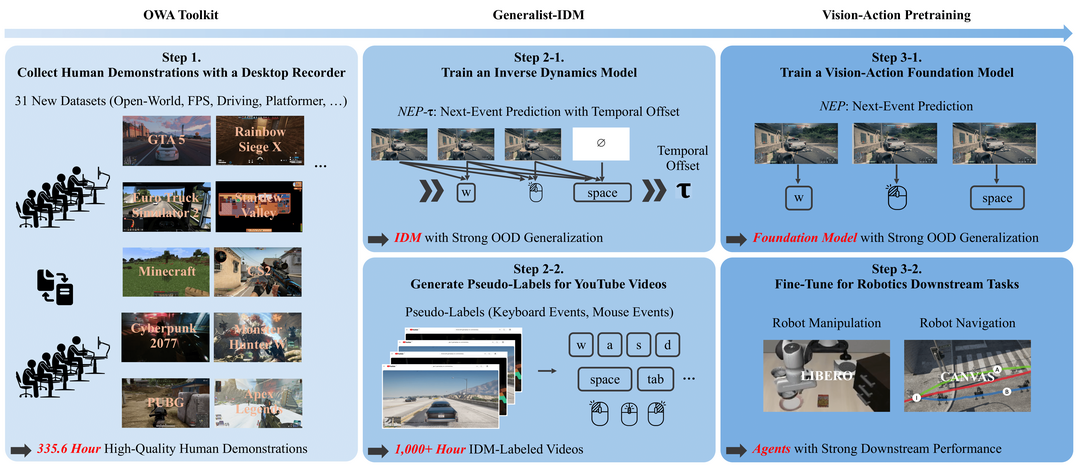
D2E: Scaling Vision-Action Pretraining on Desktop Data for Transfer to Embodied AI
https://arxiv.org/pdf/2510.05684
D2E는 실제 로봇 데이터 수집의 높은 비용 문제를 해결하기 위해, 게임과 같은 데스크톱 환경의 상호작용 데이터를 로봇 AI 사전 훈련에 활용하는 프레임워크다. 이 프레임워크는 다양한 데스크톱 데이터를 표준화하고 압축하는 OWA 툴킷, 처음 보는 게임에서도 일반화 성능이 뛰어난 Generalist-IDM, 그리고 데스크톱에서 학습된 표현을 실제 로봇 조작 및 탐색 작업으로 전이시키는 VAPT로 구성된다. 1,300시간 이상의 데스크톱 데이터를 활용한 실험에서 높은 성공률을 기록하며, 디지털 환경의 감각-운동 능력이 물리적 로봇 작업으로 의미 있게 전이될 수 있음을 입증했다.
Thinking with Camera: A Unified Multimodal Model for Camera-Centric Understanding and Generation
https://arxiv.org/abs/2510.08673
Puffin은 공간 지능의 핵심인 카메라 중심의 이해와 생성을 하나의 모델로 통합하여, 임의의 시점에서 장면을 해석하고 생성하는 통합 멀티모달 모델이다. 이 모델은 '카메라를 언어처럼 취급'하는 새로운 패러다임을 도입하여, 공간적 시각 단서와 사진 용어를 정렬하고 기하학적 맥락을 추론하게 한다. 4백만 개의 시각-언어-카메라 데이터셋으로 훈련된 Puffin은 전문화된 기존 모델들보다 뛰어난 성능을 보이며, 공간적 상상이나 사진 촬영 가이던스와 같은 다양한 교차 시점 작업으로 일반화될 수 있는 잠재력을 보여주었다.

Advancing End-to-End Pixel Space Generative Modeling via Self-supervised Pre-training
https://arxiv.org/abs/2510.12586
이 논문은 훈련이 어렵고 성능이 낮았던 픽셀 공간 생성 모델과 잠재 공간 모델 간의 격차를 해소하는 새로운 2단계 훈련 프레임워크를 제안한다. 1단계에서 인코더를 자기지도 방식으로 사전 훈련하여 이미지의 의미 있는 정보를 포착하게 하고, 2단계에서 이 인코더를 디코더와 결합하여 전체 모델을 미세 조정한다. 이 접근법을 통해 ImageNet에서 기존 픽셀 공간 모델을 압도하는 생성 품질과 효율성을 달성했으며, 특히 사전 훈련된 VAE 없이 고해상도 이미지에서 직접 일관성 모델을 성공적으로 훈련한 최초의 성과를 거두었다.
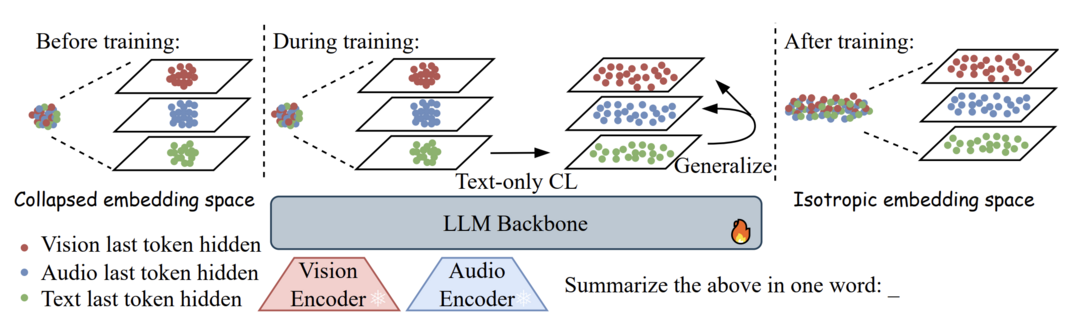
Scaling Language-Centric Omnimodal Representation Learning
https://arxiv.org/abs/2510.11693
이 연구는 멀티모달 대규모 언어 모델(MLLM) 기반 임베딩의 우수성이 생성적 사전 훈련 단계에서 이미 달성된 '암묵적 교차 모달 정렬' 덕분이라고 주장하며, 이를 바탕으로 언어 중심 옴니모달 임베딩(LCO-Emb) 프레임워크를 제안한다. 또한, 모델의 생성 능력이 향상될수록 표현 능력도 함께 향상된다는 '생성-표현 스케일링 법칙(GRSL)'을 발견하고 이론적으로 증명했다. LCO-Emb는 다양한 벤치마크에서 최고 수준의 성능을 달성했으며, 이를 통해 생성 능력 향상이 표현의 질을 높이는 효과적인 패러다임임을 입증했다.
Robot Learning: A Tutorial
https://arxiv.org/abs/2510.12403
이 문서는 현대 로봇 학습 분야의 지형도를 제시하는 튜토리얼로, 머신러닝의 발전으로 인해 고전적인 모델 기반 방식에서 데이터 기반 학습 패러다임으로 전환되는 흐름을 다룬다. 강화학습과 행동 복제 같은 기초 원리부터 다양한 작업과 환경에 적용 가능한 일반화된 언어 조건 모델까지 폭넓은 주제를 아우른다. 이 튜토리얼은 연구자와 실무자들이 로봇 학습 분야에 기여하는 데 필요한 개념적 이해와 함께, lerobot 라이브러리를 통해 구현된 실용적인 예제를 제공하는 것을 목표로 한다.
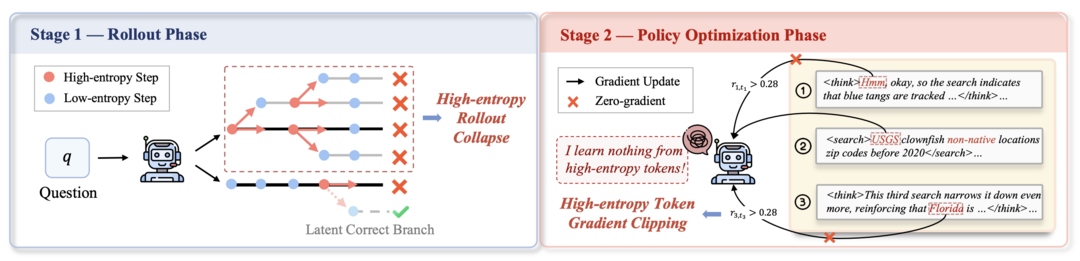
Agentic Entropy-Balanced Policy Optimization
https://arxiv.org/abs/2510.14545
AEPO는 웹 에이전트의 강화학습 시 엔트로피 신호에 과도하게 의존하여 발생하는 훈련 붕괴 문제를 해결하기 위해 제안된 새로운 최적화 알고리즘이다. 이 알고리즘은 롤아웃 단계에서 엔트로피를 사전 모니터링하여 샘플링 예산을 동적으로 할당하고, 정책 업데이트 단계에서는 엔트로피가 높은 토큰의 그래디언트를 보존 및 재조정하여 학습의 안정성을 높인다. 14개의 어려운 웹 에이전트 데이터셋에서 기존 7개의 주류 강화학습 알고리즘을 일관되게 능가하는 성능을 보이며, 적은 샘플만으로도 높은 성공률을 달성하는 확장성을 입증했다.
FlashWorld: High-quality 3D Scene Generation within Seconds
https://arxiv.org/abs/2510.13678
FlashWorld는 단일 이미지나 텍스트로부터 단 몇 초 만에 3D 장면을 생성하는 모델로, 기존 방식보다 10배에서 100배 빠르면서도 우수한 렌더링 품질을 자랑한다. 이 모델은 다중 시점 이미지를 생성하며 동시에 3D 가우시안 표현을 직접 생성하는 3D 지향 방식을 사용하되, 고품질 다중 시점 모드의 결과 분포를 3D 지향 모드에 증류하는 '교차 모드 후처리 훈련'을 통해 시각적 품질 저하 문제를 해결했다. 그 결과, 3D 일관성을 유지하면서도 빠른 속도와 높은 품질을 모두 달성하는 데 성공했다.

[METAX = 김한얼 기자]
[저작권자ⓒ META-X. 무단전재-재배포 금지]